强大的PyTorch:10分钟让你了解深度学习领域新流行的框架
Posted 全球人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强大的PyTorch:10分钟让你了解深度学习领域新流行的框架相关的知识,希望对你有一定的参考价值。
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
——
——
——
摘要: 今年一月份开源的PyTorch,因为它强大的功能,它现在已经成为深度学习领域新流行框架,它的强大源于它内部有很多内置的库本文就着重介绍了其中几种有特色的库,它们能够帮你在深度学习领域更上一层楼。
PyTorch由于使用了强大的GPU加速的Tensor计算(类似numpy)和基于磁带的自动系统的深度神经网络。这使得今年一月份被开源的PyTorch成为了深度学习领域新流行框架,许多新的论文在发表过程中都加入了大多数人不理解的PyTorch代码。这篇文章我们就来讲述一下我对PyTorch代码的理解,希望能帮助你阅读PyTorch代码。整个过程是基于贾斯汀·的约翰逊伟大教程。如果你想了解更多或者有超过10分钟的时间,建议你去读下整篇代码。
PyTorch 由4个主要包装组成:
火炬:类似于Numpy的通用数组库,可以在将张量类型转换为(torch.cuda.TensorFloat)并在GPU上进行计算。
torch.autograd :用于构建计算图形并自动获取渐变的包
torch.nn :具有共同层和成本函数的神经网络库
torch.optim :具有通用优化算法(如SGD,Adam等)的优化包
1. 导入工具
可以你这样导入PyTorch:
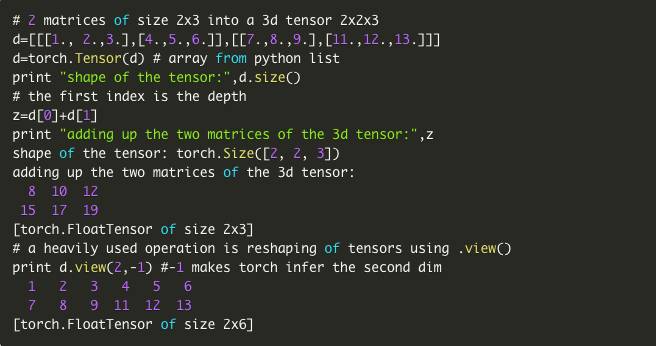
2.torch数组取代了numpy ndarray - >在GPU支持下提供线性代数
第一个特色,PyTorch提供了一个像numpy的数组一样的多维数组,当数据类型被转换为(torch.cuda.TensorFloat)时,可以在GPU上进行处理。这个数组和它的关联函数是一般的科学计算工具。
从下面的代码中,我们可以发现,PyTorch提供的这个包的功能可以将我们常用的二维数组变成GPU可以处理的三维数组。这极大的提高了GPU的利用效率,提升了计算速度。
大家可以自己比较Torch和numpy,从而发现他们的优缺点。
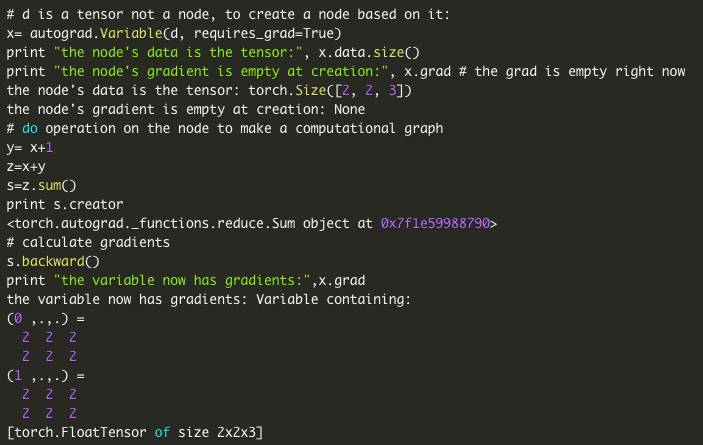
3.torch.autograd 可以生成一个计算图- > 自动计算梯度
第二个特色是autograd 包,其提供了定义计算图的能力,以便我们可以自动计算渐变梯度。在计算图中,一个节点是一个数组,边(边缘)是对数组的一个操作。要做一个计算图,我们需要在(torch.aurograd.Variable ())函数中通过包装数组来创建一个节点。那么我们在这个节点上所做的所有操作都将被定义为边,它们将是计算图中新的节点。图中的每个节点都有一个(node.data )属性,它是一个多维数组和一个(node.grad )属性,这是相对于一些标量值的渐变(node.grad也是一个。变量())在定义计算图之后,我们可以使用单个命令(loss.backward ())来计算图中所有节点的损耗梯度。
