SoundCloud的微服务启示:从交付流程和康威定律看微服务
Posted 灵雀云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SoundCloud的微服务启示:从交付流程和康威定律看微服务相关的知识,希望对你有一定的参考价值。
编者按:我们已经看了很多关于实现微服务的技术和架构方面的文章,首先分享一个微服务的小段子给大家:
这个段子主要反映的还是组织架构的问题,根据康威定律,设计系统的组织,其产生的设计和架构等价于组织间的沟通结构。也就是说系统的架构和团队的结构存在映射关系,想要实现微服务,必然背后的团队是能够和微服务架构相对应的。今天的文章主要帮助大家认识微服务架构背后的流程和团队建设。
本文作者Phil Calçado曾任SoundCloud技术总监(目前是DigitalOcean的技术总监),主要从交付流程和团队建设方面回顾了SoundCloud是如何一步步实现微服务的。SoundCloud是一家德国网站,提供音乐分享社区服务,是音频界的Youtube。以下为译文:
在SoundCloud的时候,我的工作就是负责将一个Ruby on Rails的单体应用,转变为微服务架构的应用。可能会另大家失望,我们迁移到微服务的原因主要是为了提高交付效率,而不是技术的驱动,下面我会解释。
最开始我加入了后端App团队,负责我们Ruby on Rails的单体架构应用。那时我们还不叫它legacy,我们叫它mothership。App团队负责Rails应用的所有事情,包括老用户的接口。Next是一个单页的javascript web应用,我们遵循了标准的做法,将它作为一个连到开放API的常规客户端,用单体Rails实现。
App和Web两个团队是完全分开的,办公地点都不在一座大楼里,几乎只有在全体大会上见面,平时就通过issue trackers 或IRC等工具进行沟通。如果要问团队里某个人我们的开发流程是怎样的,他会这么回答你:
某人有了新feature的想法,就会写一段话,画几张mockup。我们就会小组讨论一下;
设计师规范用户体验;
我们写代码;
测试后,我们部署。
但是这中间有很多问题,工程师和设计师总经常抱怨工作太多,同时产品经理则抱怨他们没按计划完成任务。
作为一个toC的业务,我们的版本发布要讲究时机,我们要在圣诞节前发布Next的beta版本,否则接踵而来的各种节日会让我们到明年的第二季度才有主动权,因为我们不想在新网站可用之前发布任何新的feature。时间很紧迫,于是这个时候我们开始思考整个交付流程的改善。
加入SoundCloud之前,笔者做了多年的咨询工作,期间获得最宝贵的经验就是价值流图。综合与工程师们的非正式访谈和我们多个自动系统收集的数据,我们画出了一个能反应我们真实情况(不是想象中)的软件交付流程图。当然这张图不能分享出来,我只能告诉你和下面的这张图相去甚远:
