译文:Avro,Protocol Buffer和Thrift中的模式演化
Posted ZzHr学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了译文:Avro,Protocol Buffer和Thrift中的模式演化相关的知识,希望对你有一定的参考价值。
https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
当你希望将数据存储到文件或者通过网络传输的时候,你可能会发现自己将要经历以下几个阶段:
1、使用编程语言提供的内置序列化方案,比如Java serialization, Ruby的marshal,python的pickle等。或者你自己发明的格式。
2、你会体会到编程语言的限制,然后转向被广泛支持的JSON、XML
3、你会发现解析JSON花费的时间太长,你会因为它不能区分整数和浮点数而恼怒,然后你会发现你更加喜欢二进制字符串以及Unicode字符串。所以你发明了类JSON的二进制格式。
4、然后你发现人们会把各种各样的属性都塞到他们的对象里面,并且类型不统一,此时你将会非常向往模式和文档的格式。也许你正在使用静态类型编程语言,想根据模式生成模型类。
一旦你进入了第四个阶段,你的选择一般就是Thrift、Protocol Buffers或者Avro。这三种选择都提供了一种基于模式的高效、跨语言序列化数据的方式,并且可以帮广大Java用户生成代码。
文章(1,2,3,4)都对它们进行了比较。但是很多文章都忽视了一个初看普通实则关键的细节:当模式改变的时候会发生什么?【译者注:本文说到的模式变化/演变问题指的是模式定义好后,发送方/接收方一方修改了模式定义,可能导致的数据传递错误问题】
在实际生活中,数据一直都在变化。这一刻你觉得你确定好了一个模式,就会有人想出一个不符合预期的用例,并且试图快速在模式上增加一个属性。幸运的是,Thrift、Protocol Buffers以及Avro都支持模式的演化:你可以修改模式,你也可以同时让消费者和生产者同时在不同版本的模式工作。当你在使用一个大的生产系统时,这是一个非常有价值的特性,因为它允许你在不同时间升级系统的不同组件,而不需要担心兼容性。
这就引出了本文的主题。我将会探索Thrift、Protocol Buffers和Avro如何将数据编码成字节,这也将帮助我们理解它们如何处理模式变化。每一个框架的设计决策都很有趣。通过比较它们,我相信你可以变成一个更好的工程师(至少一点点)。
我将使用一个描述人的对象作为例子,下面是它的结构,这个JSON编码就是我们的基线。移除所有空格之后,总大小是82个字节。
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
用Protocol Buffers模式表示这个对象时,我们可能这样写:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}
当我们通过上面模式编码数据时,它消耗33个字节,如下图所示:
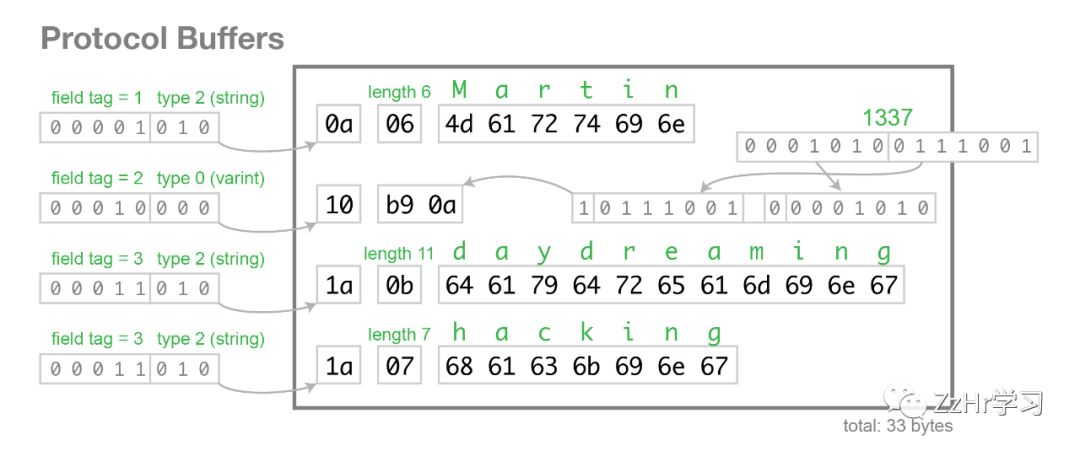
下面我们逐个字节来看这个二进制表示的结构。这个记录就是每个域的组合。每个域通过起始的一个字节表示自己的标签数字和类型。如果通过这个字节发现这个域是字符串类型,那么后面跟着的是字符串的字节数以及字符串的UTF编码表示。如果这个域是个数字,后面跟着的是数字的变长编码。Protocol Buffers不支持数组类型,但是同一个标签数字可以出现多次来表示多个值的域。
【译者注:观察上面的结构,更细致的划分是该字节的前5位表示序号,后3位表示类型,可以推断能存储的域数量上限是31,支持的类型最多7种。】
【译者注:variable-length integer,指变长数字编码,将一个定长的数字变成变长数字以节省空间,比如如果我们用64位来表示100会有很多位都是0。Protocol Buffers通过小端的方式忽略无意义的0。具体做法是把数字的二进制编码按7位7位地分成多组 ,每一组最多7个bit。这些7bit组按小端排序,即把每一组从右往左拼接起来才是正常的二进制编码。然后7bit组会在最前面加一个bit作为最重要位(most significant bit,MSB)来组成一个字节,这个bit会指出是否后面还有字节属于当前数字的7bit组 -- 从第一组到倒数第二组MSB是1,最后一组MSB是0。不同的软件可能使用不同的策略,比如SQLite会根据第一个字节的数字范围来确定后续多少个字节属于当前数字以及如何计算,但是核心思想都是通过初始的一个bit/byte来确定所需字节数,让小数字使用更少的字节数。】
