自旋锁,互斥锁,原子变量性能对比
Posted cppFollowers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自旋锁,互斥锁,原子变量性能对比相关的知识,希望对你有一定的参考价值。
1、前言
最近看到一些代码,看到有些代码使用了自旋锁。好奇其与互斥锁,尤其是原子变量的性能,于是做了如下测试。不同平台可能测试的效果不尽相同,但是基本类似。测试使用linux系统,锁的性能主要与CPU调度相关,所以只列出CPU相关的主要系统参数,如下图所示:
2、no bb, show code
测试使用两个线程,对同一个变量重复执行前置++操作,然后查看耗时。no bb了,直接show code。以下为测试代码:
1#include <iostream>
2#include <thread>
3#include <mutex>
4#include <atomic>
5
6#include <pthread.h>
7#include <sys/time.h>
8#include <unistd.h>
9
10using namespace std;
11using namespace chrono;
12
13//#define COUNT 100000
14//#define COUNT 1000000
15#define COUNT 10000000
16
17
18int num = 0;
19pthread_spinlock_t spin_lock;
20mutex mutex_lock;
21
22
23void nolock_proc(){
24 for(int i=0; i<COUNT; ++i){
25 ++num;
26 }
27}
28
29void spin_proc(){
30 for(int i=0; i<COUNT; ++i){
31 pthread_spin_lock(&spin_lock);
32 ++num;
33 pthread_spin_unlock(&spin_lock);
34 }
35}
36
37void mutex_proc(){
38 for(int i=0; i<COUNT; ++i){
39 mutex_lock.lock();
40 ++num;
41 mutex_lock.unlock();
42 }
43}
44
45void lock_guard_proc(){
46 for(int i=0; i<COUNT; ++i){
47 std::lock_guard<std::mutex> guard(mutex_lock);
48 ++num;
49 }
50}
51
52atomic<int> atomic_num(0);
53void atomic_proc(){
54 for(int i=0; i<COUNT; ++i){
55 ++atomic_num;
56 }
57}
58
59int main(){
60 {
61 num = 0;
62 auto start = system_clock::now();
63 std::thread t1(nolock_proc), t2(nolock_proc);
64 t1.join();
65 t2.join();
66 auto end = system_clock::now();
67 auto duration = duration_cast<microseconds>(end - start);
68 cout << "nolock_proc duration = " << duration.count() << " "<< num << endl;
69 }
70
71 {
72 num = 0;
73 //maybe PHREAD_PROCESS_PRIVATE or PTHREAD_PROCESS_SHARED
74 pthread_spin_init(&spin_lock, PTHREAD_PROCESS_PRIVATE);
75 auto start = system_clock::now();
76 std::thread t1(spin_proc), t2(spin_proc);
77 t1.join();
78 t2.join();
79 auto end = system_clock::now();
80 auto duration = duration_cast<microseconds>(end - start);
81 cout << "spin_proc duration = " << duration.count() << " "<< num << endl;
82 pthread_spin_destroy(&spin_lock);
83 }
84 {
85 num = 0;
86 auto start = system_clock::now();
87 std::thread t1(mutex_proc), t2(mutex_proc);
88 t1.join();
89 t2.join();
90 auto end = system_clock::now();
91 auto duration = duration_cast<microseconds>(end - start);
92 cout << "mutex_proc duration = " << duration.count() << " "<< num << endl;
93 }
94 {
95 num = 0;
96 auto start = system_clock::now();