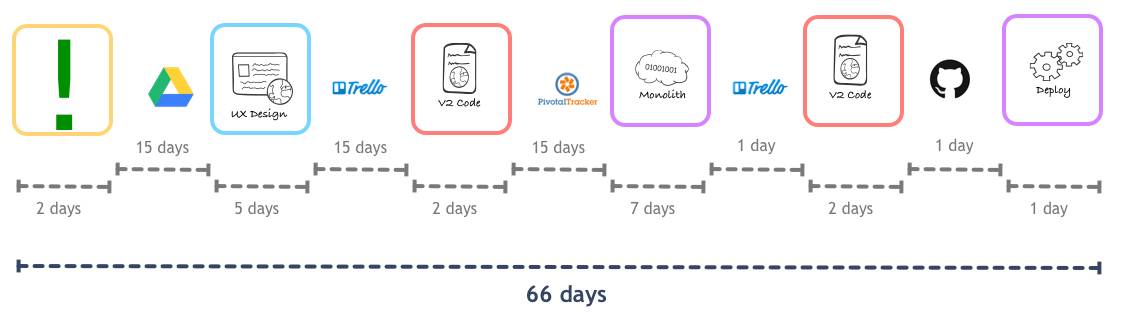 真实的流程是这样的:
真实的流程是这样的:
某人有一个新feature的想法,他们会写一个非常简单的文档,画一些mockup,存在Google Drive的文档中;
这个文档会一直待在那里,直到有人有时间接手它;
设计团队拿到文档后,会进行用户体验的设计,这个feature会变成web团队在Trello中的一个项目;
这个项目至少要在Trello中滞留两周,直到工程师有时间接手;
于是工程师团队开始正式工作,在将设计转化为假/静态数据填充的网页后,工程师们会将更新写入Rails的API中,让这个网页能工作。这个过程会被写入App团队的工具PivotalTracker中;
这个项目又会在Pivotal Tracker中待两周左右,直到App团队有时间去看;
然后App团队会写代码,集成测试,让API生效等。然后他们会更新Trello,让web团队知道这些进度;
等web团队确认了Trello项目的更新情况,后端也完成相应的工作;
Web团队的开发者会让客户端代码和后端实现匹配后,为部署亮起绿灯;
因为部署存在着风险,很慢,也很痛苦,App团队会等几个feature都进入master分支后才开始部署到生产环境。这意味着这个feature又会在代码控制部分滞留几天,很有可能还会被回滚,因为你的feature可能和其它不相关部分的代码出现冲突;
最好的情况是这个feature最终被部署到了生产环境。
当然这些步骤之间也会有很多反复,我们暂时先忽略这些。算下来,一个feature大概要花2个月才能发布,更糟糕的是期间可能一半多的时间都在等待。
类似map的工具,能让我们清楚地看到一个流程中不合理的地方。起码我们很快意识到应该将发布日常化,而不是攒到足够的feature再去部署。虽然这距离持续部署还很远,但让我们的周期缩短了:
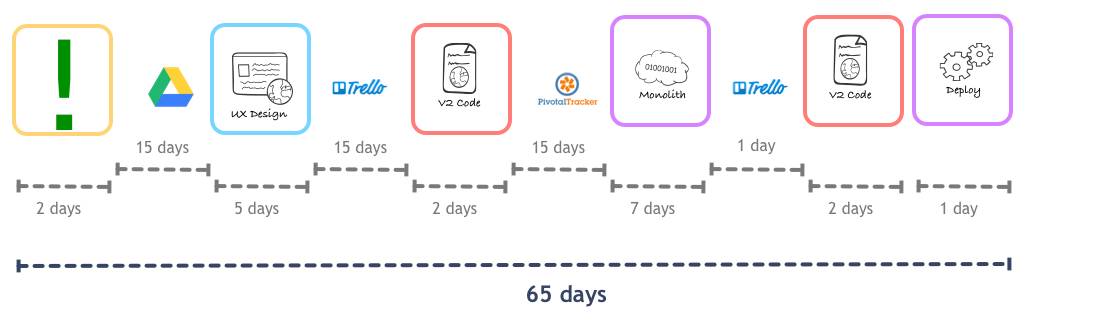
另外一个大问题是前端开发和后端开发的关系,我们切分Web和App团队的方式,完全让后端开发人员脱离了实际产品。他们遇到了很多困难,在产品上完全没有话语权。对于一个对开发者需求很高的产品来说,这并不是一个明智的做法。
造成的问题是,在开发者47天的工作时间中,只有11天在做实际的工作,剩下的时间都在排队或等待。
然后我们做了一个颇具争议的决定:前端开发人员和后端开发者专注于一个feature,结对开发,直到它的完成。我们只有8个后端和11个前端,前端要做尽可能多的前期工作,以减少后端的工作量。我们先在一对前后端开发者上进行尝试,再慢慢扩展到其他开发者。新的流程如下:
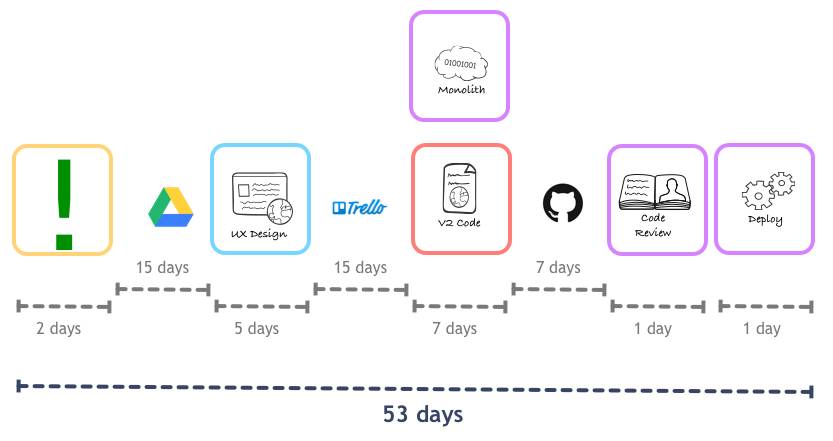 从个人角度来讲,每个人最终花在一个feature上的时间变多了,但这是相对的,由于他们是协同工作的,端到端的编程时间要比原来少。成效非常明显,我们决定将这个办法推广到流程中的其它步骤:比如设计,产品经理和前端组成一组,共同设计一个feature,整个周期进一步缩短了:
从个人角度来讲,每个人最终花在一个feature上的时间变多了,但这是相对的,由于他们是协同工作的,端到端的编程时间要比原来少。成效非常明显,我们决定将这个办法推广到流程中的其它步骤:比如设计,产品经理和前端组成一组,共同设计一个feature,整个周期进一步缩短了:
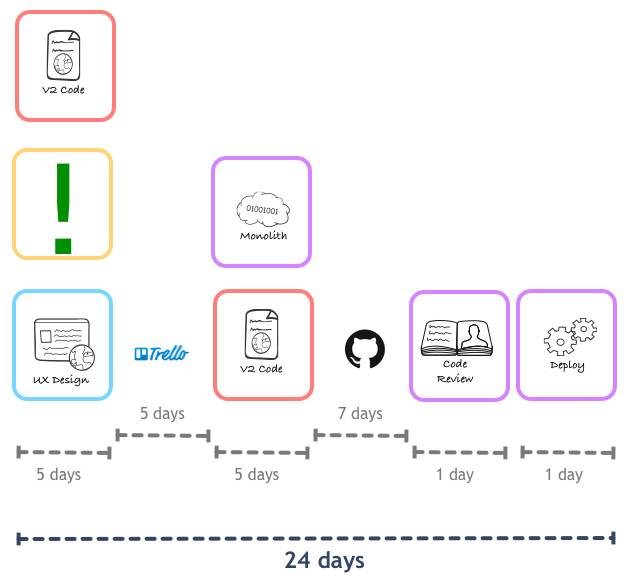
需要注意的是,考虑到App团队中后端团队开发者比原来更分散了,在代码被提交到Rails app的master分支之前,就是Pull Request的流程部分,要有一个强制的代码review过程。这里的时间应该也可以优化,下面来解决这部分问题。
SoundCloud最吸引我的地方是它的工程师文化,和之前我在ThoughtWorks的氛围很像,但也有很新鲜的地方,比如强制的code review。
2011年,所有创业公司都在尝试复制Github的模式,最有名的当属ZachHolman的演讲『HowGitHub Uses GitHub to Build GitHub』,多年实践和倡导trunk-based-development,我非常期待像SoundCloud和Github这样的成功公司能用一种不同的方式。
之前,App团队的工程师都坐在一起工作,共享一个任务清单。整个代码库都遵循相同的规则和模式,代码提交都是根据现有的设计,毫无新意。Pull Request的流程只是一个形式,花在review提交物上的时间不到1小时。
随着结对开发对人员结构的调整,由于不知道在部署什么或者不了解feature的设计,而造成的有问题的部署越来越频繁。我们强制要求:代码变更被提交到主线和最终部署之前,所有的变更都要正式经过另一位工程师的确认。
正如上图所示,在正式上线前要长期的Pull Request等待。为改善这种情况,我们的第一步优化是让每个人每天至少花一小时的时间review团队外的Pull Request。但是效果不大,因为一些小的Pull Request会被很多人review,而大的PullRequest没人review。
我们决定将Next项目中的工作再进行切分,让每个Pull Request更易于管理。这样一来每个Pull Request都可以被很快地review和merge了,但这么做可能会让reviewer们只见树木不见森林,有时一连串看起来很好的代码提交,可能隐藏着危险的架构错误。
