双十一:系统稳定性保障核武器——全链路压测
Posted 编程技术圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双十一:系统稳定性保障核武器——全链路压测相关的知识,希望对你有一定的参考价值。
每天凌晨00点00分, 第一时间与你相约
每日英文
Life is too short to spend time regretting. If it's not the end, smile and keep on going.
生命太短,没时间留给遗憾。若不是终点,请微笑一直向前。
每日掏心话
机遇总是有的,如果把握不住,不要怨天忧人,只因自己不够优秀;不要把时间当垃圾处理,唯有珍惜光阴,才能提升生命的质量。
来自:阿里云云栖社区 | 责编:乐乐
链接:zhuanlan.zhihu.com/p/28458624
程序员小乐(ID:study_tech)第 684 次推文 图片来自网络
往日回顾:
正文
摘要: 阿里巴巴双11备战期间,保障系统稳定性最大的难题在于容量规划,而容量规划最大的难题在于准确评估从用户登录到完成购买的整个链条中,核心页面和交易支付的实际承载能力。在首届阿里巴巴中间件技术峰会,阿里巴巴中间件高级技术专家张军为听众详细讲解了系统稳定性保障的核武器——全链路压测。
为什么要做全链路压测?
对阿里巴巴而言,每年最重要的一天莫过于双11。这是因为在双11的零点,系统会遭遇史无前例的巨大洪峰流量冲击,保证双11当天系统的稳定性对高可用团队来说是巨大的挑战。在这个挑战中会有很多不确定因素,大致分为两方面:
技术架构带来的不确定性,阿里在08年开始对系统进行拆分,由原有的单一系统拆分成了分布式架构,包括CDN、网关、负载均衡、分布式页面系统等,整体的技术生态十分丰富。分布式环境任意环节出了问题都可能会对系统造成影响;
业务发展带来的不确定性,系统的可用性随着业务增长,面临更严峻的挑战和不确定性。
不确定性带来的系统可用性问题

这些不确定性背后的因素多种多样,既涉及系统容量、业务性能,又涉及基础设施瓶颈、中间件瓶颈和系统之间的依赖影响,并且众多因素缺乏有效的验证手段。事实上,阿里从10年开始就在尝试去解决双11零点的稳定性问题。
线上单机与单系统压测
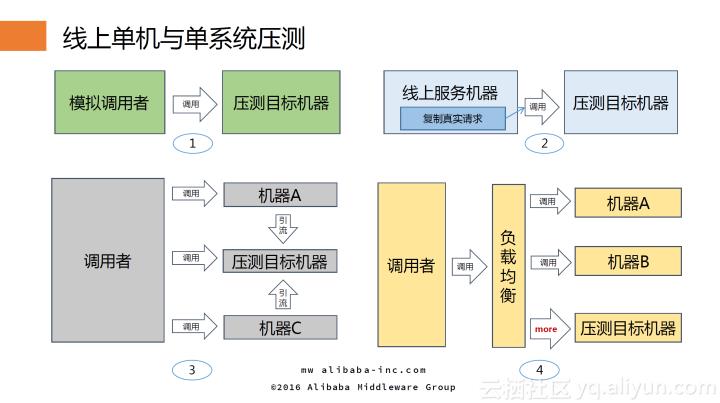
最初采用的方式是在线上单机的生产环境的压力测试和容量规划,主要采用了四种方式:第一在开始阶段模拟调用者,其中在生产环境中只能模拟只读请求,对写请求需要特定的处理;第二种方式是采用流量录制和回放的方式做压力测试,通过将录制的流量快速率回放对单台机器进行压测,获取单台机器的服务能力;后两种是从流量分配的角度出发,分别是请求流量转发和改变负载均衡的权重,两者核心思想都是将流量集中到某台机器上。通过上述机制和手段,能够准确探测到单台机器的服务能力。基于单台服务能力和预估即将到来的业务流量进行容量规划,确定所需服务器的数目,这种做法伴随着阿里度过了10、11、12三年的双11零点稳定性的考验。
