GMP库生成素数用啥算法,要说具体点,demos里面的那个primes.c的算法也是一样的么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GMP库生成素数用啥算法,要说具体点,demos里面的那个primes.c的算法也是一样的么?相关的知识,希望对你有一定的参考价值。
谢谢各位了,在线等。
参考技术A primes.c的find_primes函数调用了GMP的mpz_probab_prime_p:if (mpz_cmp (tmp, siev_sqr_lim) < 0 ||
mpz_probab_prime_p (tmp, 10))
report (tmp);
而mpz_probab_prime_p用到了 Miller-Rabin 算法。
GMP有两个素数函数 mpz_probab_prime_p 和 mpz_nextprime, 代码都在mpz目录下:
pprime_p.c
millerrabin.c
nextprime.c
简介:
-- Function: int mpz_probab_prime_p (mpz_t N, int REPS)
Determine whether N is prime. Return 2 if N is definitely prime,
return 1 if N is probably prime (without being certain), or return
0 if N is definitely composite.
This function does some trial divisions, then some Miller-Rabin
probabilistic primality tests. REPS controls how many such tests
are done, 5 to 10 is a reasonable number, more will reduce the
chances of a composite being returned as "probably prime".
Miller-Rabin and similar tests can be more properly called
compositeness tests. Numbers which fail are known to be composite
but those which pass might be prime or might be composite. Only a
few composites pass, hence those which pass are considered
probably prime.
-- Function: void mpz_nextprime (mpz_t ROP, mpz_t OP)
Set ROP to the next prime greater than OP.
This function uses a probabilistic algorithm to identify primes.
For practical purposes it's adequate, the chance of a composite
passing will be extremely small.本回答被提问者采纳
Bag of Features (BOF)图像检索算法
1.首先,我们用surf算法生成图像库中每幅图的特征点及描述符。
2.再用k-means算法对图像库中的特征点进行训练,生成类心。
3.生成每幅图像的BOF,具体方法为:判断图像的每个特征点与哪个类心最近,最近则放入该类心,最后将生成一列频数表,即初步的无权BOF。
4.通过tf-idf对频数表加上权重,生成最终的bof。(因为每个类心对图像的影响不同。比如超市里条形码中的第一位总是6,它对辨别产品毫无作用,因此权重要减小)。
5.对query进来的图像也进行3.4步操作,生成一列query图的BOF。