为了节省在整个lead time中Pull Request的这8天时间,首先要弄明白这些时间的根本目的:
为什么我们需要Pull Request?因为人都会会犯错,如果让代码更改实时生效的话,很有可能整个平台都会down掉;
为什么人这么容易犯错?因为代码库很复杂,很难尽在掌握;
为什么代码库这么复杂?最开始SoundCloud是一个简单的网站,但随着时间的推移它成长为一个大平台,有很多功能和客户端应用,用户不但有同步异步之分,数量也非常大。这个复杂平台中,这么多组件都在一个代码库中实现;
为什么只用一个代码库实现这么多组件?因为范围经济。mothership已经有一套成形的部署流程和工具,架构也能抗住峰值和DDOS的攻击,横向扩展也没问题。如果要构建一套新系统,所有都要推到重来;
为什么不利用规模效应,构建更多、更小的系统?
其中第五个问题回答起来有点难度,可能会有两种答案:
为什么不利用规模效应,构建更多,更小的系统?这样做可能比单一的代码库效率更低,我们应该构建更好的工具和测试环境,提高开发人员的效率。Facebook和Esty就是这样做的;
为什么不利用规模效应,构建更多,更小的系统?我们需要做些实验,找到我们需要的工具和支持。并且根据我们构建的系统数量,来思考其产生的规模效益。这是Netflix和Twitter的做法。
两种方式各有优劣,问题是哪种更容易做到。钱和资源不是问题,但是我们缺少人力和时间,需要立竿见影的办法。
再次回看下我们的系统,我们总是将后端系统看得很简单,比如这样:

很显然这种心态会让我们把系统按单体架构来考虑。实际上,如果你打开这个黑盒就会发现,我们的系统更像是这样的:
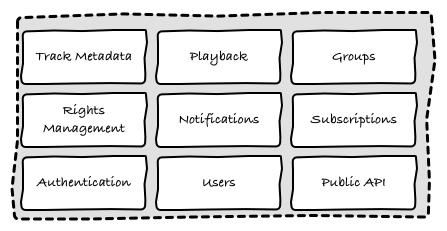
我们没有单独的网站,只有一个平台,由多个组件组成。每个组件有自己的所有者和独立的生命周期。
比如,subscriptions模块在构建完成后,只在支付网关修改时更新,而像notifications和其它用户增长相关的模块,则要每天更新。
它们期望的SLA也是不同的,比如notification模块1个小时没响应,可能都不会有人发现,但playback如果失效5分钟,会严重影响用户的体验。
通过对A选择的研究,能让单体架构继续为我们服务的唯一方式就是,在代码和部署架构上明确这些组件。
在代码层面,我们需要确保一个feature的更新可以被独立地开发,不涉及其它组件中的代码。要确保更新不会带入bug,更新的runtime也不会影响无关的系统。这是业界老生常谈的问题,我们要明确每个组件的边界,还要清楚地知道哪些组件有相互依赖关系。如下图所示:
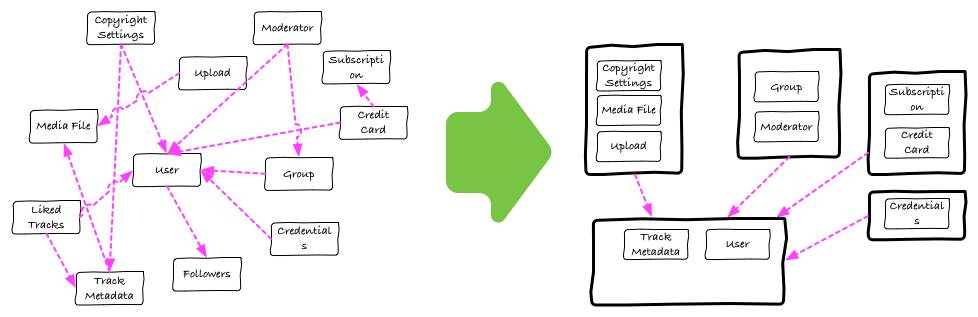
