水平大步提升- 理解分布式一致性与Raft算法
Posted 王牌物联
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了水平大步提升- 理解分布式一致性与Raft算法相关的知识,希望对你有一定的参考价值。
出于可用性及负载方面考虑,一个分布式系统中数据必然不会只存在于一台机器,一致性简单地说就是分布式系统中的各个部分保持数据一致
bility):
在数据同步过程中,集群是否是可用状态
分区容忍性(Partition tolerance):是否能够容忍网络分区的发生
C和A相对好理解,这里着重说一下P(Partition tolerance)分区容忍性,听着比较拗口,说实话,刚开始看到他的时候也是一脸茫然,分区?什么是分区?其实分区(Partition)简单的说就是服务器之间的网络通信断了,两边的服务器变成两个独立的集群,这就是所谓的分区,断了的原因有很多比如交换机故障,路由器故障,扫地阿姨把网线拔了等等,然后什么是容忍性(tolerance),这个就很好理解了,是不是发生分区了我的服务就不再提供服务了呢,当然不是,否则也就没有高可用一说了,那么我们能否说不做网络故障可能发生的假设呢,答案必然是不能的,首先网络延迟是必然的,网络延迟的过程中也可以将其当做发生分区,另外网络故障也可以说是必然的,详见墨菲定律(滑稽脸)
其实P也不是完全不能抛弃的,很简单,我们干掉网线,只保留一台单机数据库,就只有一个区,何来分区一说,对啊,所以说我们常见的传统单机数据库(RDBMS)就是可以满足CA的,如:mysql,Oracle等等,当然,前提是你没做主从之类的分布式方案。由此可见,在所有分布式系统中P几乎都是不可抛弃的,所以说我们的选择也就只剩两个了AP和CP。
举个简单例子,若我们集群有两台机器,而两台机器网络发生中断而导致出现分区:
如果我们在双发无法通信的情况下继续允许两边进行写入,则必然造成数据的不一致,这时我们实现了AP而抛弃了C。
但如果我们禁止其中一方进行写入,这样就可以保证系统的一致性了,但我们却因为将一中一个副本置为不可用而导致了A属性的丧失,也是说实现了CP。
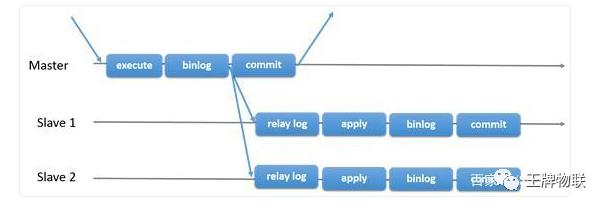
这样CAP理论是否变得好理解了一些?当然现在对于CAP理论的争议也很大,但并不是怀疑CAP定理是否能被证伪,而是说CAP理论也许并不适用于我们通常对数据库系统的描述,有时我们并不能简单的将数据库划分为AP或CP。举个栗子:chestnut:,如果我们有一个single master+multiple slaves的mysql数据库,当leader不可用时,用户则不能进行写入,也就丧失了A属性,但由于MySQL是通过binlog异步同步数据库的,用户也有可能读到的是旧数据,所以说该系统也许既不满足A也不满足C,仅仅满足了P属性。
(关于CAP的争议讨论推荐阅读:《请不要再称数据库是CP或者AP (Please stop calling databases CP or AP)》 )
基于CAP理论的AP与CP互斥的原则,针对C的取舍,我们简单划分成了3个级别来描述(特殊场景下会更多):
强一致性可以理解为当写入操作完成后,任何客户端去访问任何存储节点的值都是最新的值,将分布式的一致性过程对客户端透明,客户端操作一个强一致性的数据库时感觉自己操作的是一个单机数据库,强一致性就是CAP定理中所描述的C(Consistency),同时下面的讲解的Raft算法就是实现线性一致性的一直
弱一致性是与强一致性对立的一种一致性级别,弱一致性简单地说不去对一致性进行保证,客户端在写入成功后依旧可能会得到旧的值,这也就是舍弃C可能造成的问题,但某些系统下,对一致性的要求并不高,从而可以舍弃强一致策略可能带来的性能与可用性消耗。
最终一致性也可以理解成弱一致性的一种,使用这种一致性级别,依旧可能在写入后读到旧值,但做出的改进是要求数据在有限的时间窗口内最终达到一致的状态。也就说就算现在不一致,也早晚会达到一致,但狭义上的弱一致性并不对一致性做出任何保证,也许某些节点永远不会达到一致,其实最终一致性的核心就是保证同步的请求不会丢失,在请求到达时节点的状态变为最新状态,而不考虑请求传输时的不一致窗口,DNS就是典型的最终一致性系统。
Raft算法的论文题目是《In Search of an Understandable Consensus Algorithm (Extended Version)》(《寻找一种易于理解的一致性算法(扩展版)》),很容易理解,Raft算法的初衷就是设计一个相较于Paxos更易于理解的强一致性算法,虽说更好理解,但依旧毕竟是分布式一致性算法,其算法复杂程度及各种状态的多样性依旧需要较高的理解成本。但是花时间成本去学习Raft是值得的,理解Raft后能够很大程度加深你对分布式及线性一致性的理解,这次仅是基于个人理解的描述性介绍Raft算法,不对如选举异常或宕机等情况的处理做更多探究,如果有什么疑问欢迎进行讨论,同时感兴趣的同学也推荐阅读Raft原版论文(中文版):寻找一种易于理解的一致性算法(扩展版)
