ICLR-17最全盘点:PyTorch超越TensorFlow,三巨头HintonBengioLeCun论文被拒,GAN泛滥
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ICLR-17最全盘点:PyTorch超越TensorFlow,三巨头HintonBengioLeCun论文被拒,GAN泛滥相关的知识,希望对你有一定的参考价值。
新智元报道
来源: ICLR 等
报道:胡祥杰、刘小芹
新智元启动 2017 最新一轮大招聘:。
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
【新智元导读】机器学习&深度学习盛会 ICLR 2017 落下帷幕。本届会议都有哪些亮点?体现了哪些技术变化及趋势?对整个 AI 业界有什么影响?新智元为你带来最全面的总结。
为期三天的深度学习盛会 ICLR 4月26日落下帷幕。
ICLR 2017 于 4 月 24 日星期一开始,到 26 号结束。每天分上午下午两场。每场形式基本一样,先是请来的人发表演讲(invited talk),然后是讨论,也是被选为能够进行口头发表(Oral)的论文、茶歇、海报展示(poster)。

ICLR 2017在法国城市图仑举行,图来自Andrej Karpathy Medium文章
从受邀讲者名单看,ICLR 2017 似乎是在力推深度学习领域各界的新锐。不仅如此,由于聚焦的是深度学习,会议关注的内容也更为有针对,以下是官网列出来的大会主要关注内容:
- 无监督、半监督和监督的表示学习
- 规划和强化学习的表示学习
- 度量学习和内核学习
- 稀疏编码和维度扩展
- 分层模型
- 表征学习的优化
- 学习输出或状态的表征
- 实施问题、并行化、软件平台和硬件
- 视觉、音频、语音、自然语言处理、机器人、神经科学或任何其他领域的应用
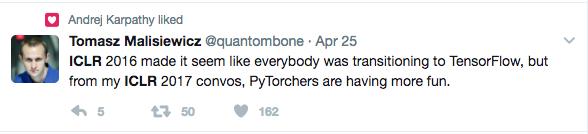
Magic Leap 首席工程师 Tomasz Malisiewicz 在推特上表示,去年的ICLR似乎每个人都在向TensorFlow靠拢,但是,从他参加今年的大会的体验来看,PyTorch正在变得越来越有趣。
华人学者魏秀参此前发表了一篇对ICLR论文总体情况进行分析的文章,他在文章中说,今年 ICLR 中涉及 GAN 和 Reinforcement Learning 的工作巨多,间接反映了无监督学习和强化学习今后一段时间内在 DL 领域内的势头。另外还有不少把应用问题(如,VQA)刷到新 SoA 的工作。
实际的论文接收情况:根据Open AI 研究员 Andrej Karpathy 在Medium 上发布的统计,本届ICLR,总共有491篇论文提交,15篇(3%)最终获得口头展示(oral)的机会,183篇(37.3%)获得海报展示(poster)机会,还有48篇(9.8%)被建议以 workshop 的形式展示。被拒绝的论文为245篇(49.9%)。
使用 OpenReview(而不是 CMT)作为会议通道。此外,提交的论文将交由 OpenReview 管理(无需提交到 arXiv)。
审查程序将变成两轮。第一轮中,审稿人只能提出澄清性的疑问。程序委员会将评出最佳审稿奖,得奖的审稿人将被列入 ICLR 2018 的候选人名单中。研讨会通道鼓励那些具有高度创新性,但可能未得到充分验证的提交论文。
评审委员会说,采用 OpenReview 的目标是提高整体审稿过程的质量。OpenReview 可以让作者随时对论文的评论进行回复。此外,社区中的任何人都可以对提交的论文进行评论,审稿者可以利用公开讨论来提高他们对论文的理解和评级。
