百万长连接之全链路压测性能分析
Posted 搬运工来架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百万长连接之全链路压测性能分析相关的知识,希望对你有一定的参考价值。
一、背景:
基于WebSocket长连接的消息服务进行全链路压测,目标是实现最少100W长连接下压测服务的各个接口TPS,QPS及其稳定性和资源消耗情况。
二、全链路架构图:
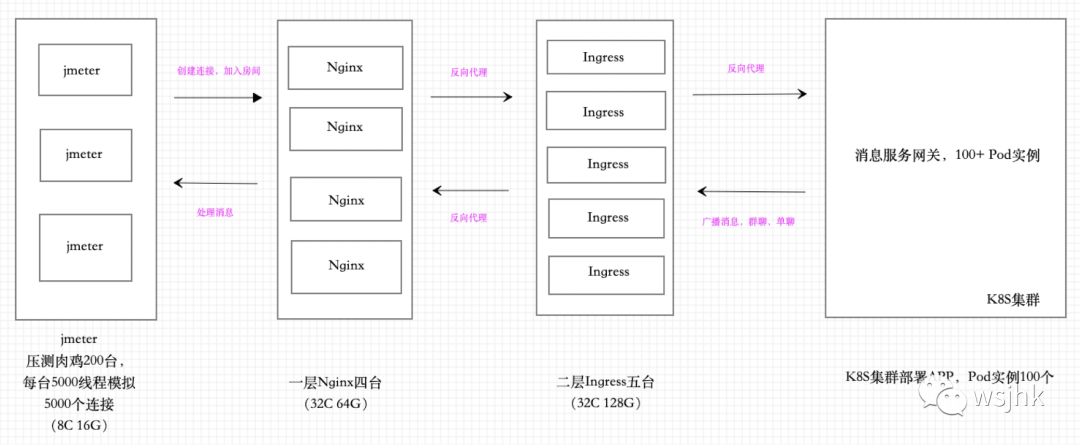
三、遇到的问题总结:
问题一:Jmeter客户端连接达到1w左右时,出现OOM。
问题二:心跳超时导致连接断开。
问题三:达到50w并发时,出现连接大批量掉线问题。
问题四:达到72w并发时,出现连接数上不去的问题。
问题五:达到100w并发稳定建立并保持时,出现发送数据掉线问题,此时nginx OOM。
# cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_max_tw_buckets = 200000
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.ip_local_port_range = 11000 61000
fs.file-max = 1000000
net.ipv4.ip_conntrack_max = 2000000
net.ipv4.netfilter.ip_conntrack_max = 2000000
net.nf_conntrack_max = 2000000
net.netfilter.nf_conntrack_max = 2000000
net.ipv4.tcp_max_orphans = 500000
net.ipv4.tcp_mem = 786432 2097152 3145728
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
EOF
# sysctl -p
//设置文件句柄数,其实不需要设置100w这么大,根据肉鸡的连接数设置合理即可
