八十八页MooseFS超实用手册--目前开源的几种分布式文件系统及MooseFS介绍
Posted 云技术实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了八十八页MooseFS超实用手册--目前开源的几种分布式文件系统及MooseFS介绍相关的知识,希望对你有一定的参考价值。
说明:部分内容来自于互联网和官方手册。
目前开源的几种分布式文件系统
与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。
1、 MooseFS易用,稳定,对小文件很高效。
2、 MogileFS 据说对于 Web 2.0 应用存储图片啥的很好。
3、 GlusterFS 感觉广告宣传做的比产品本身好。
4、 OpenAFS/Coda 是很有特色的东西。
5、 Lustre 复杂,高效,适合大型集群。
6、 PVFS2 搭配定制应用会很好,据说曙光的并行文件系统就是基于 PVFS。
各文件系统的简单描述及用途
2.1 dCache
- 依赖 PostgreSQL
2.2 xtreemfs
* 服务端是 Java 实现的
- 性能不高
2.4 CloudStore (KosmosFS)
+ 被 Hadoop 作为分布式文件系统后端之一
- 不支持文件元信息
- kfs_fuse 太慢,不可用
- 编译依赖多,文档落后,脚本简陋
- 开发不活跃
2.5 MooseFS
+ 支持文件元信息
+ mfsmount 很好用
+ 编译依赖少,文档全,默认配置很好
+ mfshdd.cfg 加 * 的条目会被转移到其它chunkserver,以便chunkserver 安全 退出
+ 不要求 chunk server 使用的文件系统格式以及容量一致
+ 开发很活跃
+ 可以以非 root 用户身份运行
+ 可以在线扩容
+ 支持回收站
+ 支持快照
- master server 存在单点故障
- master server 很耗内存
2.6 MogileFS
- 不适合做通用文件系统,适合存储静态只读小文件,比如图片
2.7GlusterFS (http://gluster.com/community/documentation/index.php/GlusterFS_Features)
+ 无单点故障问题
+ 支持回收站
+ 模块化堆叠式架构
- 对文件系统格式有要求,ext3/ext4/zfs 被正式支持,xfs/jfs 可能可以,reiserfs 经测试可以
(http://gluster.com/community/documentation/index.php/Storage_Server_Installation_and_Configuration#Operating_System_Requirements)
- 需要以 root 用户身份运行(用了 trusted xattr,mount 时加 user_xattr 选项是没用的,官方说法是glusterfsd 需要创建不同属主的文件,所以必需 root 权限)
- 不能在线扩容(必须通过umount 增加存储节点),计划在 3.1 里实现
- 分布存储以文件为单位,条带化分布存储不成熟
2.8 GFS2
http://sourceware.org/cluster/wiki/DRBD_Cookbook
http://www.smop.co.uk/blog/index.php/2008/02/11/gfs-goodgrief-wheres-th e-documentation-file-system/
http://wiki.debian.org/kristian_jerpetjoen
http://longvnit.com/blog/?p=941
http://blog.chinaunix.net/u1/53728/showart_1073271.html (基于红帽RHEL5U2 GFS2+ISCSI+XEN+Cluster 的高可性解决方案)
