AI 有嘻哈 大结局 | 使用 PyTorch 搭建一个会说唱的深度学习模型
Posted 集智学园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI 有嘻哈 大结局 | 使用 PyTorch 搭建一个会说唱的深度学习模型相关的知识,希望对你有一定的参考价值。
我们在中说到要用循环神经网络(RNN)生成嘻哈说唱词,它能生成的说唱词是这个样子的:
我的世界
能够有
看透
我的兄弟在我身边
每个人
或许他们是我的眼
原理:
简单来说,中文句子中的每个字在统计上是相关的。比如对于“多想你陪我透透气”这句话,如果我们知道第一个字“多”,那下一字有可能是“想”;如果知道前两个字“多想”,那么第三个字是“你”的可能性就大些,以此类推,如果知道“多想你陪我透透”,那么最后一个字很有可能就是“气”字。
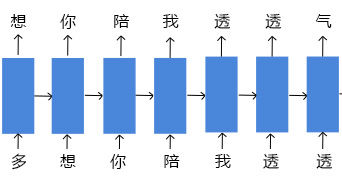
换句话说,对于“多想你陪我透透气”这句话,在训练循环神经网络(RNN)时,输入数据是“多”,那目标数据就是“想”;输入数据是“想”,那目标数据就是“你”,以此类推。
所以这次循环神经网络(RNN)的任务就是要在训练的过程中学习到“嘻哈说唱词中字与字之间的规律”。
然后我们给训练好的模型一个开头,比如“我们”,模型就能按照学习到的规律,一字字地继续预测生成“我们”之后的嘻哈说唱词。
前情回顾:
我们在上回已经把训练数据处理到了可用的程度,比如我们去除了原始数据中像“作者名、编曲名”这样与嘻哈说唱词不相干的信息,同时去除了说唱词中的英文以降低循环神经网络模型学习起来的难度。
我们处理前的原始数据是这样的:
lrc_lines = open('../data/rapper.txt').readlines()
print(lrc_lines[:20])
['\n', ' 作曲 : Mixtape\n', ' 作词 : 啊之\n', '\n', '录音 MISO MUSIC\n', '混缩 MAI\n', 'MIX BY MAI\n', "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", "hey baby Don't worry\n", '抱歉我依旧不稳定 DAMN\n', '鱼龙混杂的街头不只靠努力 REAL 别烦恼\n', '多想你陪我透透气 发发牢骚\n', '倾诉着最近不如意 let me let me\n', '这就是生活里 的问题 不必不报忧\n', '做真实的自己 不用比 早晚都能够\n', '我始终担心你 出问题 人心难看透\n', '我怎么都可以 唯有你 所以 所以\n', '我早已日夜颠倒 烟酒成瘾 制作巧克力\n']
处理之后的数据是这样的:
print(final_lrc[:10])
['抱歉我依旧不稳定\n', '鱼龙混杂的街头不只靠努力\n', '别烦恼\n', '多想你陪我透透气\n', '发发牢骚\n', '倾诉着最近不如意\n', '这就是生活里\n', '的问题\n', '不必不报忧\n', '做真实的自己\n']
有兴趣的同学可以再回看看我们处理数据的方法。
除此之外,我们还为数据建立了字典索引表 word_to_ix,字典有序列表 char_list,代表字典/字向量长度的 n_characters。
print("n_characters:", n_characters)
for i, key in zip(range(10), word_to_ix):
print(key, ":", word_to_ix[key])
n_characters: 3801
蜚 : 1687 减 : 1873 顺 : 120 九 : 1476 呀 : 1786 圆 : 1628 瓣 : 3474 霜 : 3012 锡 : 3346 撑 : 1642
# 观察有序列表中的元素即字典的有序排列
for ch in char_list[:10]:
print(ch, ":", word_to_ix[ch])
print(len(char_list))
抱 : 0 歉 : 1 我 : 2 依 : 3 旧 : 4 不 : 5 稳 : 6 定 : 7
: 8 鱼 : 9
3801
以及定义好了训练模型时使用的工具: random_training_set,它每次从数据集中随机选择出200条训练输入数据和200条目标数据,并转化为 Tensor。
数据方面万事俱备啦!让我们赶紧着手模型的训练吧!
资源:

让 RNN 开始嘻哈!
建立模型:
我们本次建立的神经网络模型共有三层。
第一层是一个“编码器(encoder)”,可以将我们输入的字(字向量)嵌入(映射)到一个“谜之空间”中。通过这种操作,可以将稀疏的字向量(维度为3801的字向量只有代表自己的位置为1,其余全为0)降维,减少循环神经网络(RNN)输入层的规模,从而让 RNN 学习的更快更好!