# sed -i s/65535/1000000/g /etc/security/limits.conf四、压测过程问题排查分析:
在搭建,调试好全链路压测环境后启动一台Jmeter肉鸡进行测试,发现当肉鸡连接数达到1w时出现OOM。报错如下:

此时的jmeter启动参数如下:
# cd /root/apache-jmeter-5.1.1/bin/ && HEAP="-Xms15g -Xmx15g" ./jmeter-server -Djava.rmi.server.hostname=xxx.xxx.xxx.xxx -Jserver.rmi.ssl.disable=true &> /tmp/jmeter.log &
发现jvm设置的内存很大,有15g,百度谷歌一番,得知:

于是,将jmeter的jvm设置成4g,如下:
# cd /root/apache-jmeter-5.1.1/bin/ && HEAP="-Xms4g -Xmx4g" ./jmeter-server -Djava.rmi.server.hostname=xxx.xxx.xxx.xxx -Jserver.rmi.ssl.disable=true &> /tmp/jmeter.log &
调整之后单台jmeter客户端连接数能达到2w并且内存还很充足。后续所有肉鸡都用此参数启动进程。到此,开始进行压测。
开始压测50w的并发建连,建立连接后3分钟左右出现断线,进行分析是因为在没有数据发送的情况下,Nginx配置了180s的超时时间。超过180s后主动断掉连接。通过和开发沟通,将proxy_connect_timeout,proxy_send_timeout和proxy_read_timeout都设置为900s。如下:
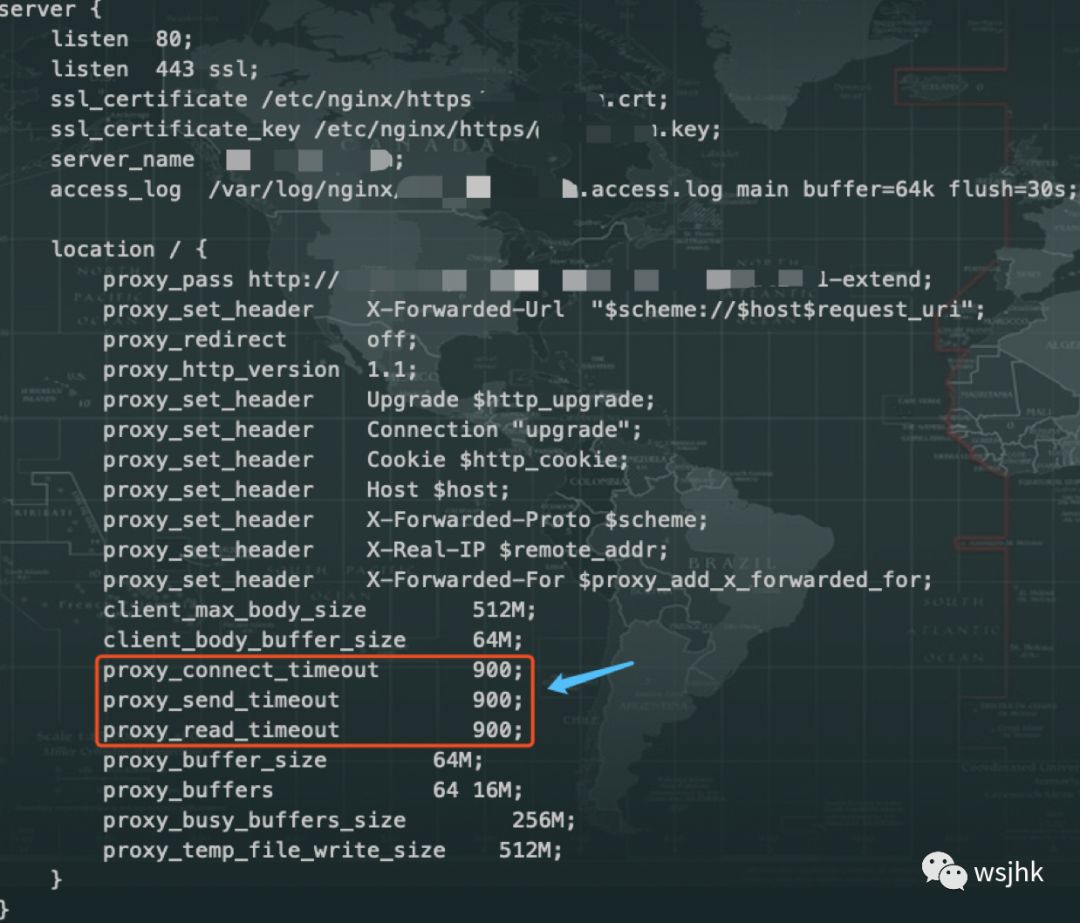
reload nginx生效后问题解决。
继续压测,使用50台肉鸡,每台启动1w线程建立连接。在连接数达到50w保持心跳连接时,开始发送数据出现大批量掉线(发送的数据会造成使得在同一房间的连接都会收到消息,即:广播)。
首先,使用以下命令查看一层Nginx和Ingres的连接状况:
# netstat -n | awk /^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}
发现Nginx和Ingress都出现了大量TIME_WAIT,说明连接是代理层主动断开的(主动断开连接的一方会进入TIME_WAIT状态),此时查看Nginx和Ingress日志并没有发现任何的报错。询问消费服务网关开发同学是否有报错日志,开发同学反馈是客户端主动断开了连接,但是没有更加具体的报错。查看肉鸡Jmeter的日志,有如下报错:

这是jmeter的第三方websocket的jar报出来的错,也是显示连接不可用。日志都没有具体的问题,那么到底是什么原因导致连接被断掉呢?开始在整条链路上抓包分析,每一个节点都抓取上下游的包,抓包命令如下:
# tcpdump -i any host xxx.xxx.xxx.xxx -v -w client.pcap
//tcpdump抓取的报文通常会很大,可以使用wireshark自动的editcap和mergecap工具根据时间来分隔和合并报文
分析报文,发现肉鸡发送大量的窗口满的报文,由Nginx和Ingress代理到后端服务网关。如下是Ingress到服务网关的报文:
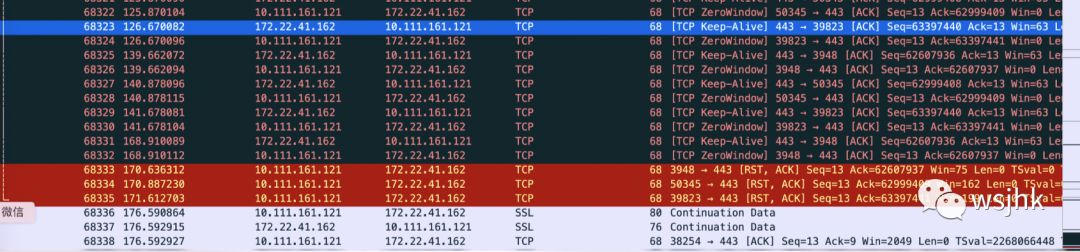
Ingress发送TCP ZeroWindow的报文,最后会RST连接。那么肉鸡为什么会发送窗口满的报文呢?查看全链路的带宽情况:
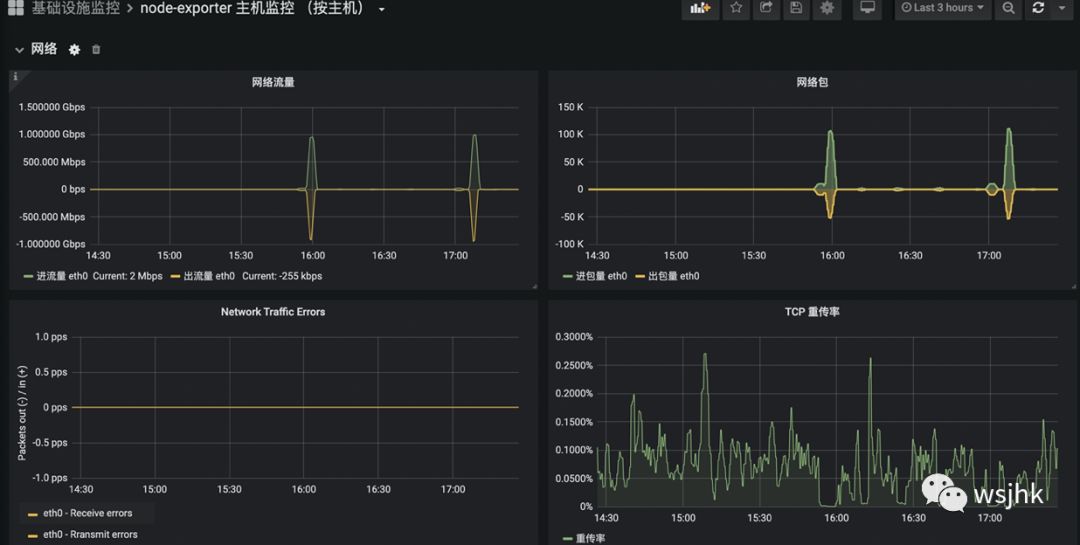
查看监控发现网络和带宽都是没有问题的。于是将重点指向肉鸡,初步怀疑是肉鸡的websocket jar包在处理网络数据的机制上有问题。经过一番搜索,发现如下:

在jmeter-websocket-samplers-1.2.2.jar的官网搜索到作者的最新版本说解决了该问题,于是替换jmeter-websocket-samplers-1.2.2.jar包为最新的JMeterWebSocketSamplers-1.2.6.jar版本。实测无效,问题依旧。再次重点分析肉鸡,查看监控,发现肉鸡在出现掉线的时候负载很高,load average高达200+。判断是肉鸡负载过高,处理不过来导致tcp滑动窗口满,最终断开连接的问题。
