十年·杭研技术秀 | 分布式转码服务高可用浅析
Posted 网易云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十年·杭研技术秀 | 分布式转码服务高可用浅析相关的知识,希望对你有一定的参考价值。
年
十
2016年对于网易杭州研究院(以下简称“杭研”)而言是重要的 - 成立十周年之际,杭研正式推出了网易云。“十年•杭研技术秀”系列文章,由杭研研发团队倾情奉献,为您展示杭研那些有用、有趣的技术实践经验,涵盖云计算、大前端、信息安全、运维、QA、大数据、人工智能等领域,涉及前沿的分布式、容器、深度学习等技术。正是这些宝贵的实践经验,造就了今天高品质的网易云产品。本文的分享来自杭研视频云团队,介绍了如何通过mysql共享存储方式实现分布式视频处理系统的高可用方案。

分布式视频处理系统中的Worker、Razer、SDK等模块以无状态方式设计,即Worker应用停止服务或节点宕机都会影响整个系统对于视频的处理。比如有Worker-N应用正在处理转码的任务,到了99%的时候,应用却很不幸地崩溃,导致该转码任务失败。为了保证转码任务能正常结束,让用户不吐槽,我们的节点管理中心(Node Manager)应运而生,负责全程监控转码任务的状态,在碰到系统因素引起的失败时进行任务回收,其他Worker应用重新进行转码。
节点管理中心最核心的功能是各个节点服务器的状态管理,此外还包括用户管理(包括鉴权)、任务的跟踪统计、节点状态变更通知、资源监控、全局配置信息获取以及自身的HA等功能,如图1所示。

图1:节点管理中心功能设计
在设计之初,各个任务节点能不依赖于管理中心独立运行,即管理中心是单点运行状态。但是随着功能的不断完善及设计的不断优化,我们发现单点状态已经连最起码的功能完整性都保证不了,出现了统计数据混乱、Dashbord平台无法使用、监控报警失效、节点失效通知不及时等状况,因此我们对Node Manager提出了高可用性的需求,也就是本文的初衷。
众所周知,在分布式高可用性系统模型方面无非就是中心化和去中心化两种设计方式。中心化的设计,如MySQL的MSS单主双从、MongDB Master、HDFS NameNode、MapReduce JobTracker等,有1个或几个节点承担整个系统的核心元数据及节点管理工作,其他节点都和中心节点交互。这种方式的好处显而易见,数据和管理高度统一,集中在一个地方,容易聚合,就像领导者一样,其他人都服从就好,简单可行。但是缺点是模块高度集中,容易形成性能瓶颈,并且如果出现异常,就可能群龙无首。无中心化的设计,如Cassandra、Zookeeper,系统中不存在一个领导者,节点彼此通信、彼此合作完成任务。好处在于某个节点的异常不会影响整体系统,仅仅是局部不可用。缺点是协议比较复杂,而且需要在各个节点间同步信息。
节点管理中心由于不涉及到用户(2C)的相关操作操作,访问量及并发量都较为有限,所以我们总结出了JDBC Store active/standby的中心化高可用实现方案 - 通过JDBC的方式与database交互,使用database的表级排他锁来实现多节点争抢主机节点,另外还包括节点状态转变(active/standby切换)和客户端的failover机制。下面通过elect leader、status change和client failover分别进行进一步的阐述。