第二层是一种有特殊结构的循环神经网络(RNN),这次我们用的是 Gated Recurrent Unit(GRU),有兴趣的同学可以自行查找 GRU 的资料做深入了解。
第三层是一个“解码器(decoder)”,也就是将模型生成的结果从“谜之空间”中转回来,转成我们的“字向量”,继而表示成文字。
import torch
import torch.nn as nn
from torch.autograd import Variable
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
# 编码器
self.encoder = nn.Embedding(input_size, hidden_size)
# GRU
self.gru = nn.GRU(hidden_size, hidden_size, n_layers)
# 解码器
self.decoder = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
input = self.encoder(input.view(1, -1))
output, hidden = self.gru(input.view(1, 1, -1), hidden)
output = self.decoder(output.view(1, -1))
return output, hidden
def init_hidden(self):
return Variable(torch.zeros(self.n_layers, 1, self.hidden_size))
在训练之前,先让我们定义“超参数”,并实例化模型。
n_epochs = 3500 # 迭代次数
print_every = 500 # 每隔多少次迭代打印
plot_every = 10 # 每个多少次迭代记录图表值
hidden_size = 100 # 隐藏单元的数量
n_layers = 1 # 隐藏层层数
lr = 0.005 # 学习率
# 实例化RNN模型为decoder
decoder = RNN(n_characters, hidden_size, n_characters, n_layers)
# 本次使用 Adam 优化算法
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
# 使用交叉熵损失
criterion = nn.CrossEntropyLoss()
定义训练方法:
老规矩,先把训练函数定义好,方便迭代调用。
# inp,训练输入数据,包含200个字
# target,目标,包含200个字
def train(inp, target):
# 将隐藏层置零
hidden = decoder.init_hidden()
# 将模型的梯度置零
decoder.zero_grad()
# 损失值初始化
loss = 0
# chunk_len是在上节定义的训练数据及目标数据的长度
# 值为200
for c in range(chunk_len):
# 调用RNN的forward函数,进行一次正向传播
output, hidden = decoder(inp[c], hidden)
# 与目标值相比计算交叉熵损失
loss += criterion(output, target[c])
# 循环完200个字后进行一次反向传播
loss.backward()
decoder_optimizer.step()
# 返回平均损失
return loss.data[0] / chunk_len
定义模型验证方法:
验证方法就是测试方法,在模型训练后,我们就是直接调用它来让模型生成嘻哈说唱词。在模型训练的过程中我们也需要调用这个方法,以观察在训练的不同阶段模型生成嘻哈歌词的效果。
我在前面说过,RNN 模型生成嘻哈说唱词是通过“预测下一个字”来完成的,这就意味着在一开始,我们得先为模型指定一个“开头”,模型才能开始预测并生成后续的嘻哈歌词。
验证函数的第三个参数 temperature 起到标识“混乱度”的作用。关于“混乱度”的意义,我们在下面验证模型时再讲。
# prime_str:用户给的“开头”
# predict_len:要预测多少个字,每次产生歌词的长度
# temperature:混乱度
def evaluate(prime_str='我', predict_len=100, temperature=0.8):
# 隐藏层置零
hidden = decoder.init_hidden()
# 将我们给模型的“开头”转化为 Tensor
prime_input = char_tensor(prime_str)
# predicted保存生成的嘻哈歌词
predicted = prime_str
# 首先用用户给的“开头”运行模型的forward
# 也就是使用“开头”建立RNN隐藏层状态
for p in range(len(prime_str) - 1):
_, hidden = decoder(prime_input[p], hidden)
inp = prime_input[-1]
for p in range(predict_len):
# 输出以及隐藏层状态
output, hidden = decoder(inp, hidden)
# 根据“混乱度”从输出的多项式分布中采样
output_dist = output.data.view(-1).div(temperature).exp()
top_i = torch.multinomial(output_dist, 1)[0]
# 将采样的值转化为文字
predicted_char = char_list[top_i]
# 将模型预测出的字加入到predicted中
predicted += predicted_char
# 下一次预测的“输入”就是这次预测的输出
inp = char_tensor(predicted_char)
return predicted
开始训练!
终于到了这个激动人心的时刻!
import time, math
# 用于计算训练时间的函数
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
# 开始时间
start = time.time()
all_losses = []
loss_avg = 0
for epoch in range(1, n_epochs + 1):
loss = train(*random_training_set())
loss_avg += loss
# 每个一段时间,让模型生成一次看看效果
if epoch % print_every == 0:
print('[%s (%d %d%%) %.4f]' % (time_since(start), epoch, epoch / n_epochs * 100, loss))
print(evaluate('我', 100), '\n')
if epoch % plot_every == 0:
all_losses.append(loss_avg / plot_every)
loss_avg = 0
[4m 17s (500 14%) 4.4077]
我啪啪
吃饭脑壳
谁息
他们都想设法是我家
都来家
我们像过都来
他们眼疑
别惑的铁票儿
一辈的
......
[17m 20s (2000 57%) 5.6671]
我们年轻
因为我们
新疆
做到困难
我说
好多想你我的做音乐
让我穿过你摔定理害
让你我的生活
就像是否他们失败
......