在部署方面,要确保feature可以被独立部署。一个模块的更新不应该牵扯到不相关模块,而且如果部署失败,应该只有那个模块受到影响。为了实现这个目的,我们仍然是在所有服务器上部署相同的代码,但是使用负载均衡器确保一组服务器只负责一个feature。
做到这一点当然不是个小工程,尽管以上这些不需要改变当前的技术栈和工具,依然会带来问题和风险。
就算一切进行得很顺利,目前单体架构的代码也需要修改,这些代码频频出问题,到处都是技术债务,除了我们自己制造的混乱我们还要把Rails从2.x升级到3,这也是个大迁移。
以上这些问题促使我们考虑B选择,本来我们以为不会有太大差别:
但至少这种方式的效果是立竿见影的,我们要创建的都是新项目,Pull Request带来的问题都不重要了。
我们决定尝试一下,最终将第一个货币化项目作为服务构建,和单体架构隔离的。这个项目包含了几个重大feature,也是对subscription模块的重大改进,并且比预计的deadline提前交付了。
我们将这个架构经验推广到了所有新构建的功能上,最开始的服务用Clojure和JRuby构建的,最后迁移到了Scala和Finagle上。
于是,从2013年起SoundCloud所有新功能都是用服务构建的,不知道什么时候起我们开始叫它们微服务。
这个新的架构减少了新feature的Lead time,目前来说一切都还好。但是对于新feature来说。每当要升级现有的单体架构中的feature,就会走入旧的恶性循环中。而且,由于架构的迁移,大家花在微服务时间在逐渐超过单体架构,微服务的reviewer在减少,Pull Request又要排队了。
每当有重大更新要被提交,我们都预留出重组的时间让新feature和单体架构分离。但并不奏效,大家还会在旧代码库上做更新,或者虽然用微服务实现了,但和单体架构耦合度很高。
我们意识到团队中缺乏自治的机制。what’s everybody’s responsibility is nobody’sresponsibility,如果没有责任感,就没有人会去主动承担更改旧代码的风险。
于是我们开始考虑分隔团队,每个团队3-4个人,负责特定的领域。这些团队被明确告知对某些模块有完全的自主权,这意味着他们既要为所有问题负责任,又有任意修改它们的自由。如果愿意,他们可以继续保持这些模块的单体架构。
最后的结果不出所料,大批模块从单体架构中脱离了出来。目前,SoundCloud的架构中仍然存在着单体架构的部分,但是所占的比例越来越少,甚至很多不是面向网络的。有些事很小但很稳定的feature,可能保持不变是成本更低的选择。
原文链接:http://philcalcado.com/2015/09/08/how_we_ended_up_with_microservices.html
微服务
以上是关于SoundCloud的微服务启示:从交付流程和康威定律看微服务的主要内容,如果未能解决你的问题,请参考以下文章