elect leader
elect leader的概念,据我所知是从Zookeeper而来,用于保证集群中Master的可用性和唯一性。我们的高可用性方案是active/standby,但是我实在想不出更好的名词来表达这个争抢主机的过程,本文中涉及于此,都会以elect leader进行描述。
两个节点管理应用同时启动,我们需要确定一个唯一的应用来服务于其他业务节点,在这之前我们需要创建csserver_ha表用于保存主机节点的信息,elect leader的主要流程如图2所示。
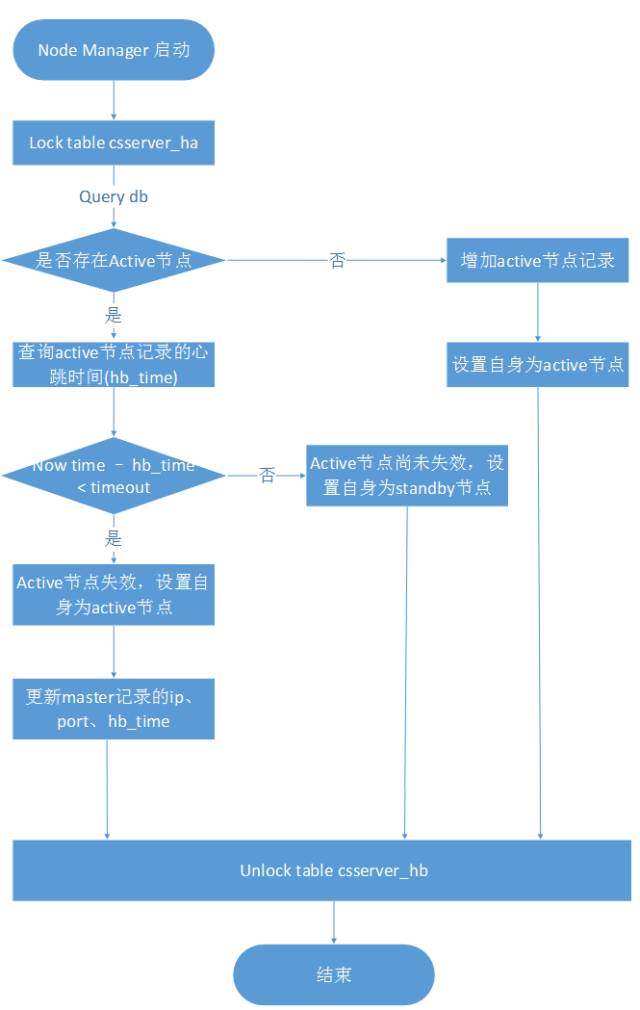
图2:elect leader流程示意图
步骤说明如下:
Lock csserver_ha。
查询csserver_ha中ha_status = ‘active’的记录数。
若结果为0说明首次启动,则往csserver_ha新增一条记录包括该应用所在的IP、port、心跳时间(当前时间),状态为active,然后setActive(this),也就是说把该节点应用设置为主机。
若结果大于0,说明之前已存在过active的节点应用,此时获取状态为active的记录,判断当前和该记录中的心跳时间(hb_time)的差值。
若小于预设值的timeout时间,说明之前存在的active应用尚未失效,则seStandby(this),也就是设置该节点应用为备机。
若大于等于 timeout时间,说明之前存在的active应用已经失效,那么设置该节点应用为主机,即setActive (this)。更新csserver_ha 中active记录的ip、port、hb_time为当前应用信息和当前时间。
Unlock csserver_ha。
Status change
Status change表示节点应用的内部状态转变,分别为dead、active或standby,dead表示节点处于宕机或者应用实例未启动,active表示应用实例为主机,standby表示应用实例为备机。
当主机转变为active时,其他任务单元方能与之正确通信,并且自启动心跳日志记录任务和脑裂检测任务。定时写心跳日志到表csserver_hb中,表示该节点应用尚浅存活。如果集群单元发生“脑裂”,那么会发生存在两个主机节点的情况,其他任务单元提交的数据也被割裂,得不到完整性的保障。在我们的系统中,如果active节点和数据库之间发生网络中断,standby检测到active不可用(假死或者宕机),立即接管服务,转变为active,这个时候就有2个active了,那怎么去规避呢?也就是前文所说的脑裂检测任务,active节点不断地询问standby节点“你是谁?”,如果standby节点回答“I am active”,那么active节点降级成standby节点。另外,如果active节点和standby节点发生网络中断了,这种情况下也可能会出现双active,为了保证系统节点管理中心的唯一性,此时active节点会降级转变成standby节点。
当主机转变为standby时,其他节点与之通信返回“服务不可用”的错误码。standby节点启动针对active节点的健康检测,主要是不断地读取active记录中的心跳时间hb_time,如果和当前时间的差值超出预先设置的timeout时间,则表示active节点不可用, standby节点就切换成active状态。Standby扮演着try get the active的角色。
如果active和standby节点与数据库的网络均处于中断状态,那么意味着节点管理中心集群崩溃。
Client failover
Client failover任务单元访问节点管理中心时需遵循failover:{ip1:port1;ip2:port2}的协议,client端轮询访问IP1和IP2,不需要去区分active和standby,若返回“服务不可用”的状态码,或者网络连接超时,就去重试访问另外一个;如果IP1和IP2均不可用,则说明节点管理中心集群崩溃。
本文仅针对分布式视频处理系统节点管理中心讨论通过MySQL共享存储方式实现高可用方案,其他的实现(例如Keepalived、Zookeeper等)以及文中所涉及的高可用、脑裂、网络分区等概念,请读者可自行Google。
—罗广
网易杭州研究院视频云团队
小编点评:网易云视频云解决方案的底层,是10,000+规模的分布式转码集群,可用性的保障非常重要。本文介绍的方法虽然只是限于节点管理,但网易云秉承网易公司对产品品质的追求,不管是针对直接的用户体验的还是后端的管理,都没有放过各种技术细节的优化,希望累积形成差异化的竞争力。正是因为有了各种不同的深入探索,网易视频云实现了其功能性和非功能性的需求,最终能够为用户提供稳定可靠的服务,并支持千万级用户同时在线。
点击阅读杭研技术秀系列文章:
;
;
以上是关于十年·杭研技术秀 | 分布式转码服务高可用浅析的主要内容,如果未能解决你的问题,请参考以下文章
十年•杭研大咖说 | 邱似峰:从应届生到网易视频云CTO的蜕变
十年•杭研大咖说 | 邱似峰:从应届生到网易视频云CTO的蜕变