iPhoneX 到底值不值得买,数据分析告诉你
Posted 大数据分析和人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iPhoneX 到底值不值得买,数据分析告诉你相关的知识,希望对你有一定的参考价值。
我是一个文科生,之前没学过什么编程,所以不会讲什么太偏网页基础知识的.
主要分享在R爬虫时httr包和jsonlite包的运用。
如写的有什么瑕疵地方请多多指教,希望在这里也能找到我们用R做爬虫的小伙伴。
目的
在手机品牌里面,苹果一直深受广大消费者的喜爱,最新款iphoneX发布到现在已经历时4个多月了。本次想通过R语言的爬虫以及词频分析技术,获取iphoneX在天猫销售的评论,研究客户们眼里的这次iPhoneX究竟是好还是坏。
产品
北京时间2017年9月13日凌晨1点,苹果2017秋季新品发布会在Apple Park举行,会上苹果官方正式发布了全新的iPhone产品-iPhone X(英语读音为iPhone ten)。iPhone X也作为苹果十周年的特别的版本出现。之所以命名为“X”是因为2017年恰逢苹果十周年,“X”在罗马数字中就代表了数字10。
齐刘海作为本次的特殊的一个外观特征改变,性能配置上面也是全面屏,前后玻璃,并加上无线技术等黑科技。
方法
步骤一、爬虫获取所需评论资料
本次运用的是以下四个包:
library(httr)
library(dplyr)
library(jsonlite)
library(stringr)
首先打开一个天猫商品的页面,这次我选择的是Iphone X。
(由于这家店销量并不算高,后来选取了苏宁店铺下的iphoneX,从原来的的1,600评论瞬间涨到20,000+)
然后往下翻看到累计评论:
F12进入开发者工具
(PS:先点击累计评价再F12,然后F5刷新)
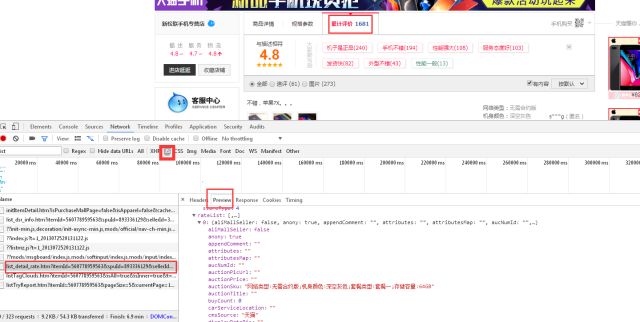
首先我们查看一下XHR,发现里面什么都没有,然后是JS(最粗的红框框)。左下角一个个点击,然后从Preview观测是否是我们需要的信息。
其次我们看一下HEADER这里的信息,request和下面params参数是我们等会运用到的
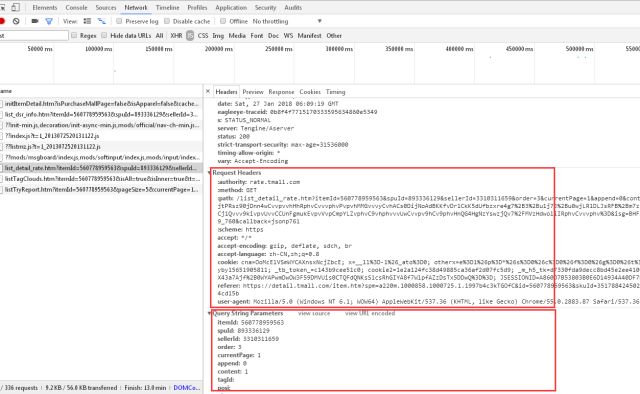

以上就是我们要用到的url"https://rate.tmall.com/list_detail_rate.htm"以及请求方式——GET(详见代码运用)
设置商品信息:
<blockquote>"itemId" = "560597539512"
(可以左右滑动)
我们首先可以观察一下web %>% content(as = "text", encoding = "GBK")得出的结果
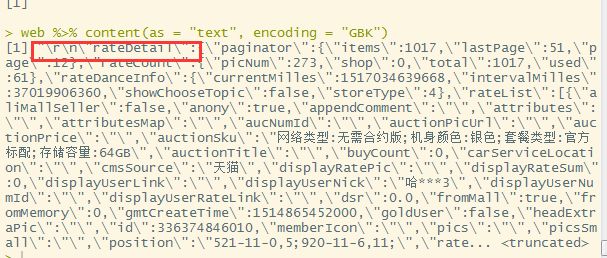
他并不是一个完美的json格式:JSON格式是这样的

从上面我们发现rateDetail\":',并不属于我们要的JSON格式,使用repalace我们替换为空白值,使其成为一个完整的JSON格式
List <- web %>% content(as = "text", encoding = "GBK") %>%
str_replace('"rateDetail":','') %>% fromJSON()
# 获取评论页数
List$paginator
# 获取内容
details <- List$rateList
result <- data.frame(
"客户" <- details$displayUserNick,
"规格" <- details$auctionSku,
"评论" <- details$rateContent,
"日期" <- details$rateDate
)
# 合并为数据框
info <- rbind(info, result)
# 这里我设置的休息时长
Sys.sleep(runif(1, 0, 1.5))
print(sprintf("正在抓取第[%s]页数数据", i))
}
print("1000页数数据全部抓取完毕!!!")
