从设计到实现:写入流程代码精炼 | 分布式文件系统读书笔记
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从设计到实现:写入流程代码精炼 | 分布式文件系统读书笔记相关的知识,希望对你有一定的参考价值。
在之前几篇文章中,我们通过对比HDFS和GFS复制流程在设计上的区别与特点,总结出了HDFS在实现流程上的细节。本篇将把实现流程的关键逻辑(主要是Client端代码)进一步抽离到一个独立类中,以顺序执行方式,呈现一个纯粹的写入流程,并附上关键代码的调用层级示意。
文 | 何文鑫
*注:点击图片可查看清晰大图
client创建namenode通信代理:
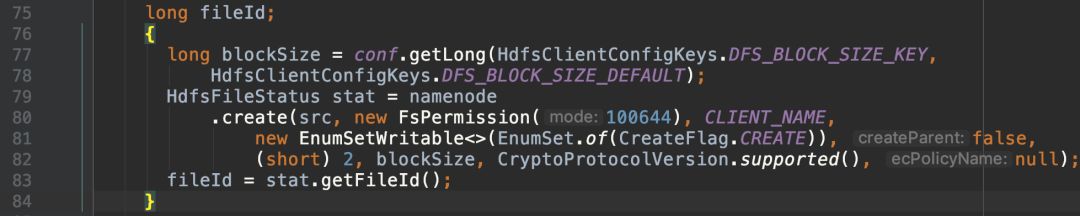
向namenode申请新建文件,副本数为2,返回fileId:
向namenode申请新建块,namenode返回LocatedBlock,内含datanode列表:

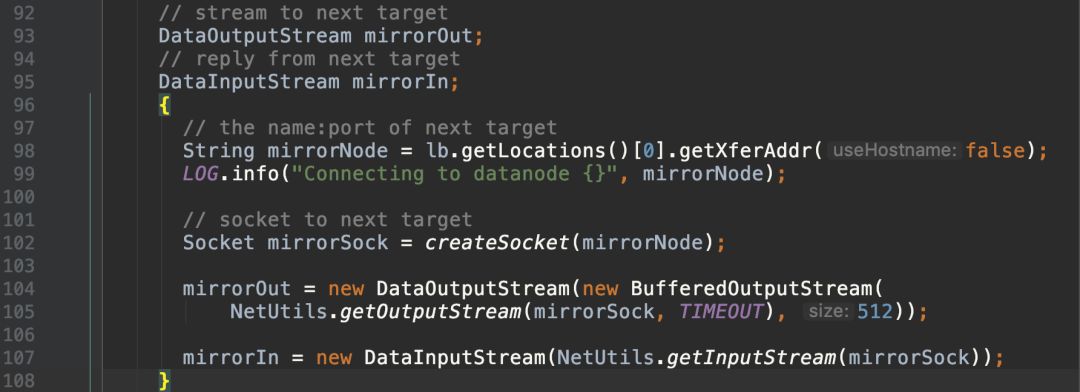
与第一个datanode建立socket通信:
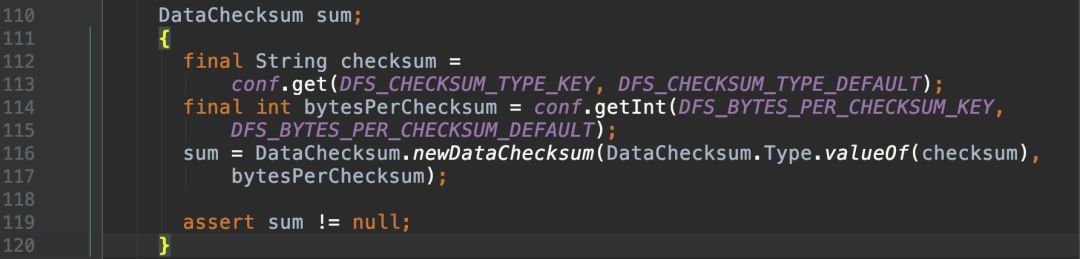
创建用于数据传输校验的DataChecksum:
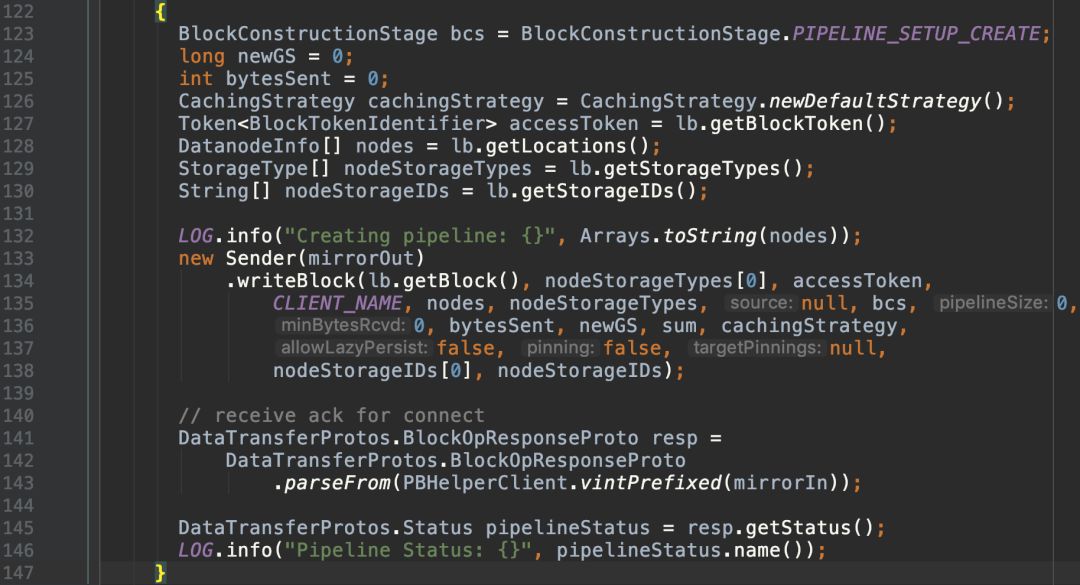
创建pipeline,读取ack:
读取本地数据:

计算本地数据校验值:
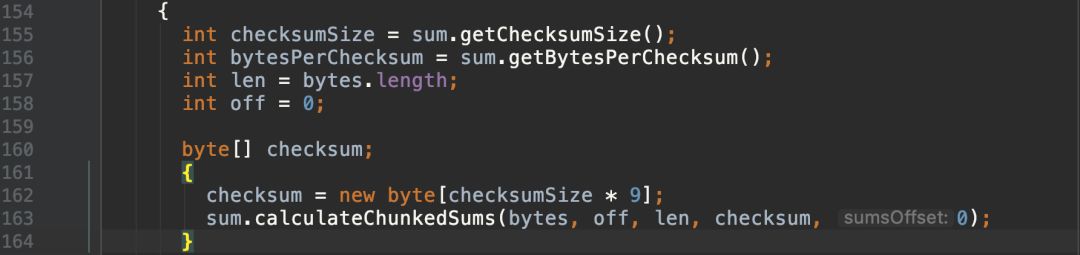
创建容纳数据的packet:
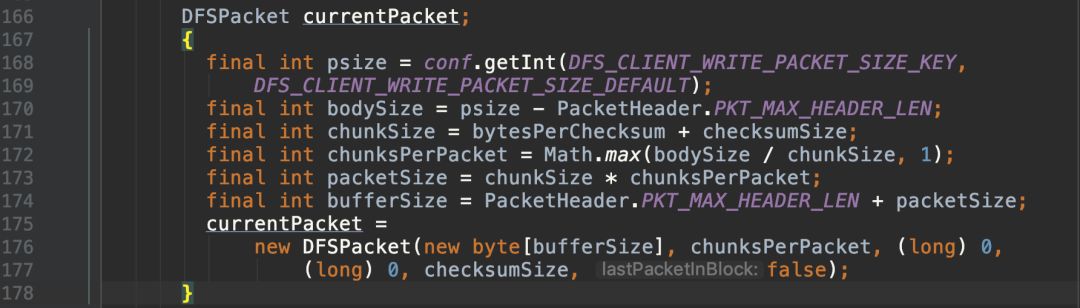
将数据拆分为多个chunk写入packet:
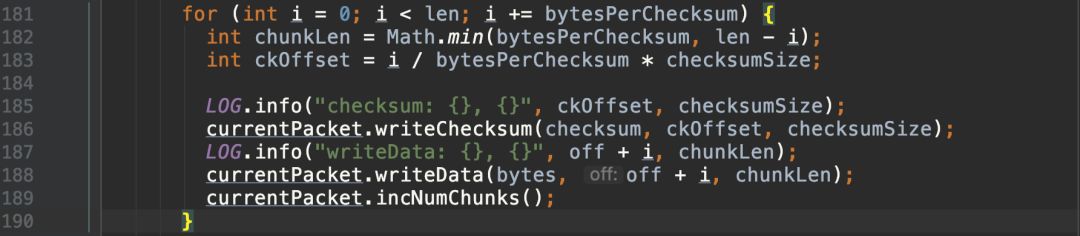
packet写入pipeline,读取ack:

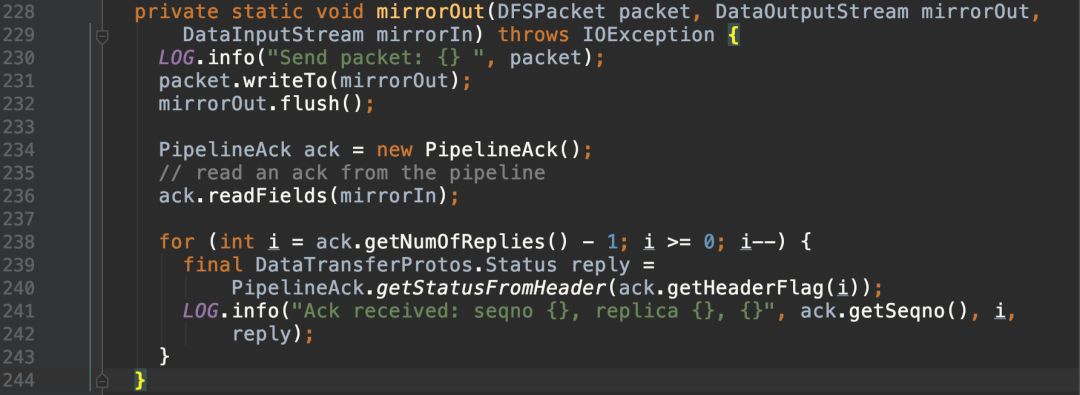
发送close消息拆掉pipeline,关闭输入输出流:
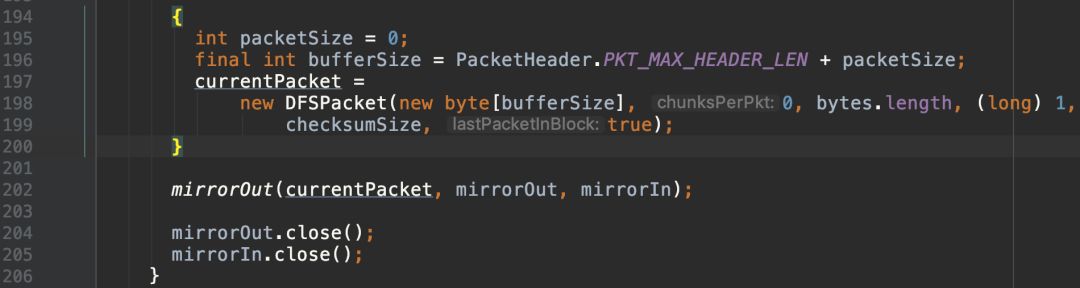
