服务端(后端)| Thrift序列化的核心思想
Posted 途牛技术中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务端(后端)| Thrift序列化的核心思想相关的知识,希望对你有一定的参考价值。
引言
序列化是网络信息通信中经常提到的话题,是将对象的信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。解析时,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。简单来说,就是编解码的事。常见的Socket通信协议中是如何进行序列化的呢,本文从http协议开始,对比介绍thrift框架下的对象序列化过程。


Http协议的序列化
HTTP在OSI七层模型中处于最高应用层,用TCP/IP模型看应用层,http协议已扩展得较好,头部信息中可以声明序列化方式,如常见的 text/plain、text/xml、application/json、application/xml,传输的是文本信息。
以一个常见的文本序列化(http头部content-Type为application/json)的场景为例说明其序列化的过程,如Java中springmvc结合jackson实现的MappingJackson2HttpMessageConverter,其核心利用jackson中ObjectMapper将对象转化成json结构对应的二进制流输出到httpOutputMessage的报文体中。也可以理解成,一个对象到JSON字符串,字符串到二进制流的过程。从字符串中可以看出,对象的成员属性变量名,显式的存在于报文中,因此,在请求端拿到http报文时,从头部类型可以知道application/json即可执行相应的解码过程。请求端如果是浏览器端可以顺利解析成对应的json文本并展示。
虽然名为超文本协议,数据通信的主体部分一样可以用来传输二进制数据,也就意味着可以传输任何数据。在一些非web前端调用场景下(比如有后端业务系统之间通过http调用的文本达到了上百兆,对本地网络和网关都产生了较大冲击),为了满足通用性、低消耗等目的,可以选择一些能够支持跨语言、性能好、压缩比高的序列化方式,比如定制实现content-type为application/x-java-serialization、appliaction/x-protobuff、application/x-thrift等。
Thrift协议的序列化
1
IDL示例
例如,通过Thrift IDL定义如下报文对象结构:
enum Operation {ADD = 1,SUBTRACT = 2}exception PTE {1: optional string code,2: optional string msg,}struct SubObj {2: optional double left,4: optional string name,}struct DemoObj {1: optional list<SubObj> simpleList,2: optional Operation op,}struct DemoResult {1: required bool success,3: optional list<DemoObj> objList,}service DemoSerivce {DemoResult simpleQuery(1: i32 num) throws (1: PTE e);DemoResult complexQuery(1: DemoObj obj) throws (1: PTE e);}
2
静态代码过程
Thrift 可以从上述IDL定义,生成各种开发语言栈对应的代码,包括C++、C#、Java、Python、NodeJS、php、Go等,其代码具备对象序列化的代码及RPC过程的服务抽象,是一个自洽完善的功能体。从thrift生成的Java静态代码来看,序列化过程会通过write方法将对象转化为二进制流,如下图所示:
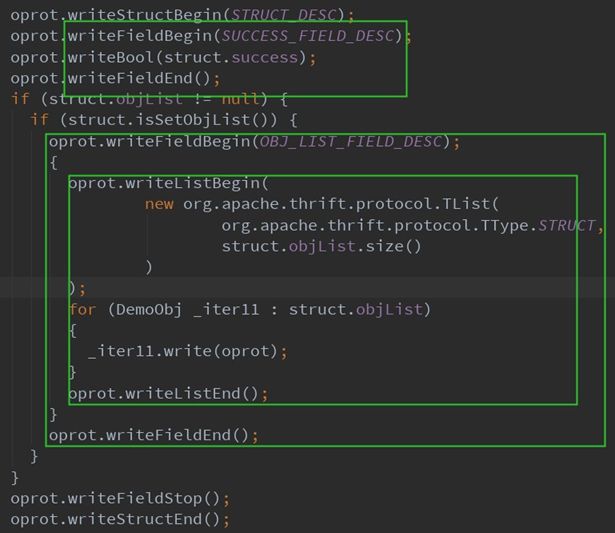
DemoResult包含了两个不同类型的字段,会根据其字段类型进行按Field序列化,包含头部、值、尾部。
其中,与http json报文序列化最大的不同是:成员变量名不会作为文本写入报文,而是写入Field字段在IDL定义语言中对应的标号,一个2个字节的短整型。在变量名较长且相对较多的时候,节省的传输量会比较可观。