http://www.yubo.org/blog/?p=27 (iscsi+clvm+gfs2+xen+Cluster)
http://linux.chinaunix.net/bbs/thread-777867-1-1.html
* 并不是 distributed file system, 而是 shared disk cluster file system,需要某种机制在机器之间共享磁盘,以及加锁机制,因此需要 drbd/iscsi/clvm/ddraid/gnbd 做磁盘共享,以及 dlm 做锁管理)
- 依赖 Red Hat Cluster Suite (Debian: aptitude install redhat-cluster-suite, 图形配置工具包
system-config-cluster, system-config-lvm)
- 适合不超过约 30 个节点左右的小型集群,规模越大,dlm 的开销越大,默认配置 8 个节点,dlm锁必须通过内核编译才能够打开内核的支持;
2.9 OCFS2
* GFS 的 Oracle 翻版,据说性能比 GFS2 好 (Debian: aptitude install ocfs2-tools, 图形配置工具包 ocfs2console)
- 不支持 ACL、flock,只是为了 Oracle database 设计
2.10 OpenAFS
+ 成熟稳定
+ 开发活跃,支持 Unix/Linux/MacOS X/Windows
- 性能不够好
2.11 Coda
* 从服务器复制文件到本地,文件读写是本地操作因此很高效
* 文件关闭后发送到服务器
+ 支持离线操作,连线后再同步到服务器上
- 缓存基于文件,不是基于数据块,打开文件时需要等待从服务器缓存到本地完毕
- 并发写有版本冲突问题
- 并发读有极大的延迟,需要等某个 client 关闭文件,比如不适合 tail -f some.log
- 研究项目,不够成熟,使用不广
2.12 PVFS2
http://blog.csdn.net/yfw418/archive/2007/07/06/1680930.aspx
* 高性能
- 没有锁机制,不符合 POSIX 语意,需要应用的配合,不适合做通用文件系统
(See pvfs2-guide chaper 5: PVFS2 User APIs and Semantics)
- 静态配置,不能动态扩展
2.13 Lustre
* 适合大型集群
+ 很高性能
+ 支持动态扩展
- 需要对内核打补丁,深度依赖 Linux 内核和 ext3 文件系统
2.14 Hadoop HDFS
* 本地写缓存,够一定大小 (64 MB) 时传给服务器
- 不适合通用文件系统
2.15 FastDFS
- 只能通过 API 使用,不支持 fuse
2.16 NFSv4 Referrals
+ 简单
- 没有负载均衡,容错
2.17 NFSv4.1 pNFS
- 没有普及
2.18 spNFS
* pNFS 在 Linux 上的一个实现
2.19 Ceph (http://ceph.newdream.net/)
- 开发初期,不稳定
- 依赖 btrfs
2.20 GFarm (http://datafarm.apgrid.org/software/)
OBFS
Mfs的设计思想完全来源于google filesystem。使用了主从式的服务器架构:
特性:
数据容错
大文件分块
负载均衡
文件系统安全
使用posix文件属性(文件读写权限)
Ip/password控制访问
二、System Architecture(系统架构)
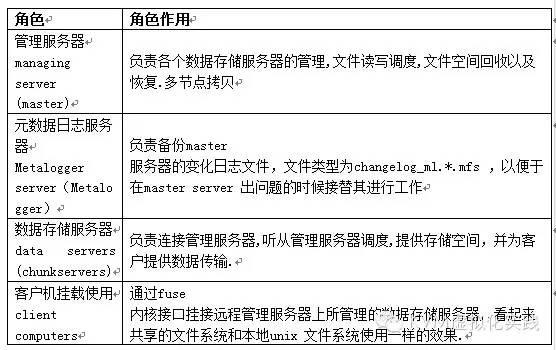
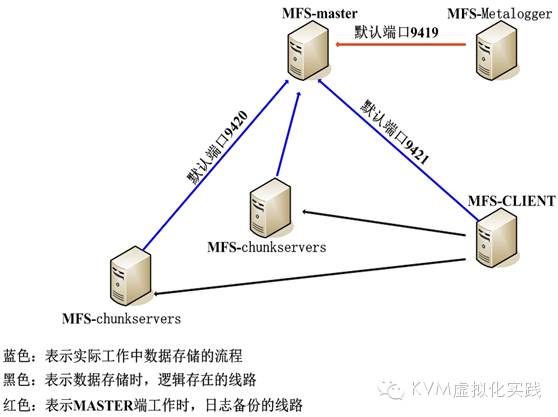
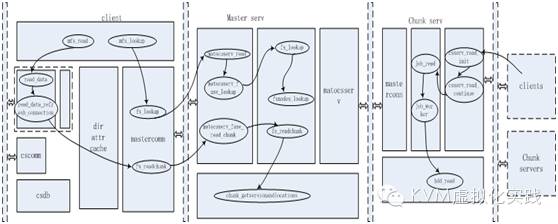
