淘宝分布式文件系统TFS设计
Posted 架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了淘宝分布式文件系统TFS设计相关的知识,希望对你有一定的参考价值。
TFS(Taobao File System)是一个高可用、高性能、高可扩展的分布式文件系统,基于普通的Linux服务器构建,主要提供海量非结构化数据存储服务。TFS被广泛地的应用在淘宝的各项业务中,目前已部署的最大集群存储文件数已近千亿。 TFS已在TaoCode上开源 (项目主页:http://code.taobao.org/p/tfs/src/),提供给外部用户使用。
架构简介
TFS集群由名字服务器(namserver)和数据服务器(dataserver)组成,TFS以数据块(block)为单位存储和组织数据,block大小通常为64M(可配置),TFS会将多个小文件存储在同一个block中,并为block建立索引,以便快速在block中定位文件;每个block会存储多个副本到不同的机架上,以保证数据的高可靠性。每个block在集群中拥有全局唯一的数据块编号(block id),block id由nameserver创建时分配,block中的文件拥有一个block内唯一的文件编号(file id),file id由dataserver在存储文件时分配,block id和file id组成的二元组唯一标识一个集群里的文件。
Nameserver服务部署时采用HA来避免单点故障,2台nameserver服务器共享一个vip。正常情况下,主nameserver持有vip提供服务,并将block修改信息同步至备,HA agent负责监控主备nameserver的状态,当其检测到主宕机时,HA agent将vip切换到备上,备就切换为主来接管服务,以保证服务的高可用。
Dataserver服务部署时通常会在一台机器上部署多个dataserver进程,每个进程管理一块磁盘,以便充分利用磁盘IO资源。Dataserver启动后,会向nameserver汇报其存储的所有block信息,并周期性的给nameserver发送心跳信息,nameserver则根据心跳来管理所有的dataserver,当nameserver超过一定时间没有收到dataserver的信息,则认为dataserver已经宕机,会将该dataserver上存储的block进行复制,使得block副本数不低于集群配置值,保证系统存储数据的可靠性。
存储机制
Namserver上的所有元信息都保存在内存,并不进行持久化存储,dataserver启动后,会汇报其拥有的block信息给nameserver,nameserver根据这些信息来构建block到server的映射关系表,根据该映射关系表,为写请求分配可写的block,为读请求查询block的位置信息。Nameserver有专门的后台线程轮询各个block和server的状态,在发现block缺少副本时复制block(通常是由dataserver宕机导致的);在发现dataserver负载不均衡时,迁移数据来保证服务器间的负载均衡。
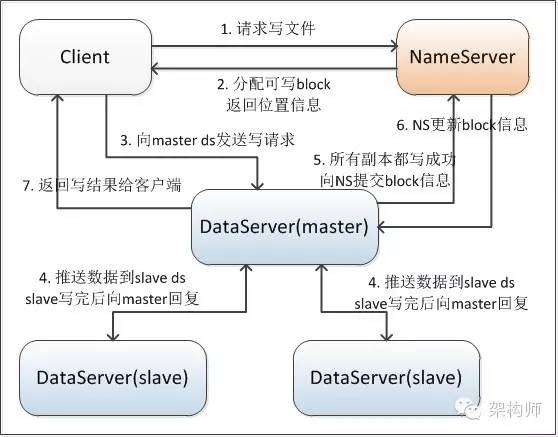
TFS写文件流程如上图所示,nameserver在分配可写block时,简单的采用round robin的策略分配,这种策略简单有效,其他根据dataserver负载来分配的策略,实现上较复杂,同时由于负载信息不是实时的,根据过时的信息来分配block,实践证明其均衡效果并不好。当文件成功写到多个dataserver后,会向client返回一个由集群号、block id、file id编码而成的文件名,以后client通过该文件名即可从TFS访问到存储的文件,在dataserver上,每个block对应一个索引文件,索引中记录了block中每个文件在block内部的偏移位置以及文件的大小。
当client读取文件时,首先根据文件名解析出文件所在的block信息,从nameserver上查询block所在的dataserver信息,并向dataserver发送读请求,如果从某个副本读取失败,client会重试其他的副本;dataserver接收到client的读请求时,通过查找block的索引就能快速得到文件的位置,从block相应位置读取数据并返回给client。
