一个优雅的框架 | Pytorch 初体验
Posted 人工智能LeadAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个优雅的框架 | Pytorch 初体验相关的知识,希望对你有一定的参考价值。
pytorch是啥呢?其实pytorch是一个python优先的深度学习框架,是一个和tensorflow,Caffe,MXnet一样,非常底层的框架,它的前身是torch,主要的语言接口是Lua,在如今github上前10的机器学习项目有9个都是python的时代,一直没有太多的人使用,比较小众。而pytorch如今重新归来,用python重写了整个框架,又重新回到了我的视线。
现在流行的深度学习框架都有着金主爸爸的支持,tensorflow是Google开发的,当然是他的官方框架,MXnet是Amazon的官方框架,那么pytorch后面站着的男人是谁呢?那就是Facebook了,其同样也只是Deep Learning领域的巨头,近期FAIR(Facebook Artificial Intelligence Research)也出了很多大作如mask rcnn,所以说pytorch背后的力量也是很大的。
说完了每个框架的支持者之外,我们来说说为什么我们还要学习不同的框架。首先在如今这个百花齐放的时代,任何一家公司想要独大都是不可能的,因为大家都意识到了这是一个随时可能爆发巨大变革的时代,所以每家大公司都希望自己能够在这场变革中扮演主导的地位,这就导致了不同的公司就会自己开发框架,或者至少不会使用竞争的公司的框架。在如今这个框架百出的时代,并没有哪个框架是最好的,每个框架都有各自的有点,比如tensorflow的工程能力很强,Theano特别适合科研等等,所以我们有必要掌握不同的框架,不要说精通每个框架,至少能够看看这个框架下的代码,因为github上不断地有牛人论文复现,而他们用的框架肯定不会都是一样的,所以你至少要能够阅读别人写的在各个框架下的代码。
说完了为什么要使用不同的框架之后,我们再来介绍一下今天的主角pytorch。之前我们介绍过keras,pytorch不同于keras,keras是一个很高层的结构,它的后端支持theano和tensorflow,它本质上并不是一个框架,只是对框架的操作做了一个封装,你在写keras的时候其实是对其后端进行调用,相当于你还是在tensorflow或者theano上跑程序,只不过你把你的语言交给keras处理了一下变成tensorflow听得懂的语言,然后再交给tensorflow处理,这样的后果当然方便你构建网络,方便定义模型做训练,极快的构建你的想法,工程实现很强,但是这样也有一个后果,那就是细节你没有办法把控,训练过程高度封装,导致你没有办法知道里面的具体细节,以及每个参数的具体细节,使得调试和研究变得很困难。
所以说作为初学者,我们可以用一个模块化的第三方插件帮助我们快速进入深度学习这个领域,但是如果我们真的想要好好去研究里面的问题,好好去做分析,我们还是需要用到我们的底层框架。
这个时候你就会说那我们就用tensorflow就好了啊,这不是最流行的框架吗。tensorflow确实是现在用的人最多的框架,不可否认,但是我们多掌握多了解一些框架也是有必要的,说不定你可以找到你最钟爱的那个框架呢。
相对tensorflow而言,pytorch就优雅多了,通过它的名字你就知道其对python支持特别好,虽然它的底层优化仍然实在c上的,但是它基本所有的框架都是用python写的,这就使得你去看它的源码比较简洁。但是它的缺点也和明显,就是框架刚刚发布没有多久,还没有太多人使用,文档也还在完善当中,但是也绝对够用了。有一个有好处就是你可以去官方论坛上面提问,基本上很快就有人回答了,这也算是新框架的一个好处吧,就是开发者对用户比较在意。
聊完了这么多好与不好,不知道你是不是动心了呢,是不是想学习pytorch了呢。如果你想学习pytorch,很简单,你直接去pytorch的官方教程就可以了,这是教程的链接 http://pytorch.org/tutorials/ 这里是是官方网站的连接 http://pytorch.org/ 最多1个小时,你就能入门了,比tensorflow简单太多了,如果你很牛逼,你还可以在pytorch的github开源项目上贡献你的代码,是不是很酷。这是pytorch的github主页 https://github.com/pytorch/pytorch
最后放上一段pytorch写的Lenet,可以和上一篇keras写的Lenet对比一下,看看有哪些差别。
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.autograd
import Variablefrom torch
import optimimport torch.nn as nn
import torch.nn.functional as F
learning_rate = 1e-3
batch_size = 100
epoches = 50
trans_img = transforms.Compose([
transforms.ToTensor() ])
trainset = MNIST('./data', train=True, transform=trans_img)
testset = MNIST('./data', train=False, transform=trans_img)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=4) testloader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=4)
# build network
class Lenet(nn.Module):
def __init__(self):
super(Lenet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5, stride=1, padding=0),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
lenet = Lenet()
lenet.cuda()
criterian = nn.CrossEntropyLoss(size_average=False)
optimizer = optim.SGD(lenet.parameters(), lr=learning_rate)
# trainfor
i in range(epoches):
running_loss = 0.
running_acc = 0.
for (img, label) in trainloader:
img = Variable(img).cuda()
label = Variable(label).cuda()
optimizer.zero_grad()
output = lenet(img)
loss = criterian(output, label)
# backward
loss.backward()
optimizer.step()
running_loss += loss.data[0]
_, predict = torch.max(output, 1)
correct_num = (predict == label).sum()
running_acc += correct_num.data[0]
running_loss /= len(trainset)
running_acc /= len(trainset)
print("[%d/%d] Loss: %.5f, Acc: %.2f" %(i+1, epoches, running_loss, 100*running_acc))
这上面的代码定义了网络并进行了训练,下面是训练结果
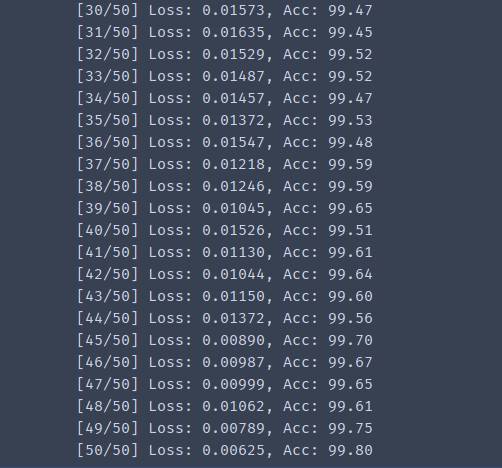
训练结果
# evaluate
lenet.eval()
testloss = 0.
testacc = 0.
for (img, label) in testloader:
img = Variable(img).cuda()
label = Variable(label).cuda()
output = lenet(img)
loss = criterian(output, label)
testloss += loss.data[0]
_, predict = torch.max(output, 1)
num_correct = (predict == label).sum()
testacc += num_correct.data[0]
testloss /= len(testset)
testacc /= len(testset)
print("Test: Loss: %.5f, Acc: %.2f %%" %(testloss, 100*testacc))
这是测试代码,以及测试结果

测试结果
本文代码已经上传到github上,这是传送门 https://github.com/SherlockLiao/lenet
如想了解更多文章,欢迎访问我的博客,很多干货 https://sherlockliao.github.io/
欢迎访问的我的github主页 https://github.com/SherlockLiao
原文链接:http://www.jianshu.com/p/6b96cb2b414e
sherlock Liao,专注于优质原创内容创作,知乎ID:Sherlock 欢迎关注我的知乎专栏 深度炼丹

往期精彩回顾
以上是关于一个优雅的框架 | Pytorch 初体验的主要内容,如果未能解决你的问题,请参考以下文章