2.1 系统架构图:
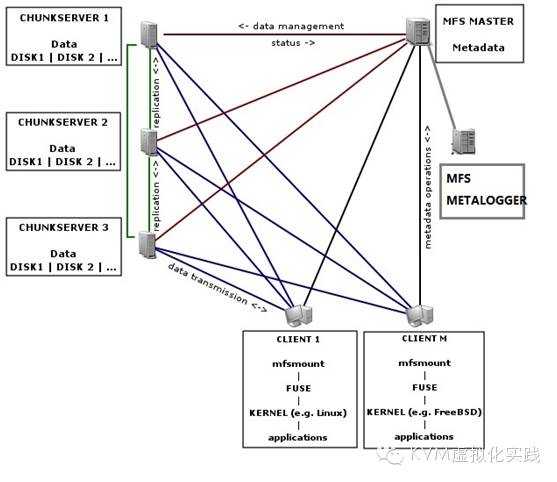
服务端的映射图:
服务端所涉及的函数如下:
通过 matocuserv_read函数读取包的内容
调用matocuserv_gotpacket解析操作的类型
并调用相应的操作函数。如 client发出open操作,master接收到并调用操作函数函数matocuserv_fuse_open()执行。
调用 filesystem.c中的相应函数fs_open()
filesystem.c文件定义了整个文件系统的抽象
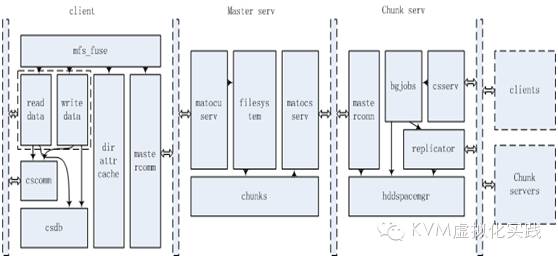
客户端所涉及的函数结构有以下:
Mfs_fuse.c模块是client操作的起点,提供了对文件的操作函数。Fuse正式调用这些接口与mfs进行交互。通常这些操作函数都是调用mastercomm.c中提供的接口函数与master通信,从而获取文件与文件系统信息,以及开始文件的操作。
Mastercomm.c模块将前面文件的操作进行封装,然后将数据包发送到Master服务器,并且负责接收Master返回的数据包并解析之。
Dirattrcache.c模块将文件系统信息进行缓存。下次可以直接使用缓存的文件信息,而不用再次与master进行通信。
Readdata.c和writedata.c两个模块定义了真正读写数据的操作。此时是从chunk server上读写chunk,并且将chunk组装成完整的文件。在写操作的时候,使用了单独的线程处理数据的传输。
Cscomm.c和csdb.c两个文件都是与chunk有关,处理读取和写入的chunk信息。
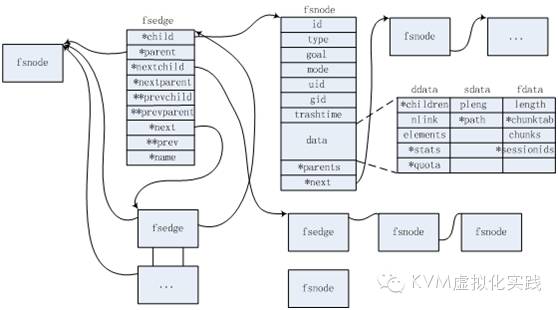
chunks.c定义了chunk的操作以及fsnode到chunk的映射关系。
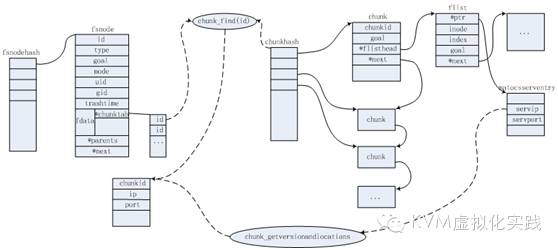
这个模块定义了Master与Chunk Server通信的方法,用于管理和控制Chunk Server对chunk的操作。
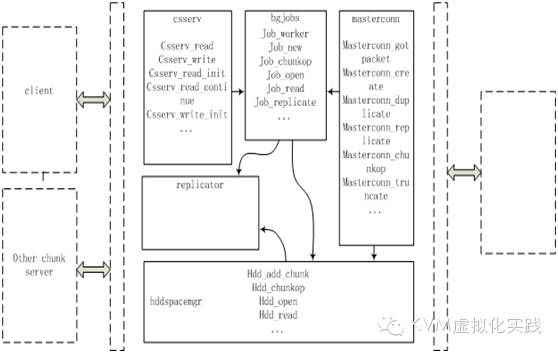
Chunkserver结构
Csserv.c定义了与Client和其他Chunk Server的通信。主要是将接收到的包进行解开,提取其中的操作类型,然后调用bgjobs.c中相应的操作方法。
Bgjobs.c定义了job的操作方法。这个模块中将接收到的操作封装成为一个个job,插入到job pool队列中。然后job_worker线程从队列中取出job进行实际操作。
Hddspacemgr.c定义了最终读写磁盘的操作,管理着磁盘上的chunks。前面job_worker线程最终都调用这个模块中的方法进行实际操作。
Masterconn.c定义了Chunk Server与master进行通信的机制,类似于csserv。
Replicator.c比较简单,就是将特定的chunk复制到其他的chunk server上,达到数据容错的目的。
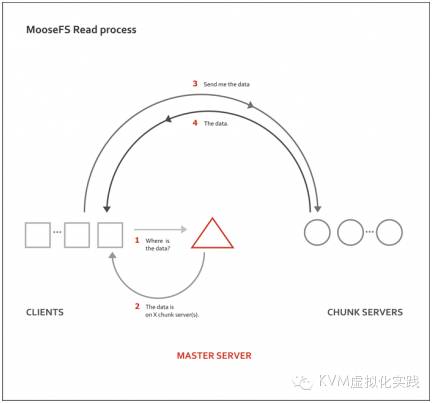
2.2 MFS读取工作过程示意图:
2.3 MFS写入示意图
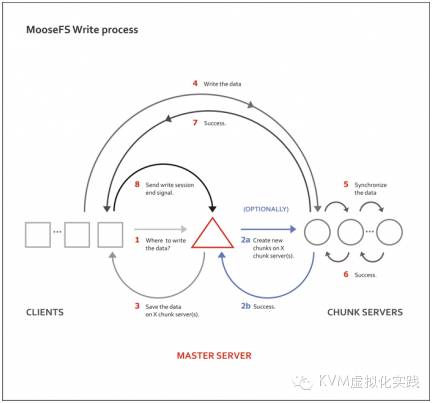
------------------------------------------------------------
最近发现订阅号的文档被不停的抄袭,很无奈。
请支持原创,支持原创可以评论,可以和作者交互。
关注我的订阅号(微信搜索kvm_virt),二维码是:
(请长按关注)
欢迎虚拟化技术爱好者加入,加入方式:
群号码:434720759 密码:大写的KVM
以上是关于八十八页MooseFS超实用手册--目前开源的几种分布式文件系统及MooseFS介绍的主要内容,如果未能解决你的问题,请参考以下文章