97 std::thread t1(lock_guard_proc), t2(lock_guard_proc);
98 t1.join();
99 t2.join();
100 auto end = system_clock::now();
101 auto duration = duration_cast<microseconds>(end - start);
102 cout << "lock_guard_proc duration = " << duration.count() << " "<< num << endl;
103 }
104 {
105 atomic_num = 0;
106 auto start = system_clock::now();
107 std::thread t1(atomic_proc), t2(atomic_proc);
108 t1.join();
109 t2.join();
110 auto end = system_clock::now();
111 auto duration = duration_cast<microseconds>(end - start);
112 cout << "atomic_proc duration = " << duration.count() << " "<< atomic_num << endl;
113 }
114 return 0;
115}
#define COUNT 100000,执行两次结果如下图所示:
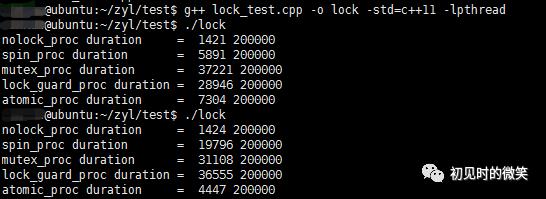
#define COUNT 1000000,执行两次结果如下图所示:
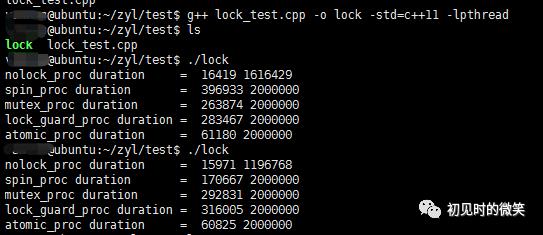
#define COUNT 10000000,执行两次结果如下图所示:
大家都挺忙的,直接说以下4个结论。大家也可以参考上文中的代码自行修改测试。
1、前缀++操作虽然只有一行代码,但编译以后的汇编并不是原子操作。因此,多线程写需要加锁。结果未出错是因为执行的次数少。上面测试用例在两个线程对同一变量进行操作,测试结果如下:
在COUNT==100000时,期望200000,无锁结果正确,有锁结果正确。
在COUNT==1000000时,期望2000000,无锁结果错误,有锁结果正确。
在COUNT==10000000时,期望20000000,无锁结果错误,有锁结果正确。
2、自旋锁的性能不稳定,与CPU调度强相关。
有人说,“当一段程序较短时,可自旋锁代码互斥锁以提高程序性能”。这句话从原理上理解是对的。
互斥锁(mutex)属于sleep-waiting类型的锁,当前线程获取不到锁的时,当前线程会被阻塞(blocking)。当前CPU进行上下文切换将当前线程置于等待队列中。在适当时候CPU再次切回当前线程。
spin属于busy-waiting类型的锁,当前线程获取不到锁的时,当前线程会不停的请求锁,直到得到这个锁。
但是上述所有的测试用例代码中都只有一个前置++操作,并没有改变锁中的代码,仅仅是调整执行的次数,性能就有差距。可能是由于CPU的时间片到了切了线程。也就是说自旋锁与CPU调度强相关。
在COUNT==100000时,执行了两次程序,性能都比互斥锁好。前者甚至已经优于原子变量。
在COUNT==1000000时,执行了两次程序,前者比互斥锁差,后者比互斥锁好。
在COUNT==10000000时,执行了两次程序,性能都比互斥锁差。
综上:当要锁一段代码时,除非对代码特别熟悉,需要追求更高的性能时再使用自旋锁,否则就使用互斥锁或者原子变量。
3、lock_guard封装了互斥锁,在构造和析构函数中实现了加锁和解锁,有多余的性能开销。性能没有直接使用lock和unlock好。
4、C++11中提供了原子变量,当在多线程中对共享变量进行操作时,推荐使用原子变量。性能优于互斥锁,性能也很稳定。
3、总结
其实现在计算机的性能已经非常优越,每秒执行的运算都在百万次以上。一般来讲,除了自己程序中明确的循环十几万百万千万的(如图片或者视频运算)或者写一些高并发的服务器,需要调整代码逻辑或者使用某些特定技术来提高性能的。正常来讲C/C++只要万级别的操作运行时间都是可以忽略不记的。
平时代码中自认为的一些运算小技巧,编译可能就会帮你优化。即使不优化,一般每秒也不会执行上万次,所以那些技巧对于一般程序来讲效果甚微。比如,上面测试用例COUNT==10000000时候,某次原子变量执行时间488905us,互斥锁2426716us。计算机执行了20000000万次前缀++操作,性能差异仅仅1937811us,也就是不到2s。平均一次的性能差不到0.1us。你写的那段代码就算每秒钟执行10000次,才会提升1ms。可能你的程序哪块有个wait操作,你的可能花费了好久想出来的巧妙算法就白费了。所以,只要不是特殊需求的代码,你就大胆的写,不要怕计算机算不过来。除非系统有性能要求,否则无需在性能上花费过多的时间。代码的优化先从逻辑入手,然后才是具体的代码实现。
当然有些明知道会快的操作,直接用就行了。比如,原子变量的性能比互斥锁好,所以能原子变量的就不要用互斥锁了。再比如,前置++理论上比后置++快,但是对于内置类型来讲性能已经可以忽略不计了。如果自己设计类重载了前置++和后置++运算符了,就可以明显感觉到性能差距了。直观的看后置++就比前置++多一行对象构造的代码。这个以后会在C++入门专栏的运算符重载中说,希望能坚持写到分享运算符重载的那一天。
感谢阅读,喜欢的话,长按识别图中二维码关注我呀!
以上是关于自旋锁,互斥锁,原子变量性能对比的主要内容,如果未能解决你的问题,请参考以下文章