使用torch.autograd.Variable ()将张量转换为计算图中的节点。
使用x.data 访问其值。
使用x.grad 访问其渐变。
在.Variable ()上执行操作,绘制图形的边缘。
4.Tronch.nn 包含各种NN 层(张量行的线性映射)+ (非线性) - >
其作用是有助于构建神经网络计算图,而无需手动操纵张量和参数,减少不必要的麻烦。
第三个特色是高级神经网络库(torch.nn ),其抽象出了神经网络层中的所有参数处理,以便于在通过几个命令(例如torch.nn.conv )就很容易地定义NN 。这个包也带有流动的损失函数的功能(例如torch.nn.MSEloss )。我们首先定义一个模型容器,例如使用(torch.nn.Sequential )的层序列的模型,然后在序列中列出我们期望的这个高级神经网络库也可以处理其他的事情,我们可以使用(model.parameters ())访问参数(Variable ())
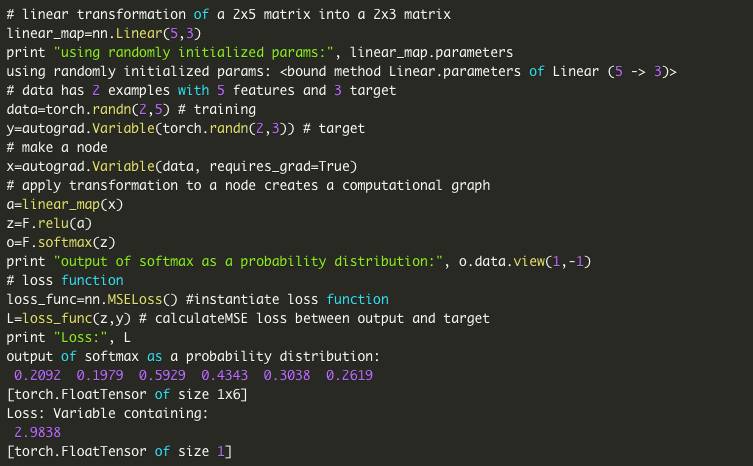
我们还可以通过子类(torch.nn.Module )定义自定义层,并实现接受(Variable ())作为输入的(forward ())函数,并产生(Variable ())作为输出我们也可以通过定义一个时间变化的层来做一个动态网络。
定义自定义层时,需要实现2 个功能:
_ init_函数必须始终被继承,然后层的所有参数必须在这里定义为类变量(self.x )
正向函数是我们通过层传递输入的函数,使用参数对输入进行操作并返回输出。输入需要是一个autograd.Variable (),以便pytorch 可以构建图层的计算图。

5.torch.optim 也可以做优化- >
我们使用torch.nn 构建一个神经网络计算图,使用torch.autograd 来计算梯度,然后将它们提供给torch.optim 来更新网络参数。
第四个特色是与NN 库一起工作的优化软件包(torch.optim )。该库包含复杂的优化器,如Adam ,RMSprop 等。我们定义一个优化器并传递网络参数和学习率(opt = torch .optim.Adam (model.parameters (),lr = learning_rate ))然后我们调用(opt.step ())对我们的参数进行近一步更新。
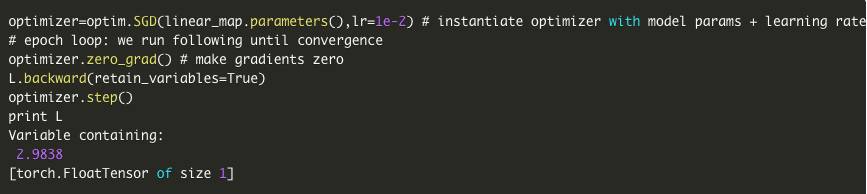
建立神经网络很容易,但是如何协同工作并不容易这是一个示例显示如何协同工作:
希望上述的介绍能够帮你更好的阅读PyTorch代码。
系统学习,进入全球人工智能学院
以上是关于强大的PyTorch:10分钟让你了解深度学习领域新流行的框架的主要内容,如果未能解决你的问题,请参考以下文章