于是,增加肉鸡到100台,每台肉鸡还是开启1w线程,看只建立100w连接不发送数据的情况下是否稳定。发现在连接数达到72w左右时连接数上不去了。于是,分析全链路能支持的并发数。要计算全链路支持的并发数需要了解以下知识点:
TCP连接知识点:
1.一个TCP连接的套接字对(socket pari)是一个定义该连接的两个端点的四元组,识一个网络上的每个TCP连接。
2.linux socket使用16bit无符号整型表示端口号,最大到65535。也就是说一台客户端的机器上的一个IP对应有65535个端口号可以用于对服务端建立TCP连接,
而服务器的服务端口号一般是启用端口复用的,
也就是一个服务端口可以支持多个TCP连接,epoll模式理论上支持的连接数没有上限。
3.使用nginx作为反向代理时,nginx即是服务端,又是客户端。作为服务端,服务的端口号对客户端是复用的,然后作为客户端使用本机的其他1024~65535
端口号和后端的服务器建立连接实现代理。
这样,一个TCP连接在反向代理的nginx机器上表现为有两个TCP连接,即占用两个socket文件句柄数。
4.计算nginx或者ingress支持的TCP连接数计算方法,以nginx为例,根据tcp连接四元组可知:Nginx的IP数 * Nginx开启的随机端口数 * Ingress
的IP数 * Ingress服务端口数 = 1 * 65535 * 1 * 1 = 65535 正常情况
下理论上是支持65535个TCP连接的,
但是随机端口数0~1024一般作为服务端口被占用,所以需要去除掉一些常用的端口,并预留一部分端口。所以开启10240~65000大概5.5w个端口数。
5.在充分利用机器资源的情况下,支持50w+的TCP连接数的瓶颈:
第一,压测到Nginx服务端,瓶颈在于增加压测机的数量;
第二,Nginx到Ingress,增加Ingress服务端口数,开启多个服务加到Nginx的upstream中来扩充四元组中的Ingress服务端口数;
