分布式一致性在58招聘的实践 Posted 2021-04-24 58技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式一致性在58招聘的实践相关的知识,希望对你有一定的参考价值。
58招聘业务从分类信息演化而来,每天为百万计的求职者和企业主提供服务。
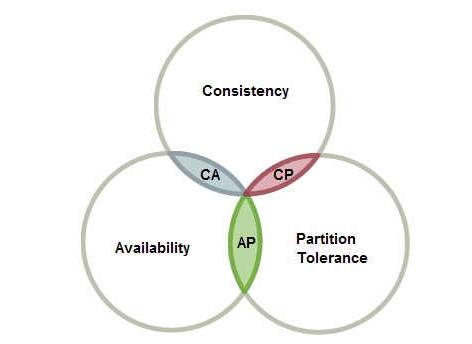
CAP原则 CAP原则指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性: 满足输出结果要强一致性,不能出现中间状态。
可用性: 服务要满足高可用性要求,不管内部出现了什么情况,都要在稳定的时间内返回结果(不管正确与否)。
分区容错性: 在遇到某节点或分区故障的时候,仍然能做到最终结果可靠(不管耗时多久)。
证明:要保证强一致性,节点之间数据同步机制必须是串行,即在内部节点完成数据同步之前,不能对外提供服务。正常状态还好,如果某节点故障或者网络抖动。必然会导致内部整理的逻辑极为复杂。要么快速承认失败不满足分区容错,要么经过漫长等待返回正确结果不满足高可用。即CA和CP二选一。
上边论证的同时也揭示了一个事实:对于高并发的互联网业务来说,CA 和 CP 无法满足。只能牺牲强一致性,使用AP。由此引出BASE理论。
BASE理论
BASE理论:全称由:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写组成,最早由ebay的架构师提出。
基本可用:系统出现意外的时候,响应时间可以做损失。比如业务平时100毫秒,特殊时刻延长到1s。
软状态:系统可以有中间状态,且中间状态能被下游感知到。
最终一致:在某个时间点之后,软状态消失,系统达到最终一致。
BASE理论完全适合互联网业务,兼顾了系统设计和用户体验。柔性架构,保证数据最终准确的同时,也不会因为可用性丢失一个用户。在今天看来,依然充满了莫大的智慧。