6.将query的Bof向量与图像库中每幅图的Bof向量求夹角,夹角最小的即为匹配对象。
图像检索中应用LSH实现快速搜索,其在一定概率的保证下解决了高维特征查询的问题,但笔者在应用LSH结合SIFT特征实践图像检索实验时,由于每张图像涉及上百个特征,那么在查询一张图片时,需要进行上而次的特征查询,即便是将查询图片的特征点数筛选至50%的量,一次图片查询需要进行的特征查询次数亦不容小窥。那么有没有方法可以将任意图片的所有特征向量用一个固定维数的向量表出,且这个维数并不因图片特征点数不同而变化?本篇要讲到的方法可以解决这个问题,尽管它并不是因这个问题而生的。

Bag-of-Words模型源于文本分类技术,在信息检索中,它假定对于一个文本,忽略其词序和语法、句法。将其仅仅看作是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说这篇文章的作者在任意一个位置选择词汇都不受前面句子的影响而独立选择的。

图像可以视为一种文档对象,图像中不同的局部区域或其特征可看做构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,就能够把文本检索及分类的方法用到图像分类及检索中去。
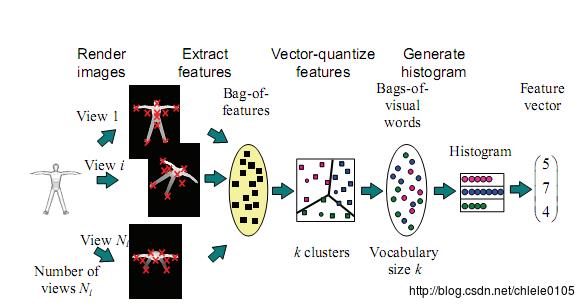
Accelerating Bag-of-Features SIFT Algorithm for 3D Model Retrieval
Bag-of-Features模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
https://img-blog.csdn.net/20131002212031828?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvY2hsZWxlMDEwNQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center
