Spark的thrift端口
Posted 健哥说编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark的thrift端口相关的知识,希望对你有一定的参考价值。
spark的thrift端口
(以下代码,在spark2.4.3+Hive3.1+Hadoop3.2上测试通过)
Thrift-server的功能是可以让spark通过自带的beeline连接,并操作hive的数据。
1、启动thriftserver
cd $SPARK_HOME/sbin
./start-thriftserver.sh
spark thriftserver ui:http://server:4040
Spark的thrift-server为spark-sql连接进程。
启动后,可以通过4040端口查看,如上。
2、登录
启动spark bin目录下的beeline
[isoft@server101 bin]$ ./beeline -u jdbc:hive2://localhost:10000 -n root
连接说明:
-n 可以指定一个任意的名称。
3、然后就可以在spark中操作hive的数据
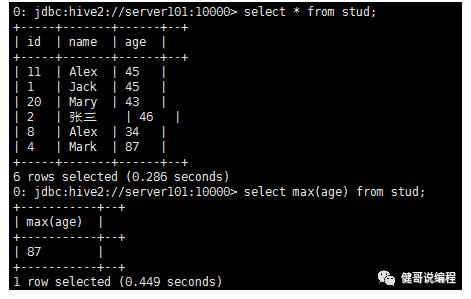
创建表:
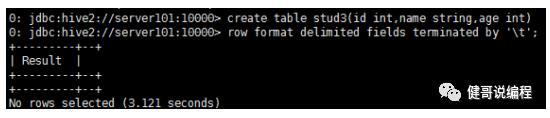
然后导入数据并查询:
4、退出
退出的话,直接输入 !exit即可。
0: jdbc:hive2://server101:10000> !exit
Closing: 0: jdbc:hive2://server101:10000
登录beeline之后:
更多命令,可以通过 !help获得。
在没有登录beeline之前,可以直接使用--help查看spark的beeline的参数:
[isoft@server101 bin]$ ./beeline --help
Usage: java org.apache.hive.cli.beeline.BeeLine
-u <database url> the JDBC URL to connect to
-n <username> the username to connect as
-p <password> the password to connect as
-d <driver class> the driver class to use
-i <init file> script file for initialization
-e <query> query that should be executed
-f <exec file> script file that should be executed
[more...]
最后:
1. 启动thriftserver: 默认端口是10000 ,可以修改
2. 启动beelinebeeline -u jdbc:hive2://localhost:10000 -n hadoop
修改thriftserver启动占用的默认端口号:./start-thriftserver.sh --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar --hiveconf hive.server2.thrift.port=14000
beeline -u jdbc:hive2://localhost:14000 -n hadoop
thriftserver和普通的spark-shell/spark-sql有什么区别?1)spark-shell、spark-sql都是一个spark application;2)thriftserver, 不管你启动多少个客户端(beeline/开发环境code),永远都是一个spark application解决了一个数据共享的问题,多个客户端可以共享数据;
开发时代码可以这么写:
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version></dependency>
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://hadoop001:14000","hadoop","")
val pstmt = conn.prepareStatement("select empno,ename,sal from emp")
val rs = pstmt.executeQuery()
while(rs.next()){
println("empno:"+rs.getInt("empno")+" ,ename:"+rs.getString("ename")+" ,sal:"+rs.getDouble("sal"))
}
以上是关于Spark的thrift端口的主要内容,如果未能解决你的问题,请参考以下文章