return(info)
}
# 评论汇总
comment <- download_comment(<b><font color="#ff0000">itemId = "560597539512",
spuId = "893336129",
sellerId = "2616970884"</font></b>)
(可以左右滑动)
这样我们以后只要知道以上3个红色商品、店铺参数就能随心所欲探索一些其他的产品。
setwd("D://")
# 最后别忘了把结果数据为文件
write.csv(comment, file = "iphonex.csv")
(可以左右滑动)
步骤二、词频分析
# 词云分析
library(NLP)
library(tm)
library(tmcn)
library(rJava)
library(Rwordseg)
# 建立一个文件夹ihpone,把刚才评论的文件留下评论那一列保存为新文件放入该文件夹
#1.生成语料库
TEXT <- Corpus(DirSource ("D://iphone"),
readerControl = list(language = "UTF-8"))
# 2.分词处理
# 去空格
TEXT_deal <- tm_map(TEXT, stripWhitespace)
# returnType 返回值类型,默认是数据,可以选择为 tm 包语料库类型
TEXT_deal <- tm_map(TEXT_deal, content_transformer(segmentCN),
returnType = "tm")
# 去除停用词
TEXT_deal <- tm_map(TEXT_deal, removeWords, stopwordsCN())
TEXT_deal <- tm_map(TEXT_deal, content_transformer( function(x){
iconv(x, from = "UTF8", to ="GB2312", sub ="byte")}))
# 3.词频统计
control = list(wordLengths = c(2,6), stopwords = stopwordsCN())
# 转成向量矩阵
mt <- TermDocumentMatrix(TEXT_deal, control = control)
mt$dimnames
dmt <- as.matrix(mt)
#fix(dmt)
#4.绘制词云
#安装并调用包
#install.packages("yaml")
#install.packages("wordcloud2")
library("wordcloud")
library("yaml")
library("wordcloud2")
word <- sort(rowSums(dmt), decreasing = TRUE)
word_data <- data.frame(word = names(word), freq = word)#筛选词频大于 10 的
word_data1 5,]
# 以下含默认的参数
wordcloud2(word_data1, size = 1, minSize = 0, gridSize = 0,
fontFamily = 'Segoe UI', fontWeight = 'bold',
color = 'random-dark', backgroundColor = "white",
minRotation = -pi/4, maxRotation = pi/4, shuffle = TRUE,
rotateRatio = 0.4, shape = 'sloggi', ellipticity = 0.65,
widgetsize = NULL, figPath = NULL, hoverFunction = NULL)
(可以左右滑动)
Ps:我们可以设置图片,展示为我们需要的样式。是通过设置figPath参数。
letterCloud(word_data1, word = "iphone", wordSize = 2,color = 'random-dark',backgroundColor = "snow")结论
如上面所观测到的回复多的一些字比如,正品,快,速度,好,不错,我们可以猜测到客户可能大多数觉得是正品,物流非常快速,或者手机性能很快,通过评论来看总体都是觉得该店铺的iphone X比较好。
待改进
技术方面
本次爬虫速度上面是可以提高的,毕竟1000页,还设置了休眠时间,具体时间没看过是边打游戏边跑程序,粗略算一下1页一秒左右共计耗时15-18分钟吧。也有参考过一些案例,在爬虫方方面好像有向量化数据,多进程技术可以提高速度,下次待改进。
结论方面
词频统计方面只是研究关键词,忽略了具体语境下该词的意思,并且可以通过消极和积极词词频累计来探索消费者对于iphone的评价。
选择平台
除了选取天猫店铺还可以增加一个京东苹果自营店抓取分析
作者简介
杨冰羽
电子商务数据专员,R语言爱好者
欢迎加入数据君亲自打造有情怀、高效学习数据分析的
点击了解→_→:
以上是关于iPhoneX 到底值不值得买,数据分析告诉你的主要内容,如果未能解决你的问题,请参考以下文章