不过,2017年ICLR的匿名评审环节曾引起过巨大的争议,起因是DeepMind 和剑桥大学以及加拿大CIFAR合作的一篇论文《Lipnet: End-To-End Sentence-level Lipreading》。该论文在投给ICLR 前,曾在媒体上引起广泛关注,被认为是有语言缺陷者的福音。

论文摘要
读唇语指的是从讲话者嘴的运动中解码出文本。传统的方法把这一问题的解决分为两个步骤:设计或者学习视觉特征,然后是预测。更多的最新深度唇语理解方法都是端到端可训练的。但是,既有的、基于端到端模型训练的方法,只能完成词的分类,而不是句子级别的序列预测。研究发现,人类读唇语时的表现会随着词的长度增加而变好,这意味着,在一个模糊不清的交流渠道中,捕捉临时文本特征的重要性。
受这一观察的启发,我们提出了LipNet,这是一个能将长短不一的视屏帧中转换为文本的模型,利用时空卷积(spatiotemporal convolutions)、一个循环网络以及分类损失的临时连接性,实现完全端到端的训练。
据我们所知,LipNet 是首个端到端的句子级别的唇语阅读模型,能同步地学习时空的视觉特征和一个序列模型。在GRID数据库上,LipNet 实现了95.2%的句子级别准确率,并完成说话者区分任务。在准确率上超越了人类的唇语阅读者,以及此前词语级别中86.4%的准确率。
https://openreview.net/pdf?id=BkjLkSqxg
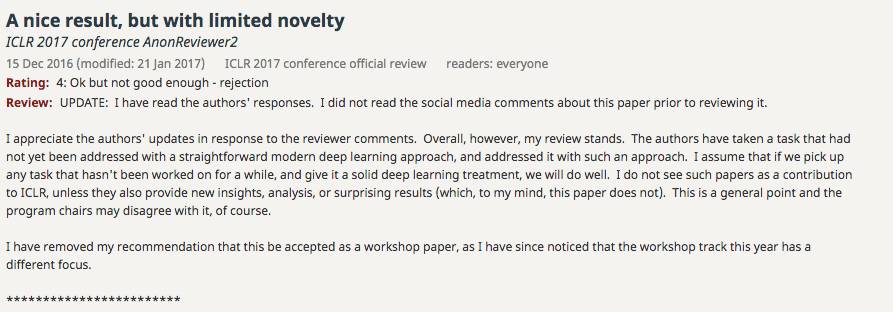
一名评审委员在Open Reiview ( https://openreview.net/forum?id=BkjLkSqxg¬eId=BkjLkSqxg)上对这篇论文的点评是: 我不认为这种论文对ICLR有任何贡献,除非他们还能提供新的见解,分析或令人惊讶的结果(在我看来,本文并没有)。这是我的总体观点,当然程序主席可能不同意。我已经撤销了推荐该论文进入workshop的建议,因为我注意到今年的workshop有不同的重点。
随后,论文作者 Nando de Freitas 在该评论后进行了回复,称评审委员的意见是 “全然居高临下的、无礼的和不值一提的”,“不合理的、完全主观的”,甚至是“绝对废话”,“绝大多数做深度学习的人都不会同意的”,还说“你根本不理解我们的研究”。
以上评论发出后,迅速在Open Review 网站和社交媒体上引起广泛关注,不少人加入到讨论中来。除去论文本身,还讨论到了ICLR 作为一个公共社区应该保持的基本交流准则、社交媒体与专业会议对待科学技术的态度差异等问题。
不久以后,ICLR评审委员会对这篇论文作出了“终审裁决”:
首先我得说明,领域主席(aiea chair)不看 Twitter,Reddit / ML 等等。因此,下面的评论纯粹基于论文本身以及 OpenReview 上的评论和反驳。
ICLR 审查过程的目的是在作者和审查者(以及更广泛的机器学习社区)之间形成有建设性的讨论。这些讨论的目的是帮助作者改进它们的论文。
虽然有人可能会认为一些初审意见影响了他们的评级,但没有证据显示审查人员被这篇论文在社交媒体或其他媒体上的讨论影响到(甚至没有意识到),实际上,这篇论文的评审意见都没有提及那些媒体的讨论。这篇论文的作者们认为审稿人对(社交)媒体持有偏见的质疑是毫无根据的:审稿人和作者之间对这项研究的新颖性、独创性以及重要性存在意见分歧,这有很多原因。作者可以对审稿人的意见进行辩驳,但将评审意见成为“无稽之谈”,“不合理”,“居高临下”以及“不尊重”无助于 ICLR 设想的有建设性的科学讨论,坦率地说,这对为了提高我们的领域的科学研究质量而无偿花费时间的审稿人非常冒犯。
两位领域主席阅读了这篇论文。他们独立得出的结论如下:(1)审稿人对这项研究的新颖性和重要性表示认可;(2)这篇论文实际上超出了ICLR的边界(borderline)。这篇论文是一篇应用性的文章,作者提出使用深度学习实现端到端的句子级别唇语阅读。