当client删除TFS里的文件时,服务器端并不会立即将文件数据从block里删除掉,只是为文件设置一个删除标记,当一个block内被删除的文件数量超过一定比例时,会对block进行整理(compact),以回收删除文件占用的空间,删除任务通常在访问低峰期进行,以避免其对正常的服务造成影响。
Client负责完成读写删TFS文件的基本逻辑,并在失败时主动进行failover。为了提高client读取文件的效率、并降低nameserver的负载,client会将block到dataserver的映射关系缓存到本地,由于block到dataserver的映射关系一般只会在发生数据迁移的时候才会发生变化,所以一旦本地cache命中,大部分情况下都能从cache里获取到的dataserver上访问到文件,如果cache已经失效(block被迁移到其他dataserver),客户端最终会从nameserver获取block最新的位置信息,从最新的位置上读取文件。在实际应用中,通常客户端能使用的系统资源比较有限,能够用于本地缓存的内存并不大,而集群中block的数量有数千万,从而导致本地缓存的命中率并不高,为此TFS还支持远端缓存,将block到dataserver的映射关系缓存在tair中(tair是淘宝开源的分布式key/value存储系统,http://code.taobao.org/p/tair/wiki/intro/),应用tair缓存的命中率非常高,使得绝大部分的读请求都不需要经过nameserver。
根据业务的需求,TFS还实现了对自定义文件名和大文件存储的支持,支持这两种业务场景并没有改变TFS服务器端的存储机制,而是通过提供新的服务、封装client来实现。对于自定义名的存储服务,TFS提供单独的元数据服务器(metaserver)来管理自定义文件名到TFS文件名的映射关系,当用户存储一个指定文件名的文件时,client首先将其存储到TFS中,得到一个由TFS分配的文件名,然后将用户指定的文件名与TFS文件名的映射关系,存储到metaserver,当读取自定文件名文件时,则会先从metaserver查询该文件名对应的TFS文件名,然后从TFS里读取文件。对于大文件的存储,client会将大文件切分为多个小文件(通常每个2M)分片,并将每个分片都存储到TFS,得到多个文件名,然后将多个文件名作为新的文件数据存储到TFS,得到一个新的文件名(该文件名与正常的TFS文件有着不同的前缀,以区分其存储的是大文件的分片信息),当用户访问大文件时,client会先读出各个分片对应的TFS文件名信息,再从TFS里读出各个分片的数据,重新组合成大文件。
TFS提供了标准的C++客户端供开发者使用,同时由于淘宝内部业务主要使用java进行开发,因此TFS也提供了java客户端,每增加一门新语言的支持,都是在重复的实现客户端访问后端服务器的逻辑。当客户端发布给用户使用后,一旦发现bug,需要通知已经在使用的数百个应用来升级客户端,升级成本非常之高。TFS通过开发nginx客户端模块(已在github开源,https://github.com/alibaba/nginx-tfs)来解决该问题,该模块代理所有的TFS读写请求,向用户提供restful的访问接口,nginx模块上线使用后,TFS的所有组件升级都能做到对用户透明,同时需要支持一门新语言访问TFS的成本也变得非常低,只需要按照协议向nginx代理发送http请求即可。
平滑扩容
对于存储系统而言,除了保证数据的可靠存储外,支持容量扩展也至关重要。TFS对集群的扩容支持非常友好,当集群需要扩容时,运维人员只需要准备好扩容的新机器,部署dataserver的运行环境,启动dataserver服务即可,当nameserver感知到新的dataserver加入集群时,会在新的dataserver上创建一批block用于提供写操作,此时新扩容的dataserver就可以开始提供读写服务了。