日志先行
做过支付相关业务的同学,对下边的三段式代码应该很熟悉。
1) 设计一张日志表,调用之前先记录所有关键信息,并标记为初始状态。
日志先行是必要的:如果不先记录,调用成功后,处理结果时突然宕机。这时没有任何地方知道用户曾经支付过。。。
1)假如在第一步记录信息时宕机,恢复后相当于什么也没发生。
2)假设记录已经写成功,但是状态不对,这时候只要查询接口check一下,成功了认为支付完成并执行下一步,否则标记为支付失败即可。
3)假如状态正确,支付过程完成。那直接执行下一步即可。
TCC
TCC是业界流行的一种逻辑单元代码组织形式,即把一个原子业务分为 :Try、Confirm,Cancel三个部分。
Try阶段:检查前置条件,确保在confirm阶段有资源可用,这样可以最大程度的确保confirm阶段能够执行成功。
etx 框架(easy transcation framework)
是58招聘基于BASE原则实现的分布式最终一致性框架。开发人员完全不需要关心一致性怎么实现,只需要关注每个事务单元的业务逻辑。在事务单元里定义好自己的Try,Confirm和Cancel逻辑后,由框架来把这些单元组织起来,按照日志先行的思想来统一控制它们的顺序执行和反向回滚。最终达到所有业务逻辑要么全部成功,要么全部失败的目的。
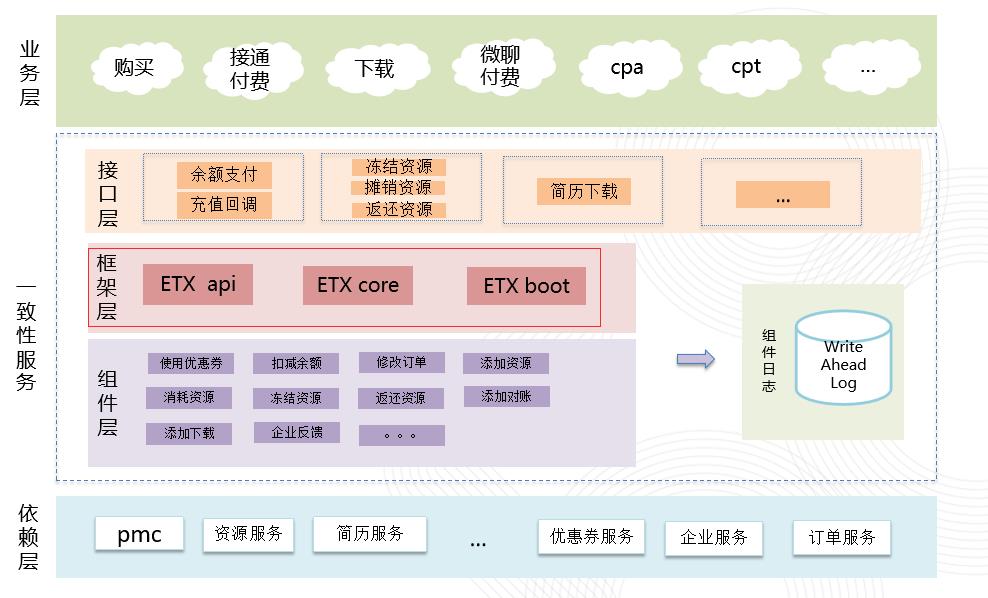
招聘内部根据大的商业方向设计多个etx服务(一致性服务),上游系统只需传入必须的数据,由etx服务保证整个业务的最终一致性。服务返回明确的true和false。下图是简历etx服务在整个系统的位置。
每个etx
服务都是构建在etx框架的基础上。框架把事务全过程抽象成4个状态。INIT(初始),SYNCOK(同步阶段成功),SUCC(最终成功),FAIL(最终失败)。