第三,Ingress到服务端,增加服务端的pod数加到Ingress的upstream来扩充四元组的服务端端口数。所以需要关注这三个点的TCP连接数的支持情况。
所以解决nginx端口耗尽的问题可以在nginx上增加upstream数量,upstream可以是不同的ip+port,也可以是同一个ip下的不同port,还有就是可以在nginx主机
于是查看一层Nginx的/proc/sys/net/ipv4/ip_local_port_range的值,设置为21000-61000,端口数为4w,后端后5个Ingress,也就是每个Nginx能支持20w的连接,一共4个Nginx,也就是:4*20w=80w。排除其他和压测无关的连接后,和72w相差不大,于是调整改参数为:1024-65530,理论上估算能支持:4*5*6w=120w并发连接。但是,Nginx的连接数还取决于worker_rlimit_nofile和worker_connections两个参数,如下: 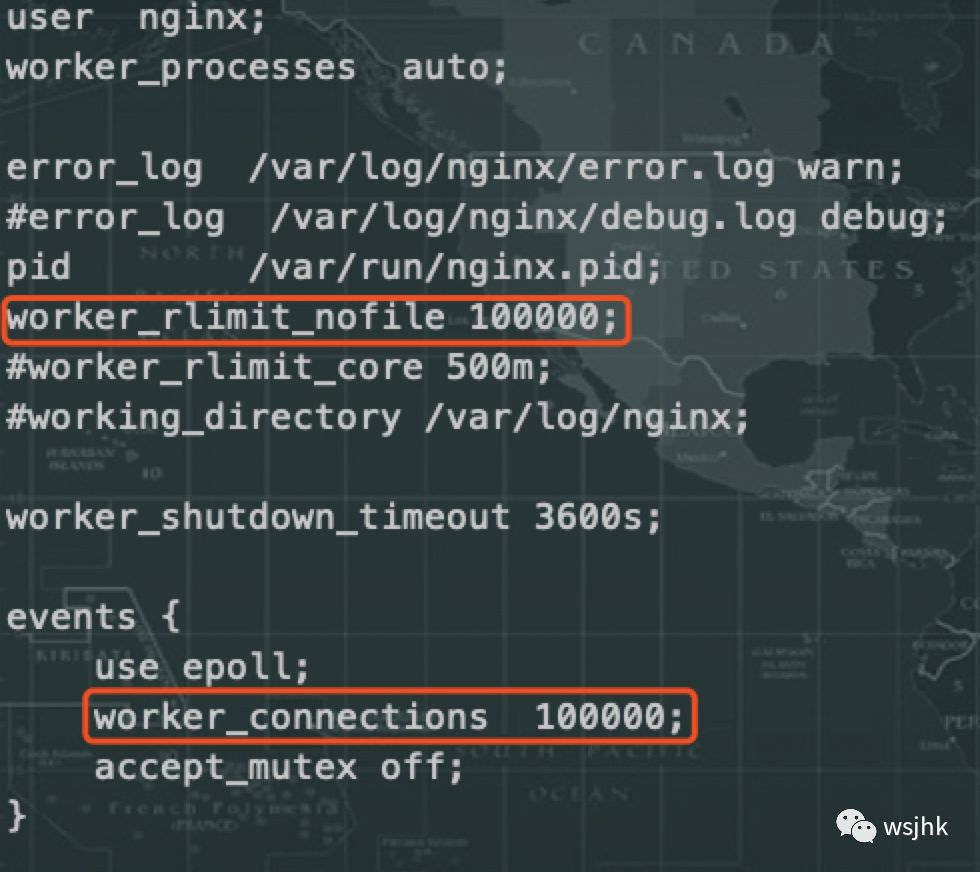

并且由于worker_connections这个参数会在Nginx启动时预先分配内存,所以这个值并不是设置的越大越好,应该根据实际场景来设置大小。可以通过调整改值后重启Nginx时通过# free -m 查看nginx的初始占用内存大小来验证。在32个woker下,改值设置10w时,初始化内存大概为3G;设置100w时,初始化内存大概14G。
继续压测,当连接稳定在100w时开始发送数据,出现Nginx内存飙升,最后频繁OOM,伴随着TCP重传率高达40%-50%。报错和监控如下(原本Nginx是64G内存,后因为该问题升级到128G内存后问题依旧):
[Fri Mar 13 18:46:44 2020] Out of memory: Kill process 28258 (nginx) score 30 or sacrifice child
[Fri Mar 13 18:46:44 2020] Killed process 28258 (nginx) total-vm:1092198764kB, anon-rss:3943668kB, file-rss:736kB, shmem-rss:4kB 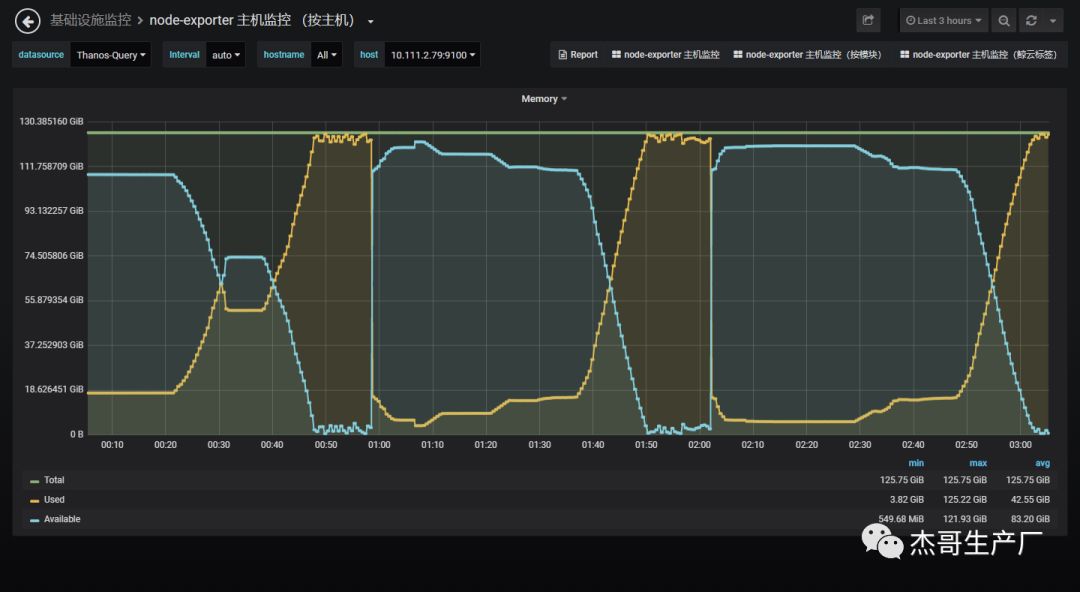