该对象层完成后,写上对象结束符Stop标识。
反过来,反序列化的过程,则是根据序列号的规则,循环读取Field,根据头部序号适配对应的预定义的字段类型,执行对应的反序列化。具体如下图:
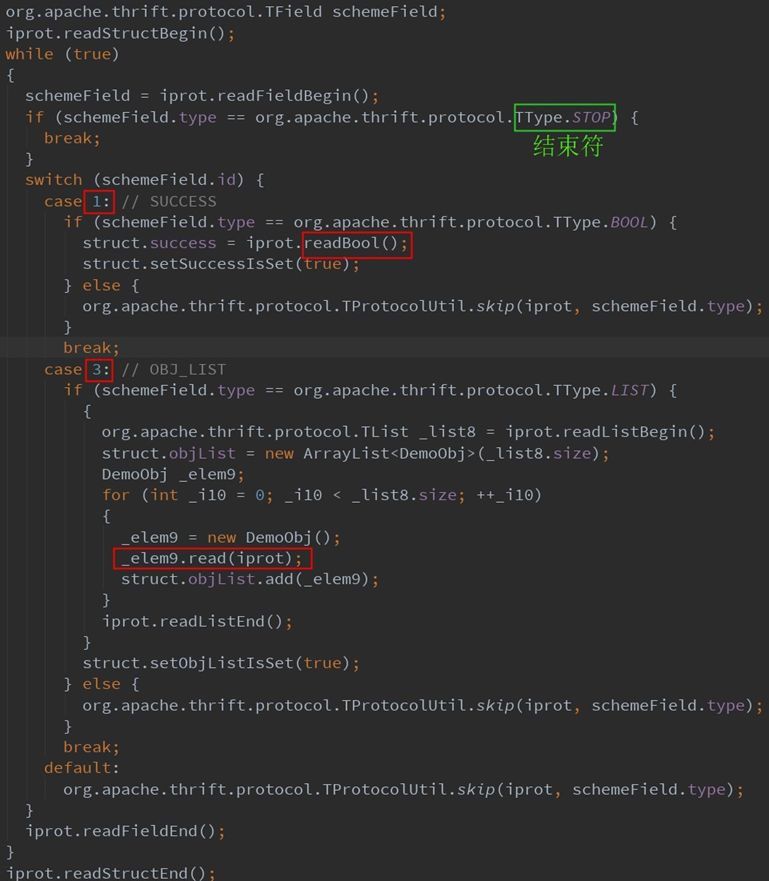
3
抽象过程
Thrift的TProtocol抽象层,抽象了正对Bool、Byte、i16、i32、i64、double、String、binary、set、list、map、struct的序列化过程,readXXXBegin()、readXXXEnd()、writeXXXBegin()、writeXXXEnd()等进行封装;
根据thrift的IDL定义,thrift进行对象序列化和反序列化时,遵循相同的递归和终止逻辑。将多个入参对象抽象成一个隐含的封装对象,出参和异常看成一个隐含的封装对象(出参序列化标号为0,异常序列化标号为其他自定义);可以看到,任何非基本类型的对象,读写过程可以如下递归描述。递归写的入口是 WriteStructBegin(),出口是 WriteFieldStop() + WriteStructEnd();递归读的过程是循环读,根据固化代码中的字段标号(字段名并不传输,这也是节省传输量的一个点)找到对应的对象类型,进行递归读,入口是ReadStructBegin(),递归出口是终止符STOP。
可以总结出如下递归过程:
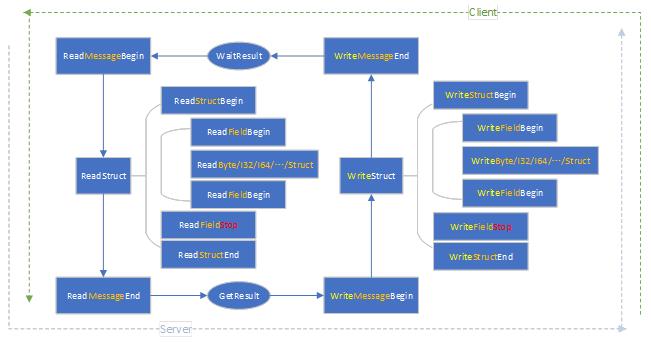
上图已将thrift序列化的核心思想表现出来了,知道了thrift对象是如何做序列化的,我们就能够比较自由地将之应用到一些对性能和传输量有要求的场景中。
Http报文用thrift压缩
前面段落2也提到,在面向纯后端通信时,http的报文序列化可以选择其他高效、压缩比高的序列化方式。比如可以直接将可serializable的java对象转换为二进制,亦可将thrift的对象转换成二进制报文等。
如下给出了一个thrift的不同压缩算法和传统文本、java二进制等序列化的性能和效果对比:
// 普通Java Serializable 对象Jvo jvo = new Jvo("AA", 99.9D);// case 1print(new ObjectMapper().writeValueAsBytes(jvo));ByteArrayOutputStream bytesOutput = new ByteArrayOutputStream();new ObjectOutputStream(bytesOutput).writeObject(jvo);// case 2print(bytesOutput.toByteArray());// Thrift对象Tvo tvo = new Tvo().setId("AA").setNum(99.9D);// case 3print(new TSerializer(new TBinaryProtocol.Factory()).serialize(tvo));// case 4print(new TSerializer(new TCompactProtocol.Factory()).serialize(tvo));// case 5print(new TSerializer(new TSimpleJSONProtocol.Factory()).serialize(tvo));
经过百万次测试,可以看到如下benchmark,包含各场景的百万次耗时、单次报文的字节数大小。

thrift在效率、压缩比方面都要好很多。
Thrift定义接口的另一种表示
从thrift序列化的核心思想可以看出,以静态代码持有这一过程,虽高效但缺乏通用性,毕竟天下之大,thrift也不可能为所有语言都生成一套完善自洽的代码。
因此,thrift也提供了其他出路:thrift的IDL转换成json格式(thrift某版本之前存在bug,途牛已进行相应的补丁修复),亦可以用一定的语法表示各个对象及服务方法的序列化特性。
比如,将前面示例中IDL对象转换后,可看到如下结构(截取部分):


基于这样的表示,对象序列化可以脱离各语言栈的静态代码,从而可以实现将一个json报文转换成对应格式的thrift对象序列化报文,进而一种基于http的跨语言thrift服务代理可以诞生。Pebble是途牛新一代的服务框架,支持了thrift等多种网络序列化协议;PebbleSidecar解决了非Java语言栈的客户端,跨语言调用Pebble服务且复用Pebble Java客户端的注册发现、服务治理等功能的问题。
基于这样的表示,结合一定版本发布规范,从而可以自动化落地Pebble服务的各版本接口文档。
总结
本文通过和http序列化过程的对比,深度剖析了thrift序列化的核心思想,并归纳出thrift通用序列化方案的可能。


途牛技术中心
期待与你相逢
以上是关于服务端(后端)| Thrift序列化的核心思想的主要内容,如果未能解决你的问题,请参考以下文章