服务的组件(原子事务单元)需要按照定义好的结构来编写。框架把事务组件分为同步组件和异步组件。同步组件必须实现TCC方法,异步组件只需要实现service方法。
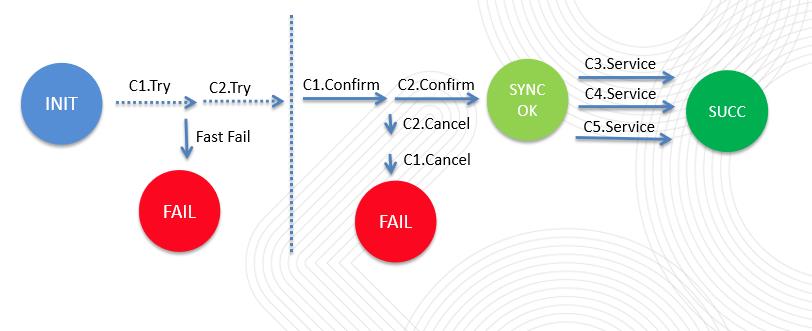
1.首先执行所有同步组件的try方法,有任何一个不通过,则快速返回失败(Fast Fail),事务结束。
2.try阶段通过后,会顺序执行所有组件的confirm方法。
3.如果第二阶段所有组件执行成功,事务状态来到SYNCOK,返回给下游事务执行成功。后续通过异步的方式保证异步组件一定执行完成。
4.如果第二阶段有任何一个组件执行失败,返回给下游事务执行失败,同时在异步线程从该组件开始,往前回滚所有同步组件(逆序执行Cancel方法)。
下图展示了事务的执行过程(c1,c2为同步组件,c3,c4,c5为异步组件)
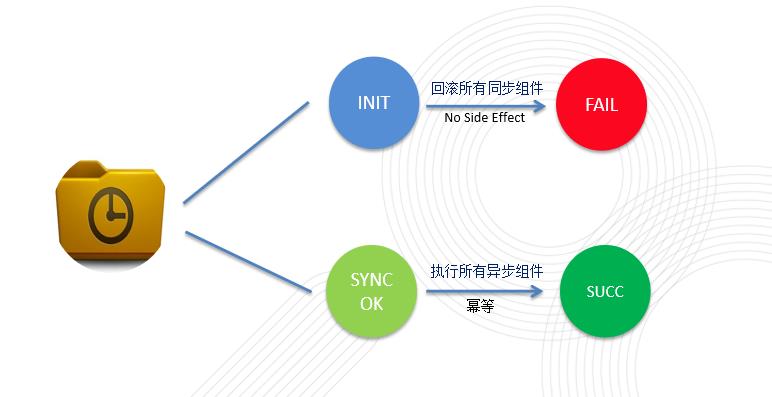
独立的task程序(一般在etx服务的IP择机选择节点部署)不断扫描事务主表记录,如果发现有异步组件没执行完,或者同步组件没有回滚完。(为了性能在主进程这两条链都只执行一遍),则会重新执行异步组件的业务逻辑或者同步组件的回滚逻辑。
1.如果事务是INIT状态,则逆序执行所有同步组件的confirm方法。最终事务状态会来到FAIL
2.如果事务是SYNCOK状态,则执行所有异步组件的service方法。最终事务状态会来到SUCC。
下图展现了框架的恢复过程(cancel方法要求无副作用,service方法要求幂等。)
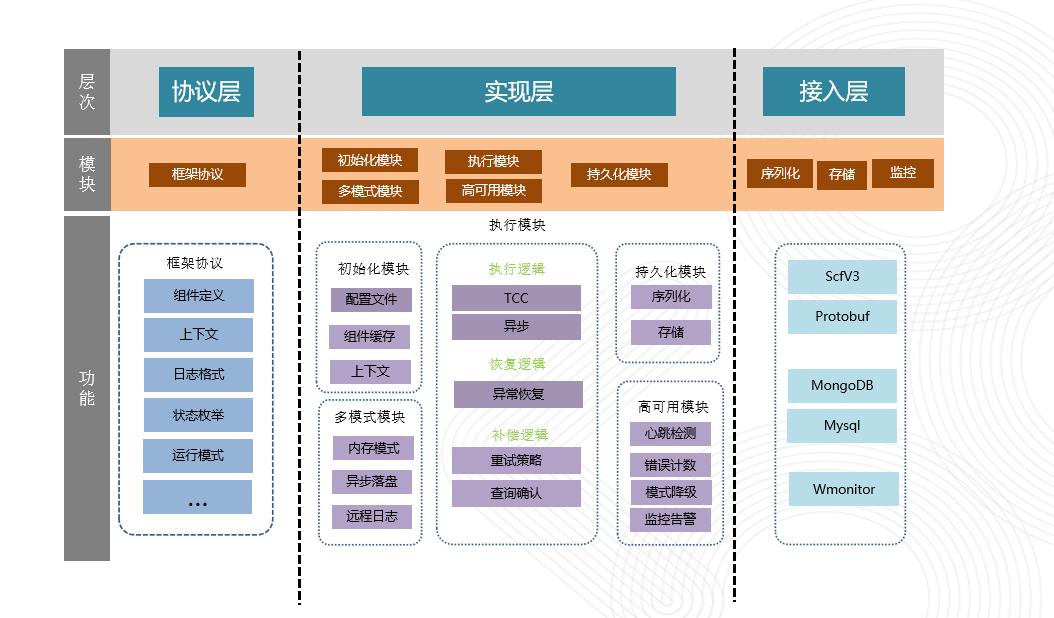
分布式一致性是一个特别广泛的场景。我们期望etx框架是普适的。由于etx本身依赖序列化、持久化。所以我们把整个框架抽象为三层,目的是把这些依赖提取出来,做到可替换,可插拔。
1.协议层