单系统压测的问题
但10和11年双11零点由于流量过大暴露了不少问题,让我们意识到单个系统ready不代表全局ready,究其根本原因在于系统之间相互关联和依赖调用之间相互影响。在做单个系统的容量规划时,所有的依赖环节能力是无限的,进而使得我们获取的单机能力值是偏乐观的;同时,采用单系统规划时,无法保证所有系统均一步到位,大多数精力都集中核心少数核心系统;此外,部门问题只有在真正大流量下才会暴露,比如网络带宽等等。
全链路压测-站点稳定性保障最有效的解决方案
随着业务的快速增长和系统稳定性弊端的暴露。阿里从13年双11起就着手进行全链路压测。

全链路压测的本质是让双11零点这一刻提前在系统预演(用户无感知),模拟“双11”同样的线上环境、用户规模、业务场景、业务量级,之后再针对性地进行系统调优,是站点的一次高仿真模拟考试。

全链路压测核心要素主要包括四点:
压测环境,它是指具备数据与流量隔离能力的生产环境,不能影响到原有的用户体验和用户流程、BI报表以及推荐算法等;
压测基础数据,它主要包括压测用户、店铺、商品等基础数据;
压测场景模型,它主要是指压测哪些业务场景,每个场景下压测多大量等;
压测流量,它主要由压测请求的协议来决定压测流量的输出;
下面来一一详细介绍这四大核心要素:
压测环境
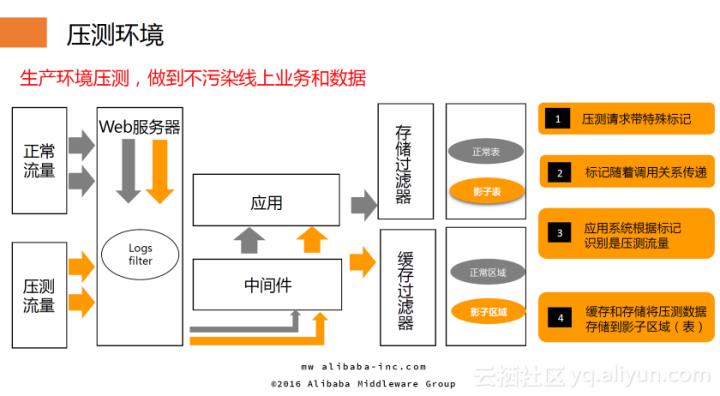
由于是在生产环境做双11的全链路压测模拟,因此防止压测数据和流量污染和干扰生产环境是及其重要的。要实现这一目标,首先要求压测流量能被识别,采用的做法是所有的压测流量都带有特殊的标记,并且这些标记能够随中间件协议的调用关系进行传递;此后,应用系统根据标记识别压测流量;在缓存和存储时,通过存储和缓存过滤器将压测数据存储到影子区域(表)而不是覆盖原有数据。上述所有操作都遵循一个原则:能够用中间件解决的问题,绝不对业务系统进行改造,系统所需做的是升级中间件,这一原则极大提高了工作效率。
压测基础数据&压测场景模型
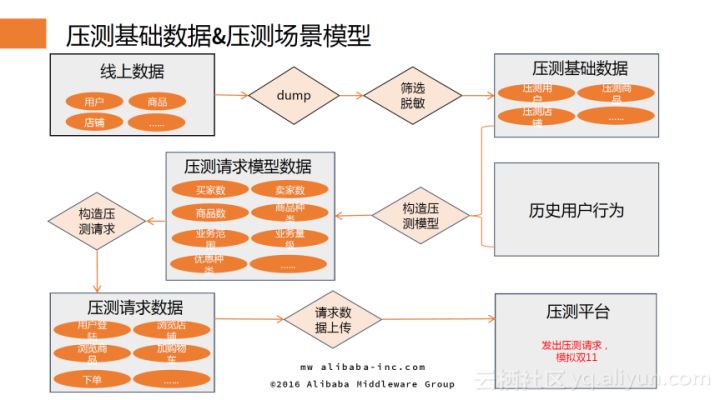
在压测基础数据方面,为了保证真实性,实现与真实双11零点的数据匹配,我们直接从线上用户的数据(剔除敏感信息)进行筛选,同时确保用户规模与双11零点的真实用户数量一致。
基于用户数据构建压测模型是全链路压测中较为复杂的一步,它要求压测模型贴近双11零点的用户模型。我们根据前几年的历史数据和行为,结合预测算法进行模型的预估;最后生成业务场景模型;这些模型再和各个业务系统的负责人研讨,进行微调。根据最后确定的压测业务模型构造压测请求数据,最后将请求数据上传到压测平台,发出压测请求,模拟双11。
压测流量平台整体结构