Raft算法作为单纯的一致性算法,使用场景并非仅仅在数据库,Raft算法将分布式一致性问题拆分为若干个子问题进行解决,其他的相关机制均是这三个子问题的延伸,接下面我们详细阐述一下这三个子问题。
注:下面所涉及到所有RPC的协议字段都可以在论文中找到
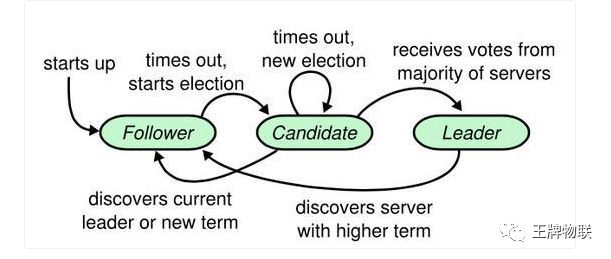
通常Raft节点拥有5个节点,将这五个节点分为三种角色Leader,Follower和Candidate,所有节点只可能是这三种角色,并且所有节点的对等的,它们都可以成为这三种角色的其中之一。
其实虽然有三种角色,但进行抽象以后可以理解为集群只有Leader与Follower两种角色,Candidate是Leader的预备役而已。
简单的讲可以将Raft系统理解为一个一主多从(single master multiple slaves)的RDBMS(MySQL等),但RDBMS通常采用的方案是Master节点用于写,而Followers用于读,但Raft不同的是不管是读和写都要经由Master节点分发给Followers节点,这样做的缺点是可能会导致Leader节点的负载会高于Followers,但这样做的好处是实现了强一致性,强一致性的部分下面会详细说明。
既然是单Leader,那么假设我们的Leader宕机了怎么办,这时候我们就可以将这个问题拆分为两个部分:

如果发现Leader节点宕机如何重新选举Leader
第一个问题在Raft中的解决方案是增加心跳(heartbeat),Leader定期向所有Followers发送心跳消息,若follower在一段时间内没有收到leader的选票(心跳超时,超时时间随机,由Follower自己控制),则认为Leader宕机,开始选举
当Follower认定Leader宕机后,他会自告奋勇的认为自己应该成为新一轮的Leader,这时他会将自己的状态转换为candidate,并向Node广播请求选票的RPC,如果超过半数的Node同意他成为新的Leader则代表他应得了这次选举,他就会变成新的Leader。
虽然心跳超时随机的策略大幅度减少了两个Followers同时超时的情况,但依旧不能保证不会出现两个candidates同时超时的情况,假如说出现两个candidate同时超时的情况就有可能接连发生两个candidates同事发起选举投票,两个candidates将选票瓜分,最终没有人能够获得超过半数的选票,这个异常机制的保障措施是candidates当角色发生转换后candidates会重置超时时间,如若一段时间内没有新的Leader产生,则重新发起新一轮的选举,因为所有超时时间均是随机的,所以第二次发生瓜分选票的可能性已经变得微乎其微。
在论文中也验证了小幅度的随机既可以让选票瓜分的情况大大减小:
只需要在选举超时时间上使用很少的随机化就可以大大避免选票被瓜分的情况。在没有随机化的情况下,在我们的测试里,选举过程往往都需要花费超过 10 秒钟由于太多的选票瓜分的情况。仅仅增加 5 毫秒的随机化时间,就大大的改善了选举过程,现在平均的宕机时间只有 287 毫秒。增加更多的随机化时间可以大大改善最坏情况:通过增加 50 毫秒的随机化时间,最坏的完成情况(1000 次尝试)只要 513 毫秒。
如果Candidate如果接收到其他Candidate的的选举请求的话,如何认定究竟是继续收集选票还是投票给其他candidate?如果大家一直互相谦让或者一直互相竞争,岂不是最终谁也不能够成为Leader了吗?,
针对这个该问题,在请求选举的RPC中Raft增加了
任期号(term)
的概念,在raft系统初始化时,所有node的term均为0,当某一个节点成为candidate时,该节点就会将term+1并发起选举,follower仅会投票给RPC中的term大于等于自己的currenttTerm的RPC投票,这样就避免了无限对等投票的可能性。Raft协议引入了任期号(term)的概念,任期号很简单,所有node节点在初始化的时候,选票号都为1,当任何follower当选candidate的时候都会将选票号置加1,并附带至发起选举的RPC中,如若其他节点收到了选举投票RPC,他会比对自身的选举号是否比RPC中的选举号小,如果小于RPC中的选举号,则他会承认对方的权威
只有leader节点可以和客户端通信,同时将log复制至所有follower,强制folloer与leader的log保持一致。