论文的积极方面包括:
对前人研究进行了全面、系统的回顾;
对模型和实验方法进行了清楚的描述;
详细说明了结果,注意了细节;
提出的方法看似比先前的最佳方法表现更好,并推广到不同说话者。
但是,这篇论文也有几个明显的不好的方面:
用在实验中的 GRID 语料库有很大的限制。特别是,它以导致非常有限的(不自然的)句子的方式构建。(对每个单词,模型可以选择的平均只有8.5个选项。)
这篇论文夸大了其中一些结论。尤其是,该模型“超越了经验丰富的人类唇语阅读者”的说法是值得怀疑的:很可能模型是利用语料库中不实际的统计偏差来实现其性能表现,而人类不能/不必利用这些。类似地,关于模型的“句子级别”(sentence-level)的性质也没有得到证实:尚不清楚模型的哪个方面可以证明这是一个“句子级别”的模型,也没有实证证据能表明视频数据中的句子级别处理有很大帮助(NoLM基线模型与LipNet的表现几乎一样好,但 GRID 语料库有很强的偏差。)
这篇论文还提出了另外几个不充分的论点。正如评审之一所指出的,McGurk 效应不能说明阅读唇语在人类的交流中有至关重要的作用(麦格克效应仅仅是说明眼睛看到口型会影响人对声音的辨识)。
这篇论文最严重的一个缺点是,在研究深度学习的相关应用时,没有提出对本文所研究的应用之外有影响的技术贡献或创新的见解。
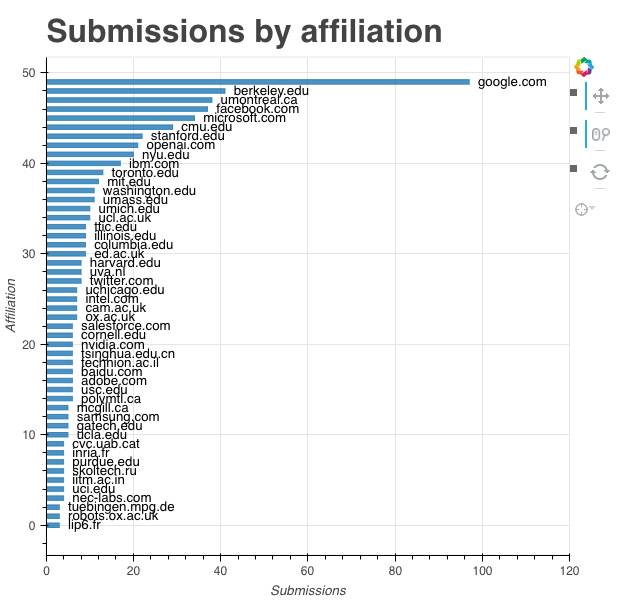
各大机构投稿论文数量,谷歌最多,有近100篇,其次是伯克利。
一个有意思的角度是官网还列出了被拒收轮的列表。根据上文Kapathy的统计,本届ICLR 被拒的论文有245篇,占到了投稿总数的49.9%,在官方公开的被拒论文列表中,我们看到了很多知名深度学习领军人物的名字,包括大名鼎鼎的“三大神”:Geoffrey Hinton、Yann LeCun 和 Yoshua Bengio 。
被拒绝的论文大牛(部分):



Medium上,博客主 Carlos E. Perez写了一篇《10篇值得一读的ICLR-17 被拒论文》,感兴趣的读者可以去看看:

https://medium.com/intuitionmachine/eight-deserving-deep-learning-papers-that-were-rejected-at-iclr-2017-119e19a4c30b
24 号
上午
演讲:Eero Simoncelli 霍华德·休斯医学研究所研究员,纽约大学艺术与科学学院教授,IEEE Fellow。研究领域:计算机视觉。
Talk 1:端到端优化的图像压缩(End-to-end Optimized Image Compression)
Talk 2:图像超分辨率的摊分MAP推断(Amortised MAP Inference for Image Super-resolution)
茶歇
海报1
午饭
下午
演讲:Benjamiin Recht,加州伯克利大学电子工程和计算机科学学院副教授,研究领域:智能系统,机器人,控制论,信号处理,优化。《Understanding Deep Learning Requires Rethinking Generalization》第四作者
Talk 3:理解深度学习需要重新思考泛化(Understanding deep learning requires rethinking generalization )——最佳论文奖
Talk 4:深度学习的大批量训练:泛化间隔和尖最小值(Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima)
Talk 5:训练生成式对抗网络的原则方法(Towards Principled Methods for Training Generative Adversarial Networks)
