轻松搭建分布式文件系统
Posted 架构师之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻松搭建分布式文件系统相关的知识,希望对你有一定的参考价值。
需求
用户在登录之后可以上传文件,也可以看到所有上传的文件(自己或其他用户上传的文件),并可以下载这些文件。
该系统由服务器集群(多节点)实现,每个节点能够为多个客户连接请求提供响应,当应用请求较多、节点平均负载较大时,系统会启用新的节点;当集群的总体请求量较少时,应当逐步关闭节点。
每个服务器节点都有自己的存储空间,可以保存客户上传的文件。
所有在线客户应当实时获得系统中文件信息的更新。
每个服务器节点都可能是不可靠的,k个节点故障(网络中断、节点关闭、节点崩溃……)不会对系统产生影响并介绍了如何设计、实现以及可靠性的分析等内容。
系统分析与设计
根据需求可以看出,这套系统至少可以分为前后端两个部分:
后端拥有一套高可用、可扩展的分布式存储服务
前端可以为用户(Human)提供服务。
其中,分布式存储服务又可以进一步分成两个部分:
分布式文件存储 提供真正的存储服务,我们期望它能存储从KB到GB级别的文件。为每个文件做2份以上的备份,并能通过一个 File ID 索引文件。
分布式文件索引 另一部分提供索引和查询服务,例如获取一个文件夹下所有的文件。对于某个文件(例如 /foo/bar.txt),能够得到它的File ID。索引相比单个文件更为重要,需要更为安全的高可用解决方案。
下面对三个部分做具体的分析和设计。
文件索引数据库(Meta Store)
文件索引是文件名(包含路径)到 File ID 的映射,是一个典型的 Key-Value 数据库。它至少需要支持以下方法:
Put 新增或更新一个Key对应的Value
Delete 删除一个Key以及对应的Value
除此以外,文件的Metadata例如修改日期、大小等也应该存在索引中,便于List时快速获取到这些信息。因时间关系,本次实验中没有去实现。
文件索引是系统中的最重要的部分,如果索引丢失,用户无法从API或UI上查询到任何关于File ID的信息,即使此时文件仍然存在,也会和消失没有什么区别。
幸运的是,文件索引的大小相比文件本身很小,可以方便的使用多副本的方式来保证数据不丢失,实现高可用。但是多副本带来的代价就是需要维护多个副本的数据一致性。
Raft 一致性算法可以帮我们完成这件事。即使在部分副本宕机的情况下,剩余的副本可以继续对外提供服务,并保证当机和恢复的过程都不会破坏多副本的一致性。
使用 Raft 一致性算法的 Key-Value 数据库有 ETCD、Redis Sentinel 等。综合考虑后,选用 Redis Sentinel 作为高可用文件索引的方案。因为 Redis Sentinel 只提供了 Master 选举和切换功能,我们还需要一个代理来将 Redis 连接分发到正确的 Master 上,例如轻量级的 twemproxy。
文件对象存储(File Store)
文件存储负责存储文件对象,并至少在不同的节点上保留一个备份。只要有一个备份可用,就能通过API获得文件。它至少需要支持以下方法:
Post 新增一个文件,并返回 File ID
Delete 根据 File ID 移除一个文件
注意到,因为我们的设计分离了 Metadata 和文件本身,诸如 Move、Rename、Update 等操作都无需支持,只要专注于新增和删除文件即可。这大大简化了设计的复杂性。
我们这里采用较为简单的双备份的模式,即接收到文件后,随机选择两个不同的节点,各存储一份。同样的,当发现节点内文件丢失时,立即再复制一份以保证拷贝数等于2。这样做的缺点是无法进行纠错,我们简单的假设节点自身的文件系统已经帮我们做好了这件事。