所谓日志,其实就可以理解为增删改查(CRUD)的命令(但其实raft并不关心这个日志是做什么的),这个命令在这里称为log,raft将log序列化,log依次复制并执行到每一个node,就能实现节点的强一致性,raft中解释是 “如果有任何的服务器节点已经应用了一个确定的日志条目到它的状态机中,那么其他服务器节点不能在同一个日志索引位置应用一个不同的指令” ,也可以理解为raft日志复制的安全性保证是确保所有序列按顺序append,不能越过某一个log,这样就保证了假如查询发生在修改之后(但可能有不同的实现方式),那最终不论访问的是哪一个节点,查询必然发生在修改之后,这样就可以确保拿到的数据是最新的了。

leader将当前的index+1,赋给该log,并append到自己的Logs中
leader广播(RPC)该log给所有follower
当超过半数的follower回应接收成功时,leader就将该log commit,并通知所有follower commit
上面提到了Raft算法是如何进行leader选举和如何进行日志复制的,至此其实已经可以实现分布式一致性了,但是如果想保证日志提交精准无误则需要更多地安全性保障措施
假如某个candidate在选举成为leader时没有包含所有的已提交日志,这时就会出现日志顺序不一致的情况,在其他一致性算法中会在选举完成后进行补漏,但这大大增加了复杂性。而Raft则采用了一种简单的方式避免了这种情况的发生
Raft在RequestVote RPC(候选人请求成为Leader的RPC请求) 中增加了自己的日志信息
当followers收到RPC请求时则会把candidate的日志信息与自己的日志信息进行比较
假如follower的日志信息相较于candidate要更新,则拒绝这个选票,反之则同意该candidate成为leader
经过这一系列的步骤,则保证了 仅允许包含了所有已提交日志的candidate赢得选举成为候选人,从而也就避免了leader缺少已提交日志的情况了
leader将log复制到大多数followers
follower将日志复制,并告诉leader自己已经复制成功
leader收到了大多数followers的复制成功响应,并提交日志
但是这里有一个问题,假如leader已经将日志复制到了大多数followers,但却在提交之前崩溃了,虽然raft算法中规定后续的leader应该继续完成之前的复制任务,但在下图的情况下依旧会出现已经复制到大多数节点的log依旧被覆盖掉了。
在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。
在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。
然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。
如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志
Raft为了避免这种情况发生,而规定了一个原则, Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目 ,也就是说假如这个log的任期已经过了,就算是已经复制到了大多数节点,Raft也不会去提交它,那么在这种情况下如何对之前任期的log进行提交呢,这时引入了Raft的
,该原则的描述是“如果两个日志在相同的索引位置上的日志条目的任期号相同, 那么我们就认为日志从头到这个索引位置之间的条目完全相同”,这个机制的原理是leader在进行日志复制时会检查上一条日志是否一致,如果不一致则会将上一条复制给follower,在复制上一条的过程中依旧会进行检查,这样一个递归的过程保证了Raft的Log Matching原则。
|
|
大客户销售:王先生 |
15562436876 |
销售部总监:杨女士 |
15634143134 |
青岛办事处:王先生 |
15562436876 |
|
鲁中地区(威海、烟台、淄博、潍坊、日照) |
负责人: 杨经理 |
15634143134 |
|
鲁西北区域(东营、滨州、德州、聊城) |
负责人: 种经理 |
13153111543 |
|
鲁西南区域(泰安、济宁、菏泽、临沂、枣庄) |
负责人: 王经理 |
18615643935 |
|
招聘职位:销售代表
工作职责
1、要求20----33岁,大专以上学历;
2、勇于挑战高薪,热爱销售工作,有销售工作经验者优先考虑。
3、熟悉使用办公软件,熟练利用销售技巧销售公司产品。
4、性格积极主动,有责任心。
5、有团队协作精神,有耐力善于挑战。
薪资待遇
1、有竞争力的薪资,年薪在10万以上。
2、八小时工作制,其余时间自己安排。
3、每周休息一天半,给你充分的休息时间。
招聘职位:销售主管
工作职责
1、负责产品推广和销售;
2、根据计划完成销售指标
3、开发新市场,增加新客户范围
4、负责区域内销售活动策划、执行
5、维护客户关系达成长期战略计划
薪资待遇
1、有竞争力的薪资,年薪14万以上。
————————王牌国际期待您的加入,共创辉煌————————
以上是关于水平大步提升- 理解分布式一致性与Raft算法的主要内容,如果未能解决你的问题,请参考以下文章