Bag of Features Codebook Generation by Self-Organisation
Bag-of-Features更多地是用于图像分类或对象识别。在上述思路下对训练集提取Bag-of-Features特征,在某种监督学习(如:SVM)的策略下,对训练集的Bag-of-Features特征向量进行训练,获得对象或场景的分类模型;对于待测图像,提取局部特征,计算局部特征与词典中每个码字的特征距离,选取最近距离的码字代表该特征,建立一个统计直方图,统计属于每个码字的特征个数,即为待测图像之Bag-of-Features特征;在分类模型下,对该特征进行预测从实现对待测图像的分类。
Classification Process
1、局部特征提取:通过分割、密集或随机采集、关键点或稳定区域、显著区域等方式使图像形成不同的patches,并获得各patches处的特征。
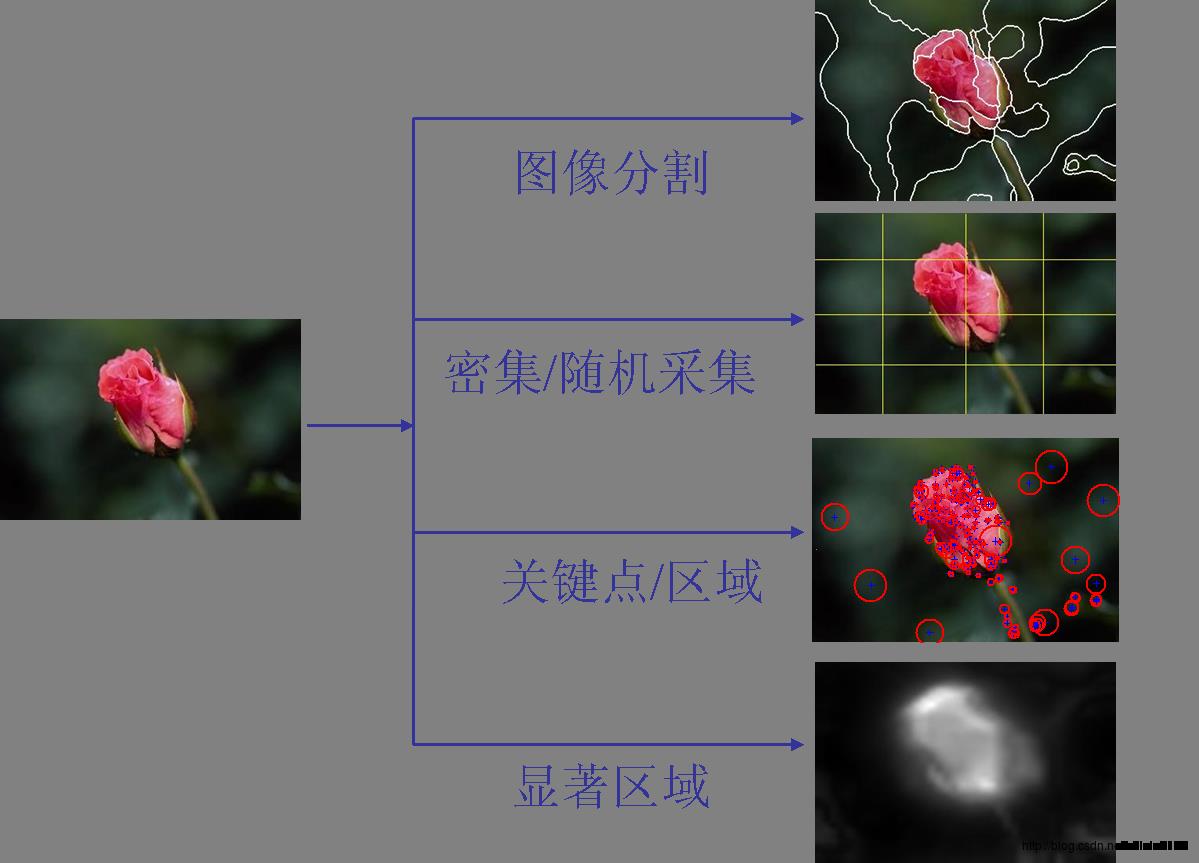
其中,SIFT特征较为流行。

2、构建视觉词典:
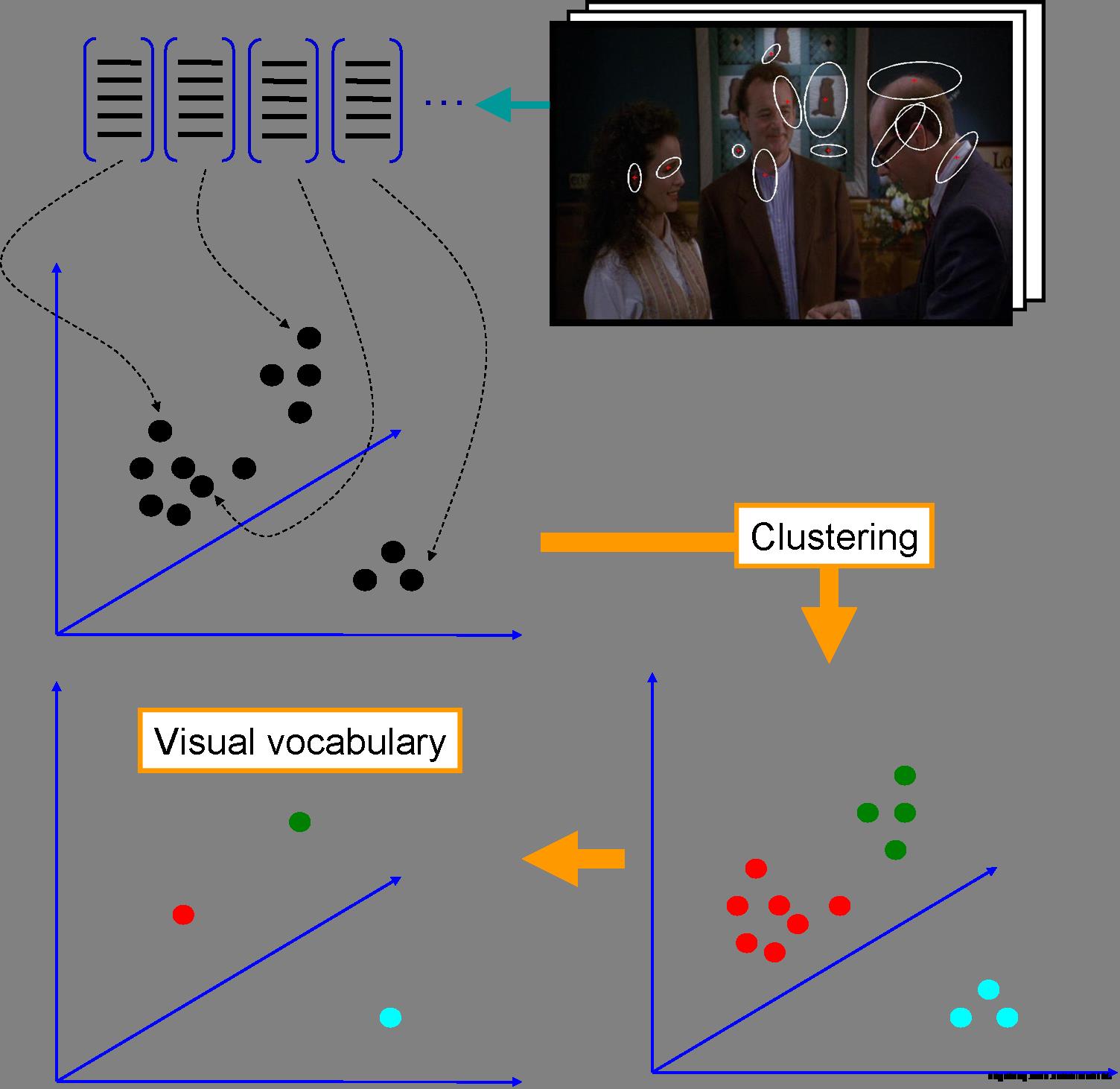
由聚类中心代表的视觉词汇形成视觉词典:

3、生成码书,即构造Bag-of-Features特征,也即局部特征投影过程:
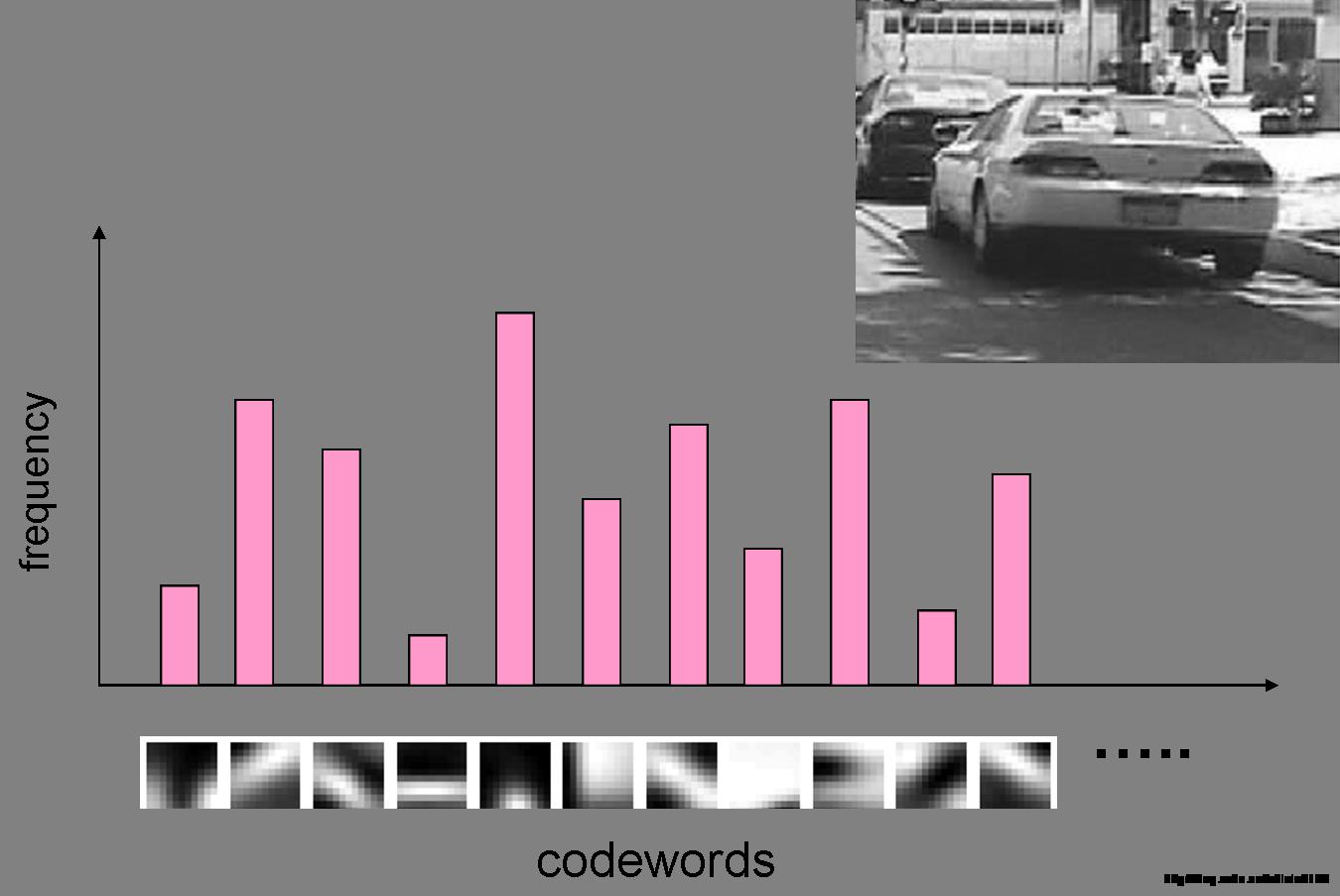
4、SVM训练BOF特征得分类模型,对待测图像BOF特征预测:
Retrieval Process
Bag-of-words在CV中的应用首先出现在Andrew Zisserman[6]中为解决对视频场景的搜索,其提出了使用Bag-of-words关键点投影的方法来表示图像信息。后续更多的研究者归结此方法为Bag-of-Features,并用于图像分类、目标识别和图像检索。在Bag-of-Features方法的基础上,Andrew Zisserman进一步借鉴文本检索中TF-IDF模型(Term Frequency一Inverse Document Frequency)来计算Bag-of-Features特征向量。接下来便可以使用文本搜索引擎中的反向索引技术对图像建立索引,高效的进行图像检索。
