CODING DevOps 高可用实践,保障服务稳定的“定海神针”
Posted 腾云 CODING
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CODING DevOps 高可用实践,保障服务稳定的“定海神针”相关的知识,希望对你有一定的参考价值。
对于软件研发团队而言,服务的稳定性是非常重要,它与生产经营、用户留存都密切相关。而 CODING 作为面向软件研发团队的研发协作管理平台,与客户的业务生产更是密不可分。如何为客户提供高可用、不间断的服务体验,如何多层面、多渠道来保障 CODING 本身的服务稳定性,成为了 CODING 发展道路上不懈的追求。
背靠腾讯云,充分利用云上能力
CODING 作为一站式云端开发平台,从诞生之初就生长在云端,充分利用腾讯云的能力为客户提供弹性可靠的服务。比如,CODING 持续集成的编译池基于 CVM 进行架构,保障用户极速构建无需等待;制品库充分利用对象存储 COS 及 CDN 极速能力,为广大客户提供了全球一致的拉取及响应。CODING 通过对云能力的充分利用,保障客户软件开发过程的可靠。
严谨的发布流程,践行最佳实践
CODING 团队平均每周进行上百次更新发布,以快速响应客户需求。在频繁变更的场景下,为了避免变更引起的业务故障,CODING 团队从变更流程上进行了诸多保障措施。
CODING 提供 Testing 和 Staging 两个测试环境,Testing 环境由开发团队自行维护,Staging 环境由公司统一维护,与线上环境最为接近。开发完成本地测试后,会进行 Testing 和 Staging 两轮验证,充分利用 CODING 持续集成提供的自动化测试能力,确保变更不会影响线上 P0 及 P1 级别的功能及流程。
验收通过后,该变更将灰度发布到生产环境,在灰度企业进行测试验收,验收通过后才会发布到线上环境。除生产环境之外,CODING 还进行了备用环境的部署,如果发生发布事故,可迅速切换至备用环境,保障服务可用,在生产环境变更验收通过后,才会更新备用环境。
持续性架构升级,关键服务保障
除了通过云的能力和流程规范确保 CODING 整体的可靠性之外,根据不同产品线的不同场景,也在架构设计上进行了高可用保障。
代码仓库
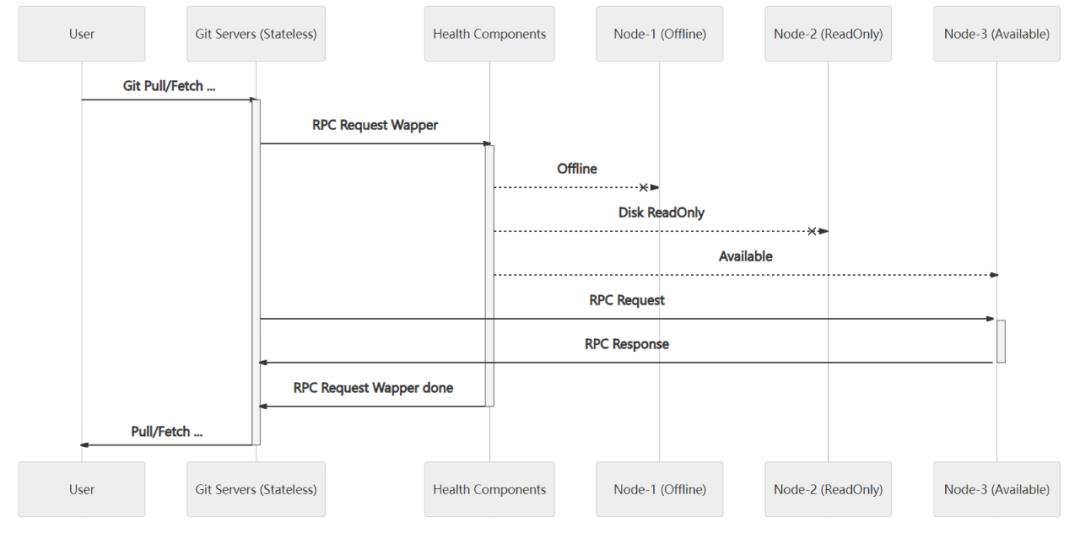
代码是软件研发企业的核心资产,客户的代码存储安全是 CODING 工作的重点。CODING 代码仓库通过在存储机器上为储存库创建多个副本,实现了存储冗余。同时在存储库副本之间建立了实时高效的同步机制,保证了存储库副本之间的一致性。在存储库感知机制上,CODING 代码仓库构建了一套存储库故障感知机制,一旦故障发生,则能够迅速进行故障转移从而能继续为存储库提供服务。
持续集成
稳定的构建环境是保障用户持续集成可靠的重要一环。而实现稳定高效构建,不仅需要考虑构建资源的有效利用和状态管理,还要保障其它依赖服务的稳定性。比如 CVM 在某个地域无法创建构建机器时,会导致使用该地资源节点的用户无法顺利构建,为了防范这个问题, CODING 持续集成采用灵活的容灾策略,对构建节点池进行地域切换,对故障进行转移,确保构建的稳定性,实现服务的高可用。
持续部署
相较于传统的内网场景,SaaS 场景对持续部署提出了更高的要求。比如 SaaS 场景下,对大量集群资源进行动态更新,在集群资源数据庞大的基础上确保服务性能。
面对这样的挑战, 在服务的交互上,CODING 持续部署重点保障发布服务的稳定性、可靠性,采用断路器,请求重试算法,服务优雅关闭等技术,确保在高并发场景中服务更新用户无感知,提高服务的容错能力。在服务的扩展上,CODING 持续部署支持 HA 高可用拆分,同一服务可根据业务需求以及访问量,按功能拆分部署提供服务。另外,CODING 持续部署编排引擎支持分布式任务调度处理,解决了 SaaS 场景下高并发发布部署的性能瓶颈,为客户提供了快速安全可靠的部署方式。
监控预警完备,先一步发现问题
有防就有治,在运维上,CODING 建立了一套完善的故障预警与治理机制。为及时应对故障,CODING 基于 Prometheus 构建了服务监控预警系统,用户可依据不同的业务场景,通过运维方自定义监控数据的可视化和报警规则。一旦发现服务异常产生告警,告警信息可根据报警规则,第一时间通过企业微信精确地推送至相关的组或个人,及时发现生产问题。
为提升整体系统稳定性以及各类异常故障的容错能力,CODING 还制定了故障演习标准定期演习,对于影响全站访问的核心业务须保证每月进行至少一次故障演习,其它业务最长演习间隔不得超过两个月,出现演习结果不符合预期时,应尽快输出改进计划并进行改进,随后进行新的演习以确认改进措施落地情况。在容错机制上 CODING 也进行了明确要求,如系统内部单点故障,下游故障系统都需具备自动发现和屏蔽错误的能力;不能存在超时或者无限重试导致系统雪崩的情况;在服务异常时,业务需要有自动降级的方案。
点击阅读原文
开启高效云上研发工作流
以上是关于CODING DevOps 高可用实践,保障服务稳定的“定海神针”的主要内容,如果未能解决你的问题,请参考以下文章