由于TFS前端有淘宝CDN缓存数据,最终回源到TFS上的文件访问请求非常随机,基本不存在文件热点现象, 所以dataserver的负载与其存储的总数据量基本呈正比关系。当新dataserver加入集群时,其容量使用上与集群里其他的dataserver差距很大,因此负载上差距也很大,针对这种情况nameserver会对整个集群进行负载均衡,将部分数据从容量较高的dataserver迁移到新扩容的dataserver里,最终使得集群里所有dataserver的容量使用情况保持在一个尽量接近的水位线上,让整个集群的服务效率最大化。
机房容灾
TFS集群通过多副本机制来保证数据的可靠性,同时支持多机房容灾,具体做法是在多个机房各部署一个TFS物理集群,多个物理集群的数据通过集群间的同步机制来保证数据互为镜像,构成一个大的逻辑集群。
典型的逻辑集群部署方式为一主多备,如上图所示,主集群同时提供读写服务,备集群只提供读服务,主集群上存储的所有文件都会由对应的dataserver记录同步日志,日志包含文件的block id和fileid以及文件操作类型(写、删除等),并由dataserver的后台线程重放日志,将日志里的文件操作应用到备集群上,保证主备集群上存储的文件数据保持一致的状态。
对于异地机房的容灾,如果多个机房的应用都对所在机房的TFS集群有写操作,则需要采用多个主集群的部署方式,即逻辑集群里每个物理集群是对等的,同时对外提供读写服务,并将写操作同步到其他的物理集群。为了避免多个主集群同时写一个block造成的写冲突,每个主集群按照指定的规则分配block id用于写操作,以两个主集群为例,1号主集群在写文件时只分配奇数号的block id,而2号主集群在写文件时只分配偶数号的block id;针对奇数号block的写操作由1号集群向2号集群同步,而针对偶数号block的写操作由2号集群向1号集群同步。
对于支持多机房容灾的集群,TFS客户端提供了failover的支持,客户端读取文件时,会选择离自己最近的物理集群进行读取,如果读取不到文件(该物理集群可能是备集群,该文件还没有从主集群同步过来),客户端会尝试从其他的物理集群读取文件。
运维管理
TFS在淘宝内部部署有多个集群、上千台服务器,有数百个应用访问,TFS将所有的资源信息存储在mysql数据库里,通过资源管理服务器(rcserver)进行统一的管理。
独立的多个集群在配置上通常是不同的,比如有的集群要求block存储2个副本,而有的集群则要求更高的可靠性,每个block存储3个副本,为了避免配置文件错误,每个集群的在mysql数据库里都有一套配置模板,在机器上线时,直接根据模板来生成配置文件。
每个集群的部署信息会在集群上线时由运维管理人员添加到mysql数据库里,比如一个逻辑集群里有哪些物理集群,每个物理集群的访问权限等,当内部应用需要使用TFS时,TFS会给每个应用分配一个appkey,同时根据应用的需求为其分配集群存储资源。 当TFS客户端启动时,会根据appkey从rcserver上获取应用的所有配置信息,根据配置信息来访问TFS的服务;client与rcserver间会周期性的keepalive, client将应用读写文件的统计信息汇报给rcserver,rcserver将针对该应用的最新配置信息带回给client。比如当某个集群出现重大问题时,可以修改mysql的配置,将应用切换到正常的集群上访问。
为了尽早发现问题,运维人员会在所有的TFS机器上部署监控程序,监视服务器的服务状态、监控集群的容量使用情况等,当发现有磁盘或机器故障时,自动将其下线;当发现集群的容量使用超过警戒线时,主动进行扩容。
未来工作
TFS主要发展方向一直是在保证数据可靠性的基础上提高服务效率、降低存储以及运维成本。目前TFS正准备将Erasure code技术应用到系统中,用于代替传统的副本备份策略,该项目的上线预计会使得TFS的存储成本降低25%-50%。
注:本文首发于ChinaUnix《IT架构实录》,转载请注明。
来源:http://blog.chinaunix.net/uid-20196318-id-3904914.html
·END·
以上是关于淘宝分布式文件系统TFS设计的主要内容,如果未能解决你的问题,请参考以下文章