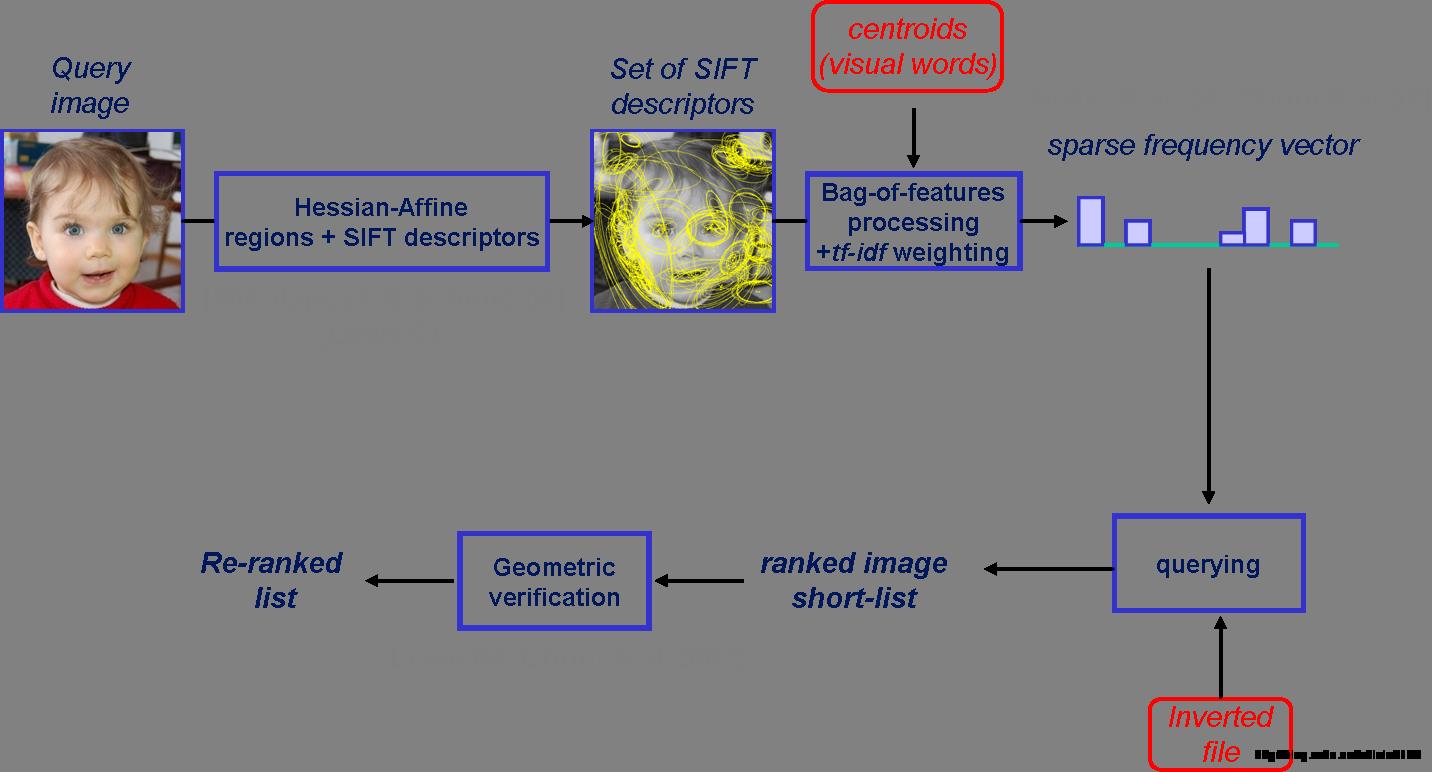
Hamming embedding and weak geometric consistency for large scale image search
实现检索的过程同分类的过程无本质的差异,更多的是细节处理上的差异:
1、局部特征提取;
2、构建视觉词典;
3、生成原始BOF特征;
4、引入TF-IDF权值:
TF-IDF是一种用于信息检索的常用加权技术,在文本检索中,用以评估词语对于一个文件数据库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的频率成正比增加,但同时会随着它在文件数据库中出现的频率成反比下降。TF的主要思想是:如果某个关键词在一篇文章中出现的频率高,说明该词语能够表征文章的内容,该关键词在其它文章中很少出现,则认为此词语具有很好的类别区分度,对分类有很大的贡献。IDF的主要思想是:如果文件数据库中包含词语A的文件越少,则IDF越大,则说明词语A具有很好的类别区分能力。
词频(Term Frequency,TF)指的是一个给定的词语在该文件中出现的次数。如:tf = 0.030 ( 3/100 )表示在包括100个词语的文档中, 词语’A’出现了3次。
逆文档频率(Inverse Document Frequency,IDF)是描述了某一个特定词语的普遍重要性,如果某词语在许多文档中都出现过,表明它对文档的区分力不强,则赋予较小的权重;反之亦然。如:idf = 13.287 ( log (10,000,000/1,000) )表示在总的10,000,000个文档中,有1,000个包含词语’A’。
最终的TF-IDF权值为词频与逆文档频率的乘积。