:定义组件的类型,组件执行和回滚用到上下文,存储抽象,序列化抽象,状态枚举等纯接口和协议。考虑到各个公司/部门的基础设施不同,框架把依赖的中间件全部抽象成接口协议。
2.实现层
:框架的核心逻辑,是框架怎么把事务组织起来的实现,这里会把各组件的上下文序列化,并保存到指定的存储系统里,实现了执行过程,回滚过程。同时配置的读取,高可用等代码也在这里。
3.接入层:
序列化、存储、监控等具体实现。我们默认提供了基于58体系的实现(SCFV3序列化 + Mongodb存储 + Wmonitor监控)。接入方只需要根据团队的基础设施,实现自己的接入层即可完成接入。
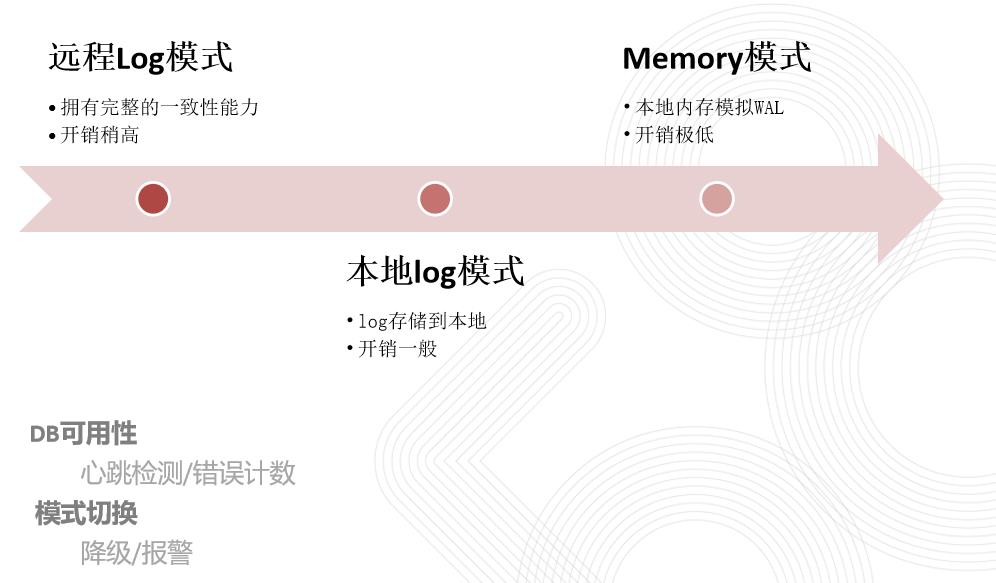
etx有三种运行模式,远程log模式,本地log模式,和纯内存模式(用内存模拟Write Ahead Log)。后两者不能解决宕机问题,但是性能会更好些。业务方根据具体情况选择。如果远程log存储出现故障,框架会有完整的机制来进行模式切换,保障高可用。
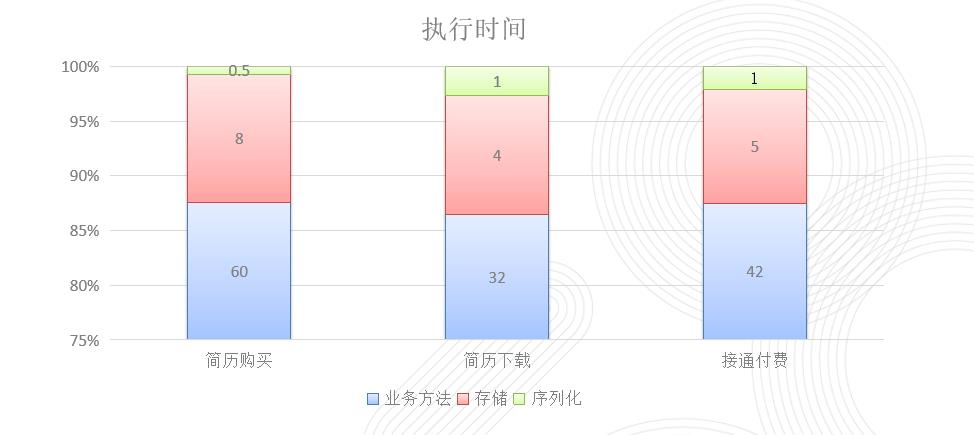
下图是招聘商业线上典型的几个场景(事务链分别为短,中,长)的运行性能。可以看到引入框架的导致时延增加不超过15%。业务上是完全能接受的。
etx框架在招聘内部大规模的使用3年多,一直健壮稳定。bad case从原来的每天几十个下降到0。高峰期每天支持近200万笔的事务和千万级的收入。可用性和最终一致性均达到了6个9以上(99.9999%)。
1.分布式事务之TCC服务设计和实现(https://yq.aliyun.com/articles/620332)
2.CAP理论的理解 (https://www.cnblogs.com/mingorun/p/11025538.html
以上是关于分布式一致性在58招聘的实践的主要内容,如果未能解决你的问题,请参考以下文章