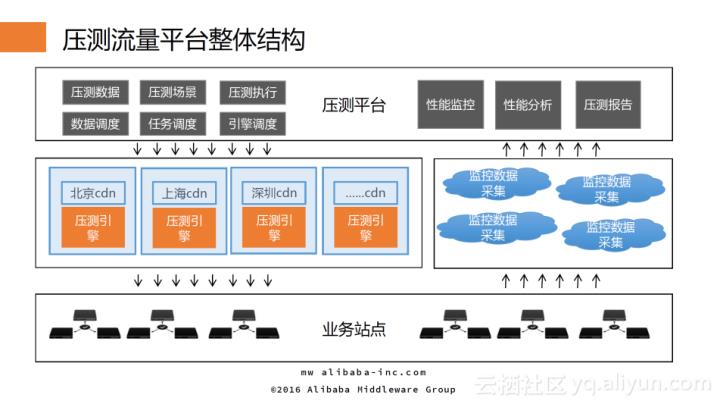
上图是压测流量平台的整体结构,主要分为三个部分:最上层是Master端,主要用于压测数据、压测场景和压测执行的配置和控制,并且其还负责压测引擎的任务分配和调度,以及一些容灾策略,最后Master端还需要对压测性能监控、分析,最后生成压测报告。中间部分是压测引擎,目前采用的是阿里自主研发的压测引擎,部署于全球各地的CDN节点上(出于用户场景的真实性)。最下层是性能探测与监控集群,在压测过程中需要实时探测各个业务系统的运行状态以决定压测是否继续进行。
压测流量平台挑战
在实际进行全链路压测时,压测流量平台面临了一系列的挑战:首先需要面对T级别的压测请求数据;其次要满足每秒1000W+次请求压测能力;此外,需要能够维持1亿+的无线长连接和登陆用户;并且压测流量平台应该能够灵活操作,体系联动;在扩展性方面,需要支持自定义协议和流程;最后,平台应该做到秒级的智能数据调度和引擎调度能力。
压测流量平台技术选型

最初做全链路压测时,尝试采用浏览器引擎去做,但由于Rhino引擎不兼容主流浏览器;后来换成了Selenium+ChostDriver+PhantpmJS,这种方式能够真实模拟用户的环境,但性能上不去,要完成压测成本太高;再后来,我们尝试了一些第三方的压测工具如Jmeter、Grinder、Tsung、Gatling等,但由于性能和扩展性方面的原因,被迫放弃;最终,我们采用了自实现引擎和操控中心来进行搭建压测流量平台,实现性能、兼容性、扩展性全方位Cover。
压测流量平台——压测引擎

如上图所示,压测引擎自下而上分为协议支持、请求发送、集群协作三层:
协议支持,主要支持的PC端协议包括Http、Https、websocket,无线端协议是Spdy、http2、accs、acds、mqtt。由于真正在双11时,用户使用的浏览器各异,进而导致与服务端协商的加密算法不一致,为了尽量模拟准确性,需要支持SSL 2.0\3.0、TLS1.0\1.1\1.2不同算法套件灵活配比,贴近用户端行为。
请求发送,由于全链路压测是利用现有的CDN集群,为了不影响现有CDN业务的正常运转,需要做Cgroup资源隔离(主要包括CPU和网络),为了实现性能最优,通常采用异步Reactor模型发送请求,链路间线程池隔离。
集群协作,控制中心Master充当大脑来发送指令,所有节点根据收到的指令执行下一步操作,并且所有slave压测节点会实时将自身状态同步到Master,以便于其做决策,如果slave节点状态不好,master则将其剔除。如果压测引擎与控制中心失联,则压测引擎会自杀,避免流量浪费。
压测引擎从上往下的优化历程包括:系统层的TCP参数调优;在JVM层,优化SSL库;在网络响应时,边读边丢,减少损耗;数据结构上尽量采用无锁的数据结构,即便是有锁,也要避免在锁里进行比较耗时的操作;在处理流程上,尽量采用异步化,缓冲队列衔接,避免异步饥饿;上层调度时,引擎之间根据负载动态调度,提高整体吞吐量。
