码农心得 | 分布式文件系统的备份
Posted 擎创夏洛克AIOps
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了码农心得 | 分布式文件系统的备份相关的知识,希望对你有一定的参考价值。
这几年一直在做大数据的项目,一类是基于MapReduce的报表统计系统;另一类是基于ELK的日志分析系统。这两类系统的底层都用到了HDFS即Hadoop分布式文件系统(Hadoop Distributed File System)。
在项目实施过程中,小编最常被问到的问题就是如何备份HDFS。
首先我们先来普及一些HDFS的基本知识,作为一个分布式文件系统,HDFS本身就是自带冗余的,任何一个数据块都有三个副本(可以在hdfs-site.xml文件中设置副本数量),同时当服务器分布在有多个机架时,副本也会跨机架部署。但HDFS默认无法跨数据中心部署,这是由其最初版本“Google FS”在产品设计时就定义好的。原因有以下几点:
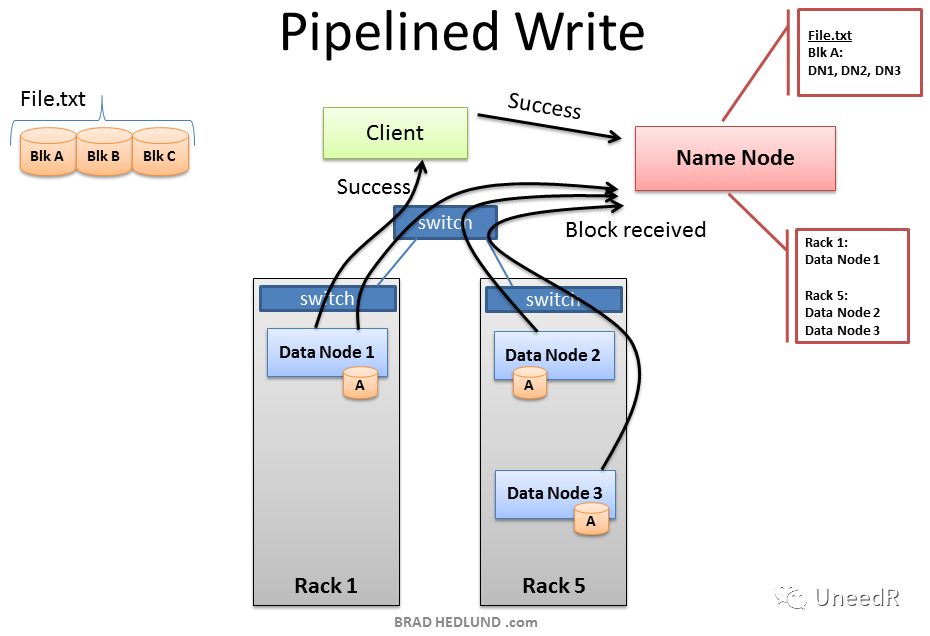
写入数据时对带宽的要求。每当数据写入HDFS时,由于复制机制的关系,需要在另一数据中心同步一份副本。数据流以数据块的形式逐一写入HDFS,每一个数据块都会分布在三个数据节点,其中至少一个是在另一个机架上。而如果HDFS跨站点部署也就意味着站点间带宽将严重影响到数据写入的等待时间(而原来只是机架间的交换机所决定)。