茶歇
海报2
25 号
上午
演讲:Chloe Azencott,法国巴黎高等矿业学院计算生物学系,法国巴黎居里研究所及法国国家科研中心研究员。研究方向:用于治疗研究的机器学习技术
Talk 1:从私有训练数据实现深度学习的半监督知识转移(Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data) ——最佳论文
Talk 2:学习图形状态转换(Learning Graphical State Transitions)
茶歇
海报1
午饭
下午
演讲:Riccardo Zecchina,意大利博科尼大学理论物理学教授,都灵人类基因基金会项目负责人。研究领域:统计物理学,机器学习,计算神经科学及计算生物学,反动力学问题,组合优化的分布式算法等。
Talk 3:学习通过预测未来行动(Learning to Act by Predicting the Future)
Talk 4:使用无监督辅助任务的强化学习(Reinforcement Learning with Unsupervised Auxiliary Tasks)
Talk 5:Q-Prop:使用 Off-Policy Critic 的有效策略梯度(Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic)
海报2
26号
上午
演讲:Regina Barzilay,美国麻省理工大学电气工程及计算机科学系教授,微软研究员,麻省理工大学自然语言处理研究小组成员。研究方向:自然语言处理。
Talk 1:学习端到端的目标导向对话(Learning End-to-End Goal-Oriented Dialog)
Talk 2:多代理合作与自然语言的出现(Multi-Agent Cooperation and the Emergence of (Natural) Language)
下午
演讲:Alex Graves,加拿大多伦多大学计算机科学系下辖加拿大高等研究院初级研究员。研究方向:循环神经网络,监督下的序列化标签,无监督的序列学习
Talk 3:通过递归实现神经编程架构通用化(Making Neural Programming Architectures Generalize via Recursion)——最佳论文奖
Talk 4:神经架构搜索与增强学习(Neural Architecture Search with Reinforcement Learning)
Talk 5:作为一种 Few-Shot Learning 的优化(Optimization as a Model for Few-Shot Learning)
海报2
6 位受邀演讲嘉宾介绍:
Eero Simoncelli 霍华德·休斯医学研究所研究员,纽约大学艺术与科学学院教授,IEEE Fellow。研究领域:计算机视觉。
Benjamiin Recht,加州伯克利大学电子工程和计算机科学学院副教授,研究领域:智能系统,机器人,控制论,信号处理,优化。《Understanding Deep Learning Requires Rethinking Generalization》第四作者。
Chloé-Agathe Azencott,法国巴黎高等矿业学院计算生物学系,法国巴黎居里研究所及法国国家科研中心研究员。研究方向:用于治疗研究的机器学习技术。
Riccardo Zecchina,意大利博科尼大学理论物理学教授,都灵人类基因基金会项目负责人。研究领域:统计物理学,机器学习,计算神经科学及计算生物学,反动力学问题,组合优化的分布式算法等。
Regina Barzilay,美国麻省理工大学电气工程及计算机科学系教授,微软研究员,麻省理工大学自然语言处理研究小组成员。研究方向:自然语言处理。