此时,再次全链路抓包,查看服务器负载和带宽情况(说明系统监控的重要性,我们使用的是Grafana+Prometheus+Alertmanager+node_exporter监控栈)。

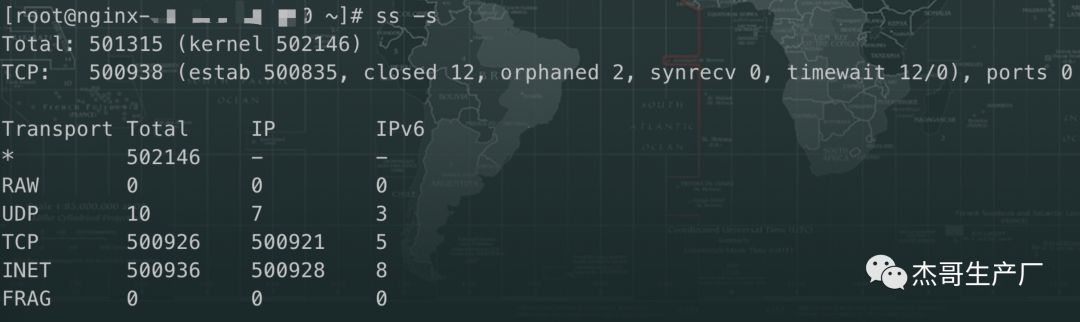
此时查看Nginx和肉鸡两端的网络连接状态,使用 # ss -tn 命令可以看到大量 ESTABLISHED 状态连接的 Send-Q 堆积很大,客户端的 Recv-Q 堆积很大。Nginx 端的 ss 部分输出如下所示:

并使用# dstat 命令查看系统性能状态:

可以看到,最后两列中系统CPU中断和上下文切换开销都很大。系统负载高。
此时,定位到是jmeter肉鸡处理能力有限,有较多的消息堆积在中转的Nginx中,导致Nginx内存不断飙升直到OOM。于是,增加肉鸡到200台,每台肉鸡线程数从1w降到5000。此时发现,压测能正常进行,但是Nginx内存仍然在上升,只是对比之前上升的稍微缓慢一些。再次抓包分析,肉鸡还是偶尔出现零窗口。于是想到,Nginx是否可以不缓存消息?通过分析Nginx的配置参数,发现proxy_buffers这个值设置很大,如下:
查看官网相关配置项,关闭proxy_buffering,调小proxy_buffer_size 和 proxy_buffers,注释proxy_busy_buffers_size。如下:
proxy_buffering off;
proxy_buffer_size 4k;
proxy_buffers 4 8k;
#proxy_busy_buffers_size 256M;
经过实测,在压测环境修改了这个值以后,以及调小了 proxy_buffer_size 的值以后,内存稳定在了 20G 左右。
来源:
1、
2、
3、
4、
5、
6、
7、
8、
9、
10、
-关注搬运工来架构,与优秀的你一同进步-
如果喜欢这篇文章可以点在看哦
以上是关于百万长连接之全链路压测性能分析的主要内容,如果未能解决你的问题,请参考以下文章