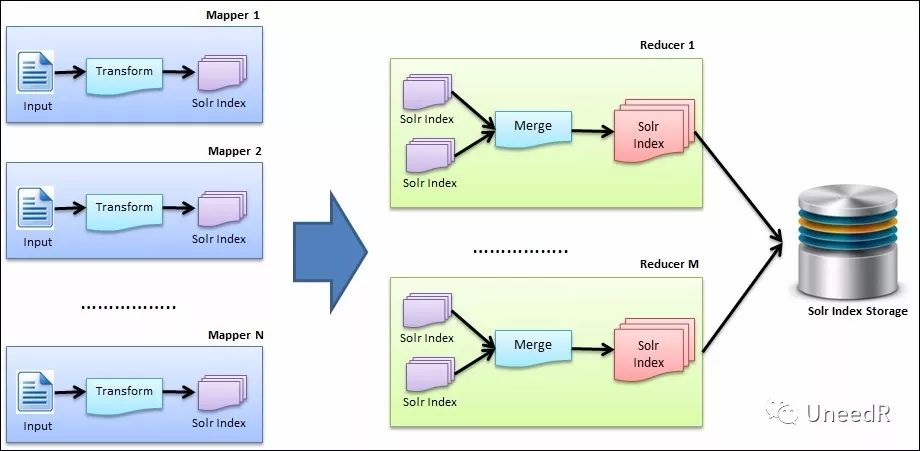
MapReduce的Shuffle对带宽的要求。对于一台分布式的YARN集群,可能存在Mapper分布在不同数据中心的情况,但是对于任何一台Reducer而言,它需要读取所有Mapper节点的数据处理结果。我们假设两个数据中心的Mapper是平均分布的,那就会造成50%的数据处理结果是需要跨站点传输的,再加上有时Mapper的输出数据量会大过输入数据,因此这部分网络开销会严重影响MR的运行速度。
既然HDFS不适合跨站点部署(即不适合通过灾备站点恢复服务),那本地备份就显得尤为重要。常用的HDFS管理工具有Cloudera Manager、IBM Data Server Manager,都可以通过图形界面进行备份。
据我所知上述两个工具都是收费的,我所要讲的备份方法是通过distcp(distributed copy)命令讲hdfs数据从一个集群拷贝到另一个集群。他的局限在于需要停机做备份。所以一般用于大版本的升级或将数据迁移到新的硬件时,所用到的命令是hadoop distcp。