5、对查询图像生成同样的带权BOF特征;
6、查询:初步是通过余弦距离衡量,至于建立索引的方法还未学习到,望看客指点。
Issues
1、使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。有方法是在海量图片中抽取部分训练集分类,使用朴素贝叶斯分类的方法对图库中其余图片进行自动分类。另外,由于图片爬虫在不断更新后台图像集,重新聚类的代价显而易见。
2、字典大小的选择也是问题,字典过大,单词缺乏一般性,对噪声敏感,计算量大,关键是图象投影后的维数高;字典太小,单词区分性能差,对相似的目标特征无法表示。
3、相似性测度函数用来将图象特征分类到单词本的对应单词上,其涉及线型核,塌方距离测度核,直方图交叉核等的选择。
4、将图像表示成一个无序局部特征集的特征包方法,丢掉了所有的关于空间特征布局的信息,在描述性上具有一定的有限性。为此, Schmid[2]提出了基于空间金字塔的Bag-of-Features。
5、Jégou[7]提出VLAD(vector of locally aggregated descriptors),其方法是如同BOF先建立出含有k个visual word的codebook,而不同于BOF将一个local descriptor用NN分类到最近的visual word中,VLAD所采用的是计算出local descriptor和每个visual word(ci)在每个分量上的差距,将每个分量的差距形成一个新的向量来代表图片。
Resources
Two bag-of-words classifiers(Matlab)
Bag of Words/Bag of Features的Matlab源码
一个用BoW|Pyramid BoW+SVM进行图像分类的Matlab Demo
以上是关于GMP库生成素数用啥算法,要说具体点,demos里面的那个primes.c的算法也是一样的么?的主要内容,如果未能解决你的问题,请参考以下文章