这种编码方式在模式的演进过程中有重要作用:
1、optional、required、repeated域之间没有区别,除了标签数字可以出现的次数。这意味着你可以把一个optional的域变成repeated的,或者反过来(这种情况下,当解析器需要一个optional域,却发现一个标签出现多次时,可以只保留最后一个)。而required域需要一个额外的检查,所以如果你要修改它,你会面临运行时的风险(如果发送者认为它是optional,但接受者认为它是required)。
2、一个没有值的optional域,或者一个都没出现的repeated域,完全不会出现在被编码的数据中 -- 也就是说它们的标签值缺失了。因此,在模式下可以很安全地移除这种域。然而,将来必须不能复用这个标签数字给其他域,因为你可能仍然有数据使用那个标签代表已被删除的域。
3、你可以在你的记录里添加一个域,只要它被赋予了一个新的标签数字。如果Protobuf解析器看到一个标签数字不在它当前版本的模式定义中,它没办法知道这个域的名称,但是它可以知道这个域的类型,因为第一个字节的后3位可以告诉它。这意味这及时解析器无法完全解析出这个域,它也可以知道需要跳过多少个字节来找到记录的下一个域。
这种使用标签数字代表每一个域的方法非常简单和高效,但是我们很快就能看到并不是只有这一种做法。
Avro模式可以通过两种方式来写,JSON格式:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
或者IDL格式:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
注意这个模式里面没有标签数字!那么它的工作原理是什么呢?下面把相同的数据编码成了32个字节:【译者注:1337也是变长数字编码】
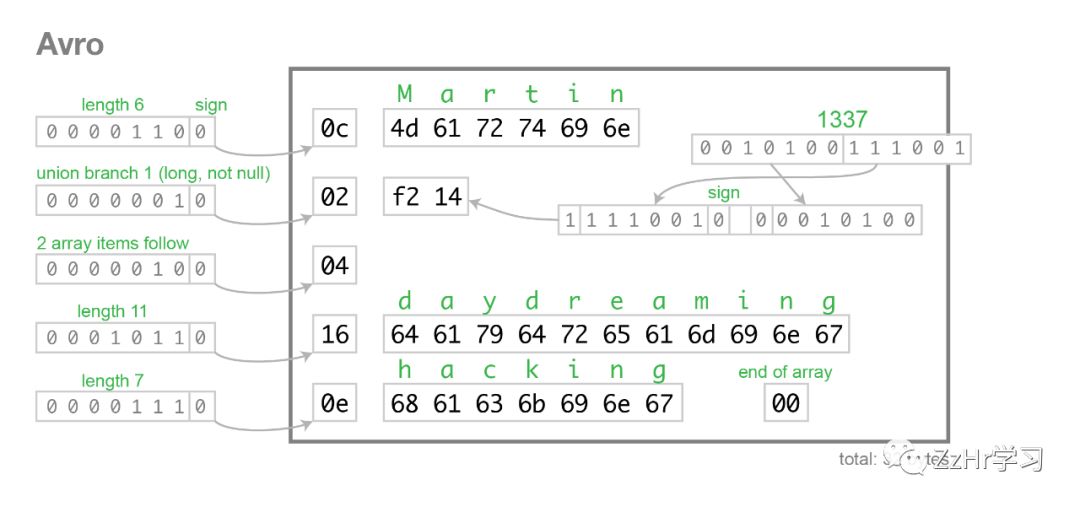
字符串就是一个长度前缀,后面跟着UTF-8字节,但是字节流中没有任何信息可以告诉你这是一个字符串。它既可以是一个变长的整数,也可以是其他东西。你唯一可以解析这个二进制数据的方式是随着模式来解读,由模式告诉你下一个类型是什么。你一定要和数据的写入者使用的模式版本保持一致。如果你使用了错误的模式。解析器可能没办法构建二进制数据的首部或尾部。
那Avro如何支持模式的演变呢?虽然你需要确切知道数据被写入时的模式(写入者的模式),但它不一定要与数据消费者所期望的一样(读取者的模式)。你可以把两个不同的模式给Avro解析器,它使用resolution rules(解析规则)来把写入者模式翻译成读取者模式。
对于模式解析器有一些有趣的功能:
1、Avro编码没有明确的指示说明下一个域是什么,它只是一个接一个地按照模式下的顺序编码每一个域。因为解析器没办法知道一个域是否应该跳过,所以Arvo没有optional域。相对的,如果你想要留出这样一个值,你可以使用一个集合体类型,类似于上面union {null, long}的结构。这会被编码成一个字节告诉解析器可能会使用集合体里面的哪一个类型,然后紧跟着具体的值。通过构建一个包含null类型(会被编译成空字节)的集合体,你可以使一个域变成optional。
2、集合体类型功能强大,但你在修改它们的时候必须非常小心。如果你想要添加一个类型到集合体中,你首先需要用新的模式更新所有读取者,以让他们知道如何解析。只有当所有读取者都更新后,写入者才可以把新加的类型放到新的数据记录里面。
3、你可以在记录里面随意记录域。虽然域是按照被定义的顺序进行编码,写入者和读取者的解析器都会根据名字来匹配域,所以Avro里面不需要标签数字。【译者注:其实是写入者在编码之前,先按照名字和值排序好再编码】
