「如何设计」具备幂等性的服务
Posted 猿人课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「如何设计」具备幂等性的服务相关的知识,希望对你有一定的参考价值。
幂等的目的
为何会存在需要服务的幂等,在互联网中由于网络的不稳定和一些业务重复确认设计,对一个接口的调用存在重试的机制,为了确保执行同一个请求执行一次和执行多次的效果是一样的,所以就存在了幂等的设计。 举个例子,如果在转账的交易中,A给B进行一笔转账,如果没有幂等性,很可能就因为各种原因导致了A给B进行了多笔转账,在银行系统中,这个就是重大的灾难。
幂等的定义
服务的幂等可能划分为2个层面,一个是从接口的请求层面,一个是从业务层面考虑。
请求层面:
从请求层面考虑,就是一个接口得保证请求一个和请求多次得到的效果是一致的。 如果用数据表达式是这样的
f...f(f(x)) = f(x)
x是参数
f是执行函数
复制代码把相同的参数传给执行函数,不管执行了多少次,结果是一致的。
业务层面:
从业务角度出来
例如一个用户在一次购买中不能重复下单
例如库存剩下了1个商品,现在有10个人抢购,怎么保证不超卖
例如在MQ的生产者是不需要保证幂等,很可能把同一条消息发送多次,需要保证MQ消费端去重,MQ消费者保证这批消息只会执行一个。
导致非幂等原因
先了解下为何会出现不幂等的原因,因为retry重试,如果取消retry机制,是否就能杜绝不幂等呢,答应应该是肯定的,但取消retry是否现实,我们来看看究竟在什么场合会出现retry
用户进行下订单,调用下单接口超时,调用方又发起一次创建下单接口。
用户下单进行扣减库存,调用扣减库存接口超时了,调用方又发起一次扣减库存接口。
下单完毕后,生产者发送一条MQ,MQ超时没有及时响应ACK,生产者又再发送一条MQ,消费者连续就收到了两条MQ
从整个系统或业务层面其实很难去做到去retry,所以在一些接口的幂等性还是需要我们自己来做。
幂等作用范围
读/写请求层面范围幂等
读没有造成数据的改变,只有写请求才会造成数据改变。
架构层面范围幂等
究竟在哪些层会造成数据的改变
反向代理?网关?业务逻辑?数据访问?
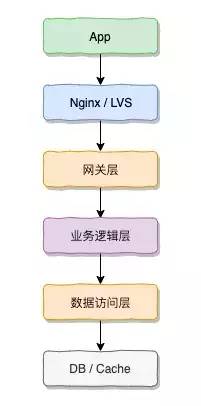
从架构层面出发,哪些层会对数据造成改变,只有造成数据改变的层才需要做出幂等,很显然,数据访问层直接操作DB和Cache (业务逻辑层也可能访问操作cache),从请求层面来看,我们需要对数据访问层进行幂等操作。
数据访问层哪些操作需要幂等
从数据层面出发,数据访问层 也就提供了 CRUD 四个请求层面,先站在数据层出发,看看是否可以对数据访问层进行一定改造让数据访问层达到幂等性
Create / Select 操作

insert into user (name,pm) values ('petty',18)
复制代码由于user表的主键是自增ID,所以每次插入都会新增一条,可以考虑进行改造,让prikey程序实现而不依赖数据库,或者创建具备unique的索引,确保不会出现重复录入的行。

