网络爬虫|接口测试|另一种技术:使用 shell 命令获取资源
Posted 软件测试资源站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫|接口测试|另一种技术:使用 shell 命令获取资源相关的知识,希望对你有一定的参考价值。
概述
之前接口测试的时候,经常遇到从response中截取数据的情况,处理起来可能也相对简单一点。今天换个玩法,用shell命令获取头条个人主页文章。
命令如下:
$ curl https://www.toutiao.com/u/840c2172e2e3 |grep 'title' | awk -F '>' '{print $2}' | grep -v -e '</div' -e '</title' |awk -F '<' '{print $1}' 接口测试框架优化(三)---支持简单串接口使用charles筛选、修改请求与响应linux下mysql常用操作(学习笔记)随便写写最近的面试一些linux命令学习(二)--grep命令一些linux命令学习(一)windows下appium1.6排坑及安装基于python+appium+yaml安卓UI自动化测试分享接口测试框架优化(二)---主要代码
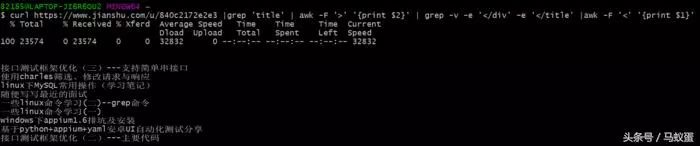
详述
实现这个目标,需要懂一些基础的命令
curl
grep
awk
curl命令学习
curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。
目前我只get到了使用curl命令发送请求,暂时没有用来上传下载文件,所以不多做介绍。
输入 curl -h,可以看到使用帮助
$ curl -hUsage: curl [options...] <url> --abstract-unix-socket <path> Connect via abstract Unix domain socket --anyauth Pick any authentication method-a, --append Append to target file when uploading --basic Use HTTP Basic Authentication --cacert <file> CA certificate to verify peer against --capath <dir> CA directory to verify peer against-E, --cert <certificate[:password]> Client certificate file and password --cert-status Verify the status of the server certificate --cert-type <type> Certificate file type (DER/PEM/ENG) --ciphers <list of ciphers> SSL ciphers to use --compressed Request compressed response --compressed-ssh Enable SSH compression...
就我自己实际操作的几个介绍一下:
1.获取页面内容
curl https://www.toutiao.com/
不加任何选项使用 curl 时,默认会发送 GET 请求来获取链接内容
2.发送POST请求
curl -H "Content-Type: application/json" -X POST-d '{"uid": "10588666", "device_code": "", "count": 8, "op": 1, "page": 1, "content_type": [1,2,3,4], "skip_freq": 0, "exclude_docs": [], "is_wifi": 0, "is_videopage": 0, "region": 111, "register_timestamp":1519642955, "tk": "ACAWILmsfP5FV7JqM6knRK66w8j9Rqr0Aqk0NzUxNDk1MDg5NTIyNQ", "client_version":20826, "group":"exp_test_member00"}' http://localhost:2051/recommend
这边用到了3个参数
H 定义请求头 header
X 指定请求方式
d 指定发送的数据
3.显示响应头
curl -I https://www.toutiao.com/u/840c2172e2e3
加了-I 参数,仅显示response header,结果如下
$ curl -I https://www.toutiao.com/u/840c2172e2e3 % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0HTTP/1.1 200 OKDate: Mon, 14 May 2018 13:05:15 GMTServer: TengineContent-Type: text/html; charset=utf-8X-Frame-Options: DENYX-XSS-Protection: 1; mode=blockX-Content-Type-Options: nosniffETag: W/"600753ffd703a50bfb60aca2580cddb0"Cache-Control: max-age=0, private, must-revalidateSet-Cookie: locale=zh-CN; path=/Set-Cookie: _m7e_session=406d79c64df9441d376f82b2; path=/; expires=Mon, 14 May 2018 19:05:15 -0000; secure; HttpOnlyX-Request-Id: 9813d0cf-a68e-492f-8d04-580b8e149af6X-Runtime: 0.129613Strict-Transport-Security: max-age=31536000; includeSubDomains; preloadX-Via: 1.1 PSfjqzdx7yx12:4 (Cdn Cache Server V2.0), 1.1 xinxiazai13:1 (Cdn Cache Server V2.0)Connection: keep-aliveX-Dscp-Value: 0
4.保存响应的内容
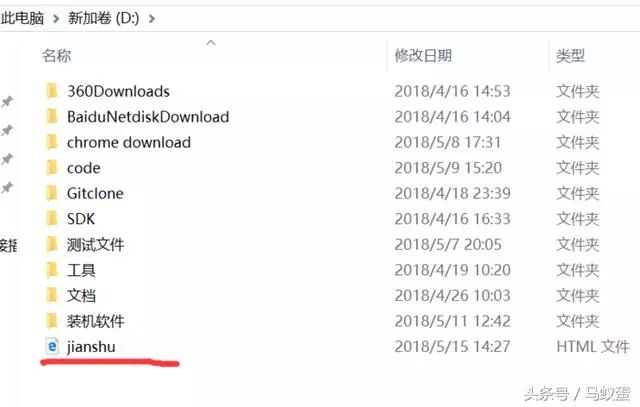
curl -o D:jianshu.html https://www.toutiao.com/u/840c2172e2e3
执行此命令,会在D盘根目录生成一个toutiao.html文件,如图:
curl命令还有其他用法,我这边由于暂时没有用到,所以没有进一步操作,感兴趣可以参考这篇文章学习一下
grep命令学习
关于grep命令,我上次学习了一次,这边就不多说了,可以参照我之前的学习笔记。
shell命令获取文章标题中用到grep的可能就是 -v -e 两个命令,相对还是比较简单的。
awk命令学习
awk我也是get到一点皮毛,没有很深入研究。大致工作流如下:
-F 分隔符划分域,,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键".
举个例子:
D盘下新建一个文件,awk.txt。
执行命令:
$ nl awk.txt 1 root 1 name:001 2 cha 2 naaa:002 3 dong 3 nacc:003 4 fead 4 naic:004
如果只要显示行号
$ nl awk.txt |awk '{print $1}'1234
如果要显示:后面的内容
$ nl awk.txt |awk -F':' '{print $2}'001002003004
结束
使用shell获取头条主页文章,写法肯定不止这一种方法
$ curl https://www.toutiao.com/u/840c2172e2e3 |grep 'title' | awk -F '>' '{print $2}' | grep -v -e '</div' -e '</title' |awk -F '<' '{print $1}'
但是大致上思路是固定的:
将结果用grep 筛选出需要的,排除不需要的
再用awk分割选择自己需要的域即可。
期待后面,开发出更多关于shell的玩法。。。
程序爬虫抓取有用资源共享给大家
关注后,私信回复【资料包】获取如下内容,
测试资料、工具安装、Python、效率软件、自动化测试报告、梯子、微信群、测试框架 等
另外
「微软小冰」机器人,欢迎调戏。
回复「小冰」
或其它任意关键词即可
同时你们获取资料的方式更加智能,
回复你想要的任意资料名称
小冰都会给你找出来。
另外再
通知一件事
头条号内容注重分享互联网爬虫获取的各种资源。
头条号请点击「阅读原文」直达。
END
以上是关于网络爬虫|接口测试|另一种技术:使用 shell 命令获取资源的主要内容,如果未能解决你的问题,请参考以下文章