[30m 43s (3500 100%) 4.0963]
我听
我早应重复
请你不想要
你知道我的话可是不会好与坏
不耍不值
不你麻烦
我打败他们只能说着我的他们
就会来及到
可以看到随着训练迭代次数的增加,生成的嘻哈说唱词越来越好!
分析模型
绘制图表,查看模型学习效果
首先把损失曲线画出来,观察一下模型训练是否“又好又快的发展”。
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
plt.figure()
plt.plot(all_losses)
[<matplotlib.lines.Line2D at 0x1163b6d68>]
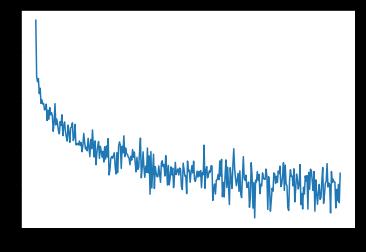
可以看到误差一直在减小,至后期有一些震荡,或许减小学习率(lr)能使训练更加稳定?
调整“混乱度”
上面遗留了一个“混乱度”的问题。
混乱度的意义是这样的:
当混乱度适中,才能生成较好的嘻哈歌词,既不会千篇一律,也不会出现每个字前后没有关联的情况。
print(evaluate('我的世界', 100, temperature=0.8))
我的世界
有铜磨灭
有我锤子事事情不止给你说
第来觉得我把人民是我锤子事
跟我们看你的眼神都遭到了
把到哪一天天上起副糕
我不是通利福尼亚
艾夫杰尼
你用戴着德我的土鸡炖
我一起长到的地边
我能像梦想
快把雪
当混乱度太低时,RNN 模型就趋向于选择“概率最大的下一个字”,注意哦!概率最大不代表效果最好。因为 RNN 模型是用固定的嘻哈歌词训练的,每次都选择“概率最大的下一个字”,意味着每次输出的值都一样。
print(evaluate('药药切克闹', 80, temperature=0.2))
药药切克闹
我们在一边的
我们的
我们的
我们的
我们的
我们的
我们
我们的
我们的
我们都是你的
我们都是我的
我们
我们都是我的
我们都是我的
我需要你的
我们
你
当混乱度太高时,RNN 模型趋向于选择“概率不大的下一个字”,实际产生的效果与随机选择类似,就像 RNN 模型没经过训练时的样子似的。
可以观察到“混乱度”太高时生成的嘻哈歌词几乎没有意义。
print(evaluate('药药切克闹', 80, temperature=1.4))
药药切克闹
学影愿这怒尸市
骆驼眼儿房降临
我意内来犯錯它低手话
沉灭电风枉天雾大自己善技能夠走掉梦变的生魂
垮青靠为每扯查幻都来说棋
直到欺
白边已工队放切不是爷英先
还可以进一步改进!
模型可以改进的地方还有很多。
第一,原始嘻哈歌词数据中包含有“英文歌词”,而我为了降低模型训练难度直接去掉了这些“英文歌词”。没有英文歌词的衔接,原歌词中有些句子转折会比较生硬,这也是模型最后生成的嘻哈歌词有时候衔接生硬的原因。
可以将原数据中的“整句英文歌词”视为“一个字”,给予映射成一个字向量,进行训练和生成。
第二,嘻哈说唱的灵魂是押韵!我们这次只考虑了“字”,没有考虑“音”。
“xpinyin”可以将文字转化为拼音。将押韵考虑进去可以打造生成双押韵乃至三押韵的嘻哈歌词模型,这也是我的“AI 有嘻哈2.0”计划!
课后作业
学习曲线波动率很大不是?尝试一下更小的学习率?
增加迭代次数、增加隐藏层层数、调整隐藏层单元数能够改进模型吗?
这是你的 FreeStyle 时间!
小仙女福利!
如果您课后作业有问题可以给小仙女发邮件:xiaoxiannv@swarma.org
本期关键词:【AI有嘻哈全】
长按空白位置_选择复制
PyTorch圣殿 | 传奇NLP攻城狮成长之路
课程表
本期:AI有嘻哈:训练评估模型 终篇
第四期:起名大师:使用RNN生成个好名字
第五期:AI翻译官:采用注意力机制的翻译系统
第六期:探索词向量世界
第七期:词向量高级:单词语义编码器
第八期:长短记忆神经网络(LSTM)序列建模
第九期:体验PyTorch动态编程,双向LSTM+CRF
更多职位内推点击阅读原文
如果您有任何关于Pytorch方面的问题,欢迎进【集智—清华】火炬群与大家交流探讨,添加集智小助手微信swarmaAI,备注(pytorch交流群),小助手会拉你入群。

推荐阅读
获取更多更有趣的AI教程吧!
学园网站:campus.swarma.org
商务合作|zhangqian@swarma.org
投稿转载|wangjiannan@swarma.org
以上是关于AI 有嘻哈 大结局 | 使用 PyTorch 搭建一个会说唱的深度学习模型的主要内容,如果未能解决你的问题,请参考以下文章