那这里是否需要维护副本的数据一致性呢?因为操作已经很简单,并且 Metadata 全部在 Meta Store 中,这里的一致性维护工作变得容易了:
存储集群是一个 Master-Slave 架构。如果 Slave 节点当机,那么 Master 上的双备份机制已经可以很好的处理;如果很不幸地 Master 节点意外终止,那需要一个额外的 Failover 机制来保证一个新的 Master 被选出,接替原来 Master 的工作。这一过程恰好是 Raft 一致性算法中 Master 选举的过程。
符合要求的开源项目很多,最终我们选用了较为轻量级、但性能占优的 SeaweedFS 作为存储后端。
文件系统接口(Filer)
文件系统是本实验的主要模块。我们需要编写代码,实现一个支持以下操作的文件系统:
CreateFile 创建文件
DeleteFile 删除文件
ListFiles 列出某个目录下的文件
CreateDirectory 创建目录
DeleteDirectory 删除目录
ListDirectories 列出某个目录下的目录
此外,需要提供一个简单的用户界面,便于用户使用。
以存储一个文件 /foo/bar.txt 为例,需要经过以下步骤:
检查目录
/foo是否存在;如果不存在,需要创建目录,并把新目录加入 / 的目录树中。检查文件
/foo/bar.txt是否存在;如果存在,则先从 File Store 中删除文件。上传文件
bar.txt到 File Store,得到 File ID。存储条目
/foo/bar.txt到 Meta Store,并加入到/foo/的目录树中。
对于文件的索引,很自然的,将/path/to/file 映射到 File ID 即可。对于目录树的存储则稍复杂一些。
使用前缀查询是无法满足多级目录树的需求的。我们在 Redis 中创建如下的条目以储存目录结构,来满足 ListFiles 和 ListDirectories 的需求:
目录的目录:
/path/to/dir->{foo_dir:dirId1, bar_dir:dirId2, ...}文件的目录:
/path/to/dir->{foo_file:fileId1, bar_file:fileId2, ...}
此外,为了方便使用,引用一个开源的网页文件管理器 angular-filemanager 作为用户界面。我们仅需实现对应的后端 API 即可。
Filer 本身是无状态的,所以很容易实现根据负载做 Auto Scaling。但实践中发现,Auto Scaling需要基础架构的支持,例如 VMware 虚拟机集群或 AWS 云服务,所以没有在本机(minikube)上试验。
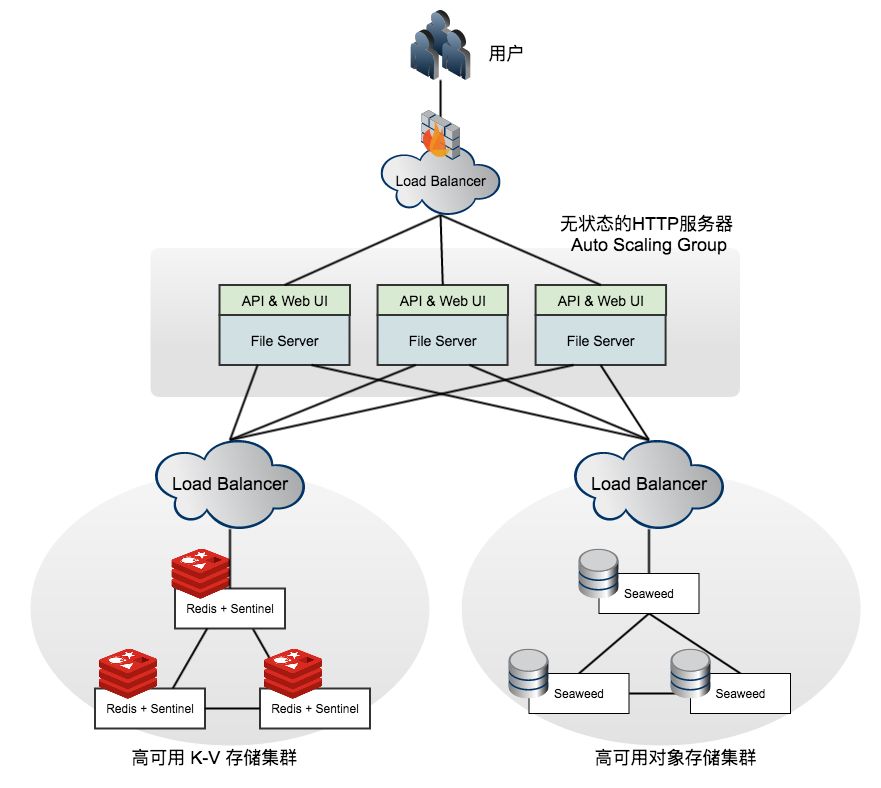
完整架构
以下是分布式文件系统项目的整体架构。系统使用 Docker + Kubernetes 来管理各个服务和节点,配合相关工具,很容易在 AWS 或 GCE 上部署。
实现演示
✦ ✦ ✦ ✦ ✦ ✦ ✦ ✦
原文:https://ericfu.me/build-distributed-file-system/
喜欢我们的会点赞,爱我们的会分享!
企业级架构、系统开发架构、web架构、大规模分布式、高可用高性能架构研究探讨、结合互联网应用技术的动态扩展架构,讨论各类中间件如ActiveMq,Zookeeper,Dubbo,Kafka,关注java、python、node.js、shell、plsql等开发语言,敢于探索,关注最新IT资讯。
(关注ID:TravelWithFrame)
(如有侵权,请联系我们删除)
以上是关于轻松搭建分布式文件系统的主要内容,如果未能解决你的问题,请参考以下文章