4、因为域通过名字进行匹配,修改域的名字是非常取巧的。你首先要更新所有读取者要使用新的名字,同时把旧名字作为别名(因为名字匹配机制会使用读取者的模式里的别名)。然后再在写入者的模式使用新的域名字。
5、你可以添加一个域到记录里面,需要你先给它一个默认值(例如当域的类型是一个带null的集合体时,用null)。默认值是必须的,因为当读取者使用一个新的模式解析器来解析一个用旧模式器编码的数据时(这样的数据会缺少新域的数据),它可以用默认值来填充新域。
6、相反的,你也可以从记录里面移除一个域,需要它已有一个默认值。(所以你应该尽可能地给所有域设置默认值。)当读取者用旧模式解析器来读取新模式解析器编码的数据时,可以使用默认值替代。
这种方式会要求我们知道一个记录被编码时的模式。基于数据被使用的情景,有不同的最优方案:
1、在Hadoop下,你一般会有包含了上百万记录的大文件,每条记录都使用相同的编码。Object container files可以处理这种情况:它们在文件的开头包含对应的模式,剩下的内容就是用模式进行编码。
2、在RPC情景下,每个请求和返回都带模式的话,会造成很大开销。但是如果你的rpc框架使用长连接,它可以在连接建立之初协商好模式并缓存起来。
3、如果你在数据库里逐个存储记录,你可以在不同时间采用不同的模式,所以你需要为每条记录声明它的模式版本。如果存储模式本身开销很大,你可以使用模式的hash值,或者一个顺序的版本号。然后你需要模式注册器帮助你根据版本号找到对应的模式。
在Protocol Buffers中,每一个域都是标签化的,而Avro中整个记录、文件或网络连接通过一个模式版本打标签。
第一眼看上去,Avro的方法会囿于太复杂,因为你需要分发模式。然而,我想Avro有以下这些特出的优点:
1、Oject container files可以很好地自我描述:被嵌入文件的写入者模式包含了所有的域名字和类型,甚至文档字符串(如果作者的模式也有)。这意味着你可以通过交互式工具如Pig来直接加载文件而不需要任何配置。
2、当Avro模式是json时,你可以添加你自己的元数据,例如域的应用描述。这些元数据也需要分发。
3、模式注册器可能在任何情况下都是好的,提供了文档化服务,帮助你找到和复用数据。因为你不能在没有模式的情况下解析Avro,模式注册器保证模式最新。当然你也可以给protobuf建立模式注册器,但是在操作过程中没有必要 。
Thrift是一个远比Avro和Protocol Buffers更大的项目,因为它不仅是一个数据序列化库,还是一个完整的RPC框架。它也有一些不一样的理念:Avro和Protocol Buffer标准化了一个二进制编码,Thrift提出了不同序列化格式的种类(称之为“协议”)。
实际上,Thrift有两种不同的JSON编码,以及不少于3种不同的二进制编码方式。(然而,其中一种二进制编码,DenseProtocol,只支持了C++实现,因为我们对跨语言序列化更感兴趣,我将专注于剩下的两种)
Thrift IDL里面的所有编码都使用同样的模式定义:
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
BinaryProtocol编码非常直接,但是也相当浪费(上面这个例子会消耗59个字节)【译者注:其实格式上和Protocol Buffer没有很大的差异,只是Thrift使用了相当多的字节来表示类型(1个字节,对于列表还需要一个字节表示列表元素的类型)、标签(2个字节,对应65536)和长度(列表长度是4个字节)。】:
CompactProtocol编码语法上一样,但是通过变长的整数和位压缩来把字节数降到34个:
就像你看到的,Thrift模式演化的方式和Protocol一样:每一个域在IDL下都人为地赋予了标签,标签和域都存储在二进制编码里面,所以解析器可以跳过未知的域。Thrift显式定义了一个列表类型而不是和Protocol一样使用重复域名字的方式,但不管怎么说,它们都很相似。
按哲学的说法,这些库是完全不同的。Thrift喜欢一站式,给你整个集成好的RPC框架和许多选择(支持跨语言),而Protocol Buffers和Avro更倾向于“只做一件事情,并把它做好”。
以上是关于译文:Avro,Protocol Buffer和Thrift中的模式演化的主要内容,如果未能解决你的问题,请参考以下文章