全链路压测在阿里巴巴
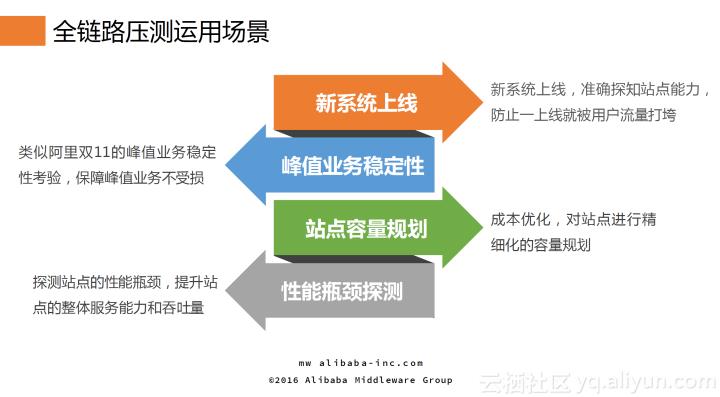
目前,在阿里内部,全链路压测主要用于以下四种场景:
新系统上线:全链路压测用于新系统上线,准确地探知站点能力,防止一上线就被用户流量打垮;
峰值业务稳定性:通过全链路压测对类似于阿里双11的峰值业务稳定性进行考验,保障峰值业务不受损;
站点容量规划:通过全链路压测技术对成本进行优化,对站点进行精细化的容量规划;
性能瓶颈探测:全链路压测还可以用于探测站点的性能瓶颈,提升站点的整体服务能力和吞吐量。
在阿里内部,单链路(业务线)压测每年有10000+次;全链路压测每年在10次左右,包括38大促、618大促、双11、双12大促等,其作为大促稳定性最重要的“核武器”,通过对网络、应用、中间件、DB、基础服务、硬件设施、预案等全方位大促演练验证,覆盖阿里集团各Bu业务线,确保大促活动的高稳定性;此外,阿里还将这种全链路压测复制到优酷土豆、高德、友盟+等收购公司中。
双11全链路压测现场

上图是双11全链路压测的现场照片,双11全链路压测阶段除了对系统稳定性进行检测之外,还对团队的人员组织、协作进行了演练、检验,确保双11零点到来时,万事俱备。
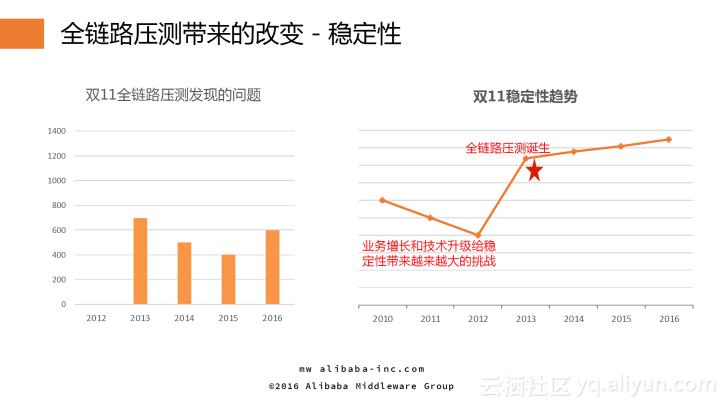
全链路压测给双11带来的最大的改变是稳定性,从13年起,双11零点的稳定性较11、12年得到了大幅提升,这是因为在全链路压测过程中,每年都能发现几百个问题并提前解决,极大地提高了零点的稳定性。
全链路压测带来的另一大改变就是成本:
机器成本,全链路压测拉平了系统间的水位,同样数量的机器提供了更大业务吞吐量,通过探测系统瓶颈点,进行针对性优化,补齐了“木桶”的短板,从未提升站点性能。
人力成本,在进行全链路压测之前,几百个系统的容量规划工作需要几十人耗时3个月;在全链路压测之后,通过压测动态调整资源,既省时省力,又更加精准,人力成本大幅衰减。
全链路压测平台
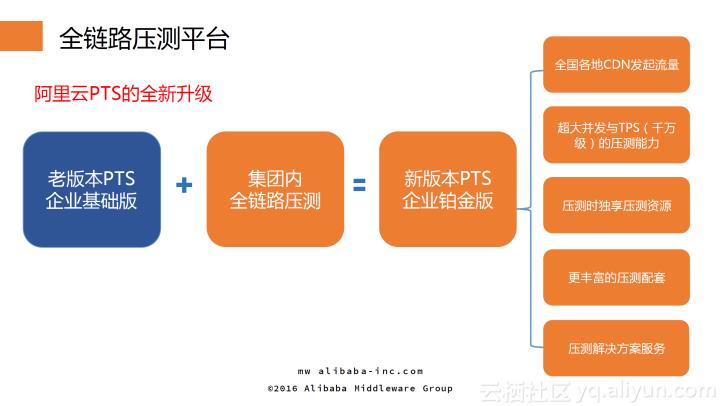
目前,全链路压测与阿里云PTS产品进行了融合,生成新版本PTS(企业铂金版)。该版本包含全链路压测的流量功能,从全国各地CDN发起流量;且具有超大并发与TPS(千万级)的压测能力;在压测时独享压测资源以及更丰富的压测配套;此外,新版本PTS还对外提供压测解决方案服务,满足客户同阿里一样的全链路压测需求。
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,学习能力的提升上有新的认识,欢迎转发分享给更多人。
猜你还想看
关注微信公众号「程序员小乐」,收看更多精彩内容
以上是关于双十一:系统稳定性保障核武器——全链路压测的主要内容,如果未能解决你的问题,请参考以下文章