告知namenode块写入完成:

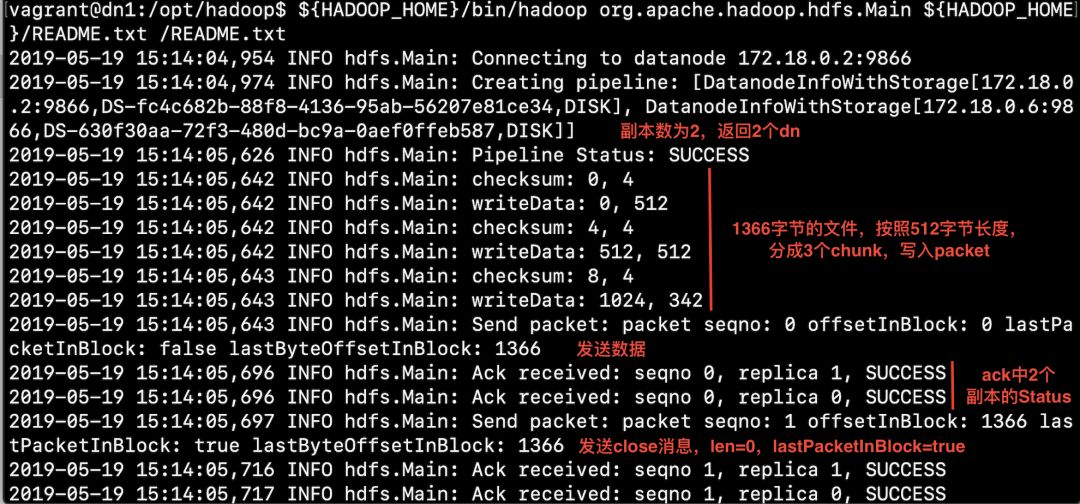
运行结果:
完整代码见github/gist:
https://gist.github.com/wenxinhe/aa37fded1978d05292c969f8d99f3d09
hdfs写入关键代码调用层级示意:
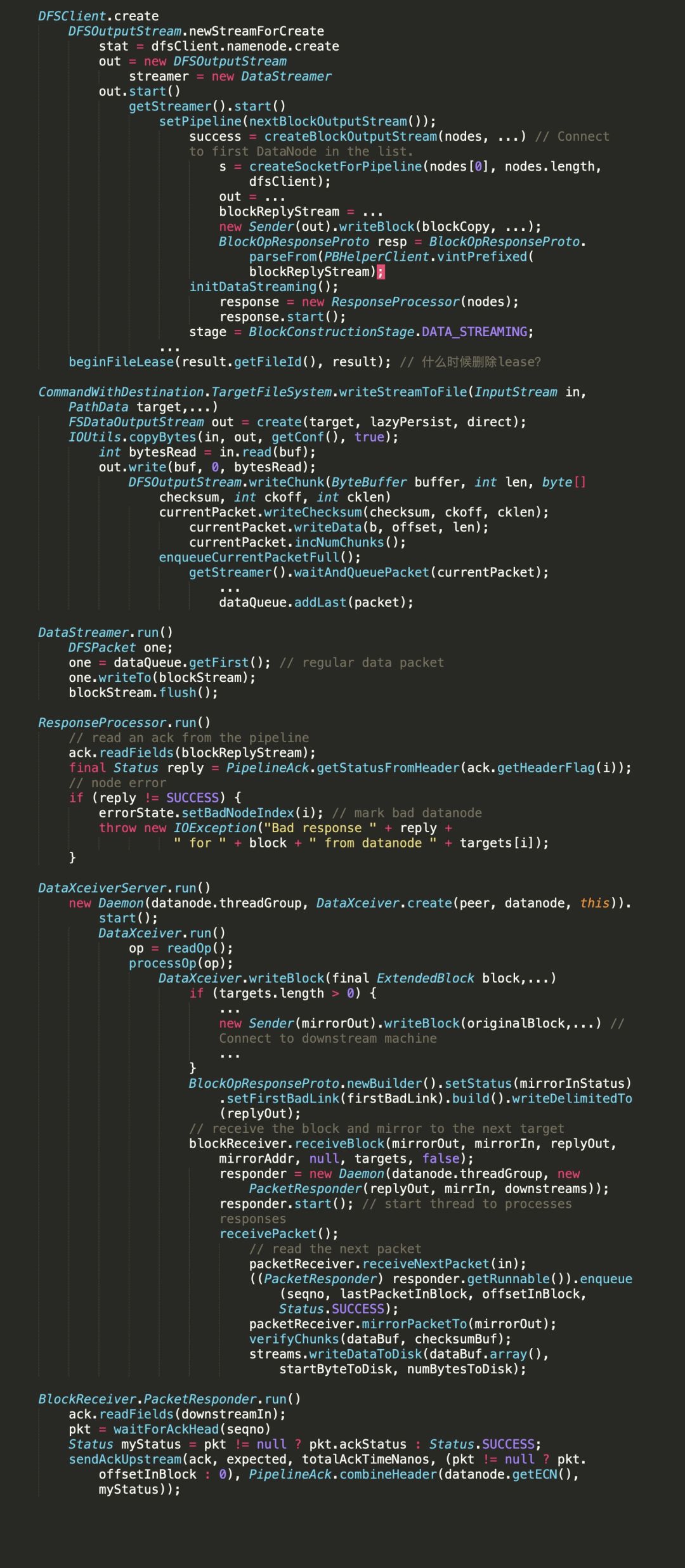
(to be continued...)
「从设计到实现」系列文章:
长按二维码关注
以上是关于从设计到实现:写入流程代码精炼 | 分布式文件系统读书笔记的主要内容,如果未能解决你的问题,请参考以下文章