insert into user (id,name,pm) values (100,'petty',18)
[执行成功]
insert into user (id,name,pm) values (100,'petty',18)
[error : Duplicate entry '100' for key 'PRIMARY']
复制代码其实无论是否考虑到幂等性,在分布式服务中,都应该尽量避免使用数据库直接生成Id的方式去创建主键。
Update 操作
对数据库的update操作简单来说,有【绝对值】修改,【相对值】修改 set [ num = 100 | num++ ]:
绝对值修改,例如商品下架
update product status = -1 where pid=1
复制代码属于天然幂等,如论执行多少次,结果都一直,不需要改造
(可能有人会有疑问说,如果又有另外一个线程把status修改成0,然后retry又把status修改成-1,那就达不到幂等效果,其实这个是另外一个问题了,这个不是本接口幂等的问题,而是业务隔离的问题)
相对值修改,年龄增加:
update xx set pm=pm++ where id = 100
复制代码这个就是明显的不具备幂等性,解决思路,现在程序层中查出数值进行计算
update xx set pm=pm++ where id = 100 and pm = 18
or
update xx set pm=19 where id = 100
复制代码这里可以在数据层面解决幂等性,不过这里多查了一次sql也会带来性能上的一个问题。
Delete 操作
delete from xx order by pm desc limit 10
复制代码delete 道理跟 update 一致,回到业务中,除非我们想drop掉整个表,不然其实不可以 delete 掉相对的条件的范围,一般都是需要查询出来哪些确切要delete的id,然后针对这批id进行delete
业务层面的幂等
上面从数据层面对CRUD做幂等处理,不过幂等性更多是考虑到业务场景,看一个例子。
状态机控制
例如我们有一个订单,假如订单的状态有:未确认->已经创建->已付款->已确认
update order set status = 已经创建 where orderid=1 and status = 未确认
update order set status = 已经创建 where orderid=1 and status = 未确认
【无效】
复制代码通过在设计状态字段,使用状态机的机制,确保status必须按照业务的流程往下走,这样在第二次更新时也会无效达到了幂等性的效果。
分布式锁
刚说到在MQ的消费场景中,可能出现多次消费的情况,这个情况只能由消费者自己解决,举个例子:
当用户下订单因为生产者不需要幂等产生了2个MQ,分别msg=xx001,msg=xx002,他们的orderid都是001,两个消息都发送给了MQ,MQ再将两个消息发送给2个消费者。两个消费者现在用orderid为key,组成了一把分布式锁,两个消费者同时去获取这一把锁,不过它们之间只能有一个消费者获取成功,或者成功的消费者将消费这个mq并执行,或者不成功的消费者将取消执行。
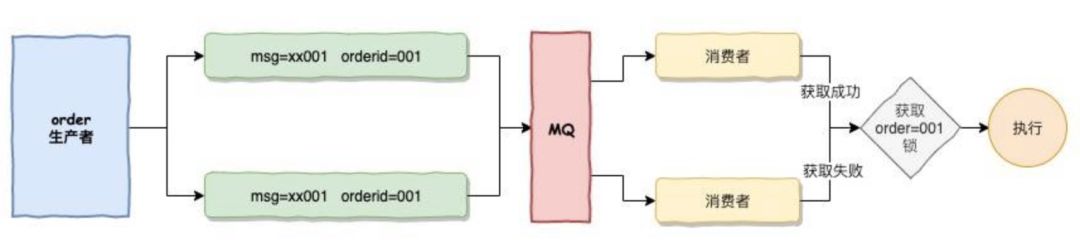
分布式锁主要起到的作用是解决并行的问题,将原本可能出问题的并行转为串性。
分布式锁解决不了的问题:
当一个消费线程获取锁之后,很快就执行了,然后把锁释放掉。另外一个线程因为MQ时延等问题在第一个线程执行完之后才接收到MQ,又获取到分布式锁,又将接口再一次执行。

分布式锁其实并不解决幂等性问题,但是可以看得出来,这两次接口的执行并不是并发执行,两次是一个串行关系,只要是串行关系,那可以借助状态机的机器去解决。这个时候就变成了一个业务隔离的问题
去重表
这个场景适合业务中有唯一插入的场景,例如在支付的场景中,订单只能被支付一次,可以把orderid作为一个唯一标示。新建一张去重表,并把orderid作为唯一索引,在写入订单表时,联通去重表一起写入并放在同一个事务中,如果重复调用,会由去重表抛出唯一索引约束的异常,进行回滚。
以上是关于「如何设计」具备幂等性的服务的主要内容,如果未能解决你的问题,请参考以下文章