首先我们来看下这个命令的帮助。

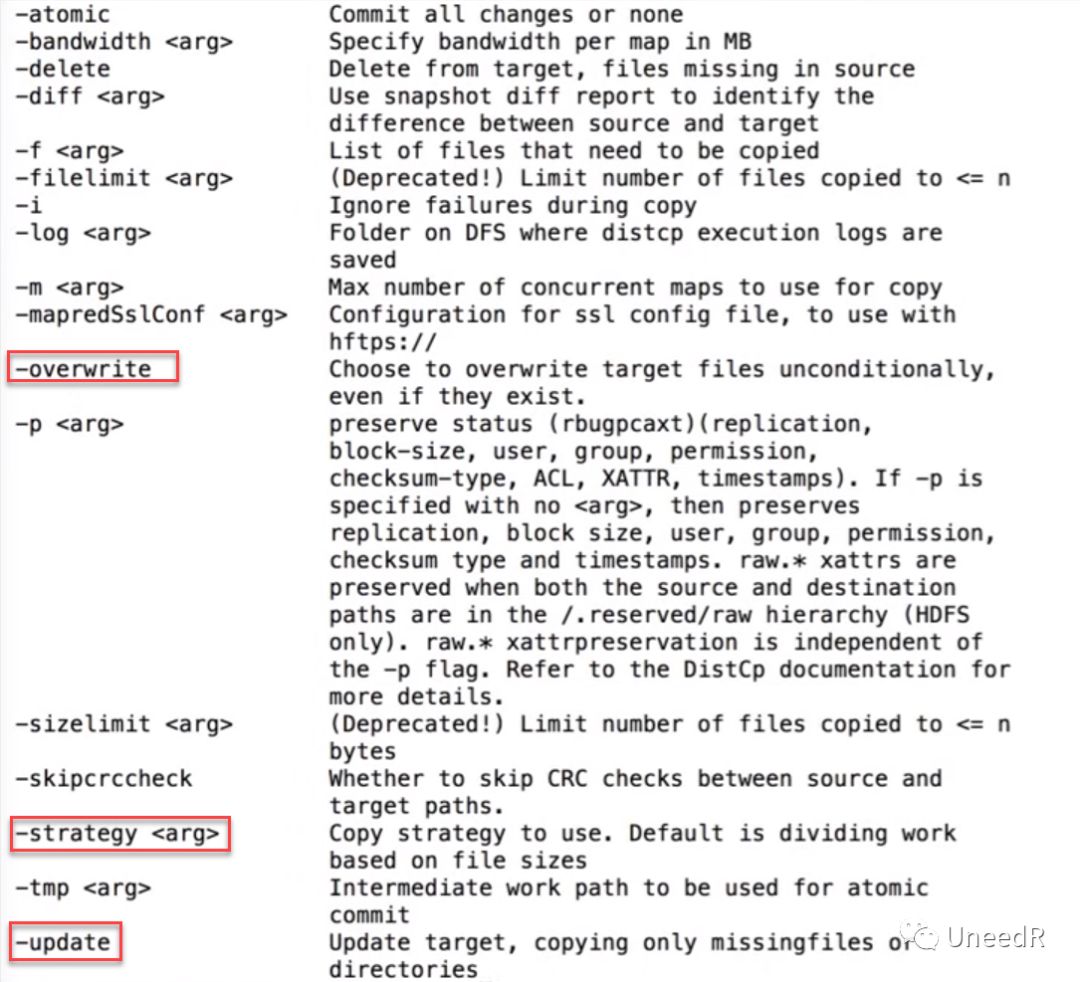
根据提示,远程拷贝的命令及参数是hadoop distcp <源路径> <目标路径>,常用的参数有:-overwrite(覆盖目标路径下的同名文件)、-strategy(拷贝策略,默认策略为“按文件大小分割工作包”)以及-update(只拷贝目标路径下缺失的文件)。我们看一下执行效果:
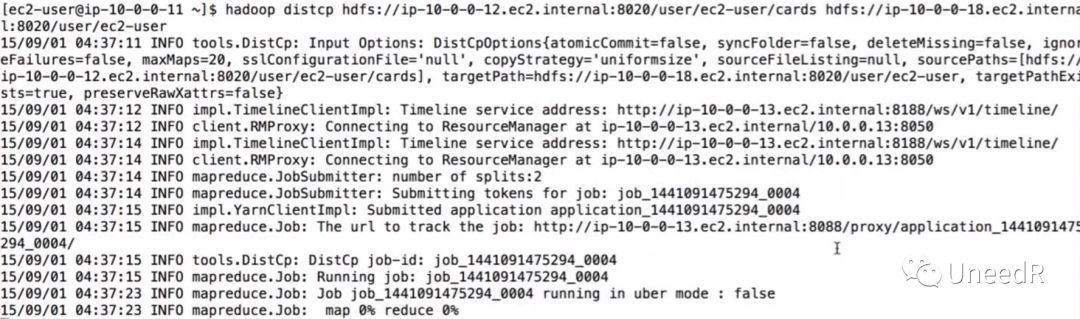
拷贝完成后,我们能看到作业的整体概述,其中包括文件总数,作业数量
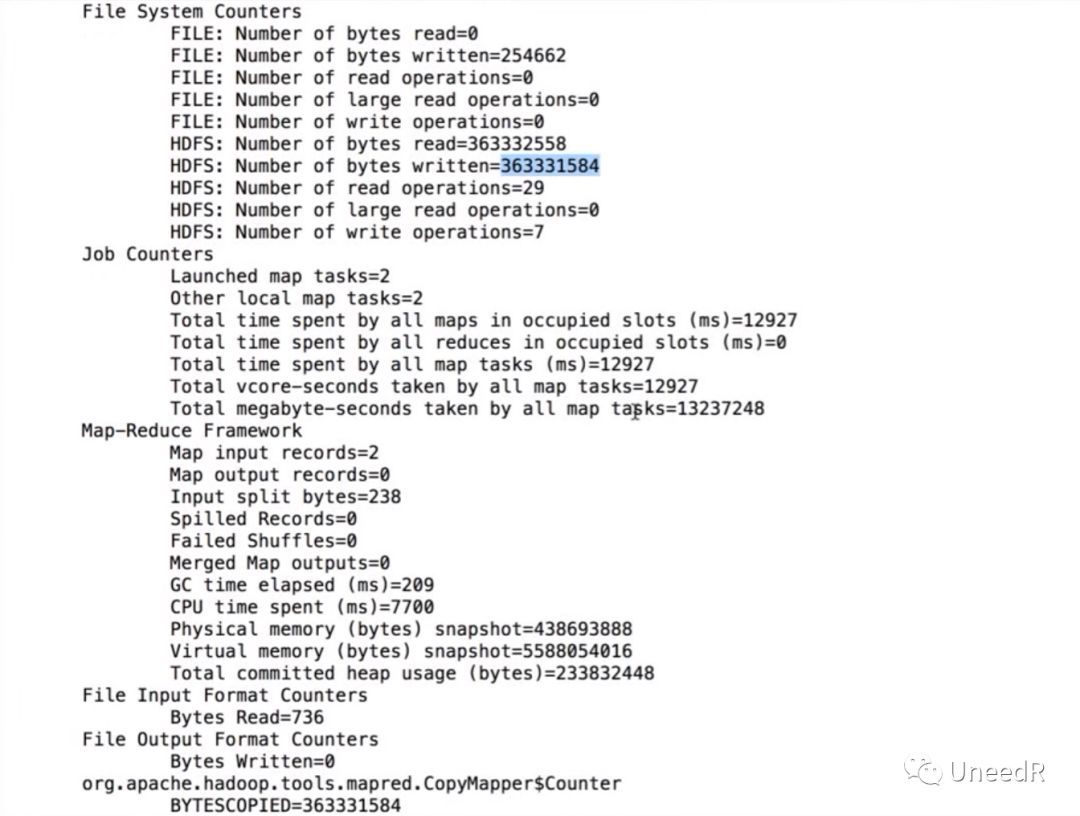
加上-delete和-update的参数清空并更新目标路径和源路径不一致的文件,但不会替换一致的文件。

小编觉得还是挺方便的,虽然图形界面下的备份可以做在线备份,并且可以定计划。
但实际上这种“准”在线的备份是通过镜像快照完成的,备份时会占用大量内存资源,很容易导致写入队列溢出,并不推荐在生产时间执行备份。
夏洛克 AIOps
Make Data Think
人工智能 | 机器学习 | IT运维
以上是关于码农心得 | 分布式文件系统的备份的主要内容,如果未能解决你的问题,请参考以下文章