Alex Graves,DeepMind 研究员,加拿大多伦多大学计算机科学系下辖加拿大高等研究院初级研究员。研究方向:循环神经网络,监督下的序列化标签,无监督的序列学习。
最佳论文一是来自伯克利,题目是《通过递归实现神经编程架构通用化》。

摘要
根据经验,试图从数据中学习编程的神经网络显示出较差的通用性。此外,当输入的复杂度超过了一定水平,就很难去推断这些模型的表现。为了解决这个问题,我们提出用一个关键抽象——递归(recursion)来增强神经架构。作为一个应用,我们在神经编程器-解释器框架(Neural Programmer-Interpreter framework)上实现递归,包括四个任务:小学加法、冒泡排序、拓扑排序和快速排序。我们使用少量训练数据证明了该方法具有较好的可泛化性和可解释性。递归将问题分割成一个个更小的部分,并且大大减少每个神经网络组件的域,使其易于证明对整个系统行为的担保。我们的经验表明,为了让神经架构更稳健地学习程序语义(program semantics),有必要引入这样一个“递归”方法。
【ICLR 委员会最终决定】评委非常肯定该论文。该论文所讨论的话题很有意义,并且探讨了一个实用的方法。
最佳论文二:《通过半监督知识传递,使用私密训练数据进行深度学习》
第二篇最佳论文是来自宾夕法尼亚州立大学、谷歌(包括谷歌和谷歌大脑),以及 OpenAI 的研究人员合作完成的《通过半监督知识传递,使用私密训练数据进行深度学习》。
看到作者里 Ian Goodfellow 的名字,你想到了——没有错!这篇文章也使用了GAN,是近来有关差分隐私深度学习的一篇好文章。

摘要
有些机器学习应用涉及敏感训练数据,比如临床试验中患者的医疗史。模型可能无意和隐含地存储一些训练数据;因此仔细分析模型可能会泄露敏感信息。
为了解决这个问题,我们展示了一个普遍适用的方法,为训练数据提供强有力的隐私保证。该方法以一种黑盒的方式,结合了多个使用不相交数据集训练的模型,例如不同子集用户的记录。由于这些模型都直接依赖敏感数据,因此都是不公开的,作为教育“学生”模型的“教师”。学生通过学习所有教师的噪音投票来预测输出,不能直接访问单独的教师,也无法获取基础数据或参数。学生的隐私属性可以从直观上去理解(因为没有哪个教师能单独决定学生的训练,也就没有哪个单独的数据集能决定学生的培训),也能通过差分隐私(differential privacy)的方式被正式地理解。即使有攻击者(adversary)既能访问查询(query)学生,也能审查(inspect)其内部机制,学生的隐私属性也不会改变。
与此前的工作相比,这种新的方法对教师是如何训练的抱有很弱的假设(weak assumption);并且适用于任何模型,包括像深度神经网络(DNN)这样的非凸模型。得益于改进后的隐私分析和半监督学习,我们在隐私和实用性(utility trade-off)方面,在 MNIST 和 SVHN 上取得了最好的结果。
【一句话总结】通过一组在私密数据分区上训练的教师的集合进行知识传递,让带有对抗生成网络、能够保护隐私的学生模型进行半监督学习。
【ICLR 委员会最终决定】论文提出了一种用于差分隐私的、通用的教师-学生学习方法,其中学生通过学习一组教师的噪音投票进行预测。噪音使得学生能够拥有差分隐私,同时在 MNIST 和 SVHN 上取得很好的分类结果。论文写得很好。
最佳论文三:Bengio 兄弟对决之重新理解深度学习的泛化
无需置疑,这可真是篇备受争议的最佳论文。
还是先来回顾内容。

摘要
尽管体积巨大,成功的深度人工神经网络在训练和测试性能之间可以展现出非常小的差异。过去一般将其归功于泛化误差小,无论是对模型谱系的特点还是对于训练中使用的正则技术来说。
通过广泛的系统的实验,我们展示了传统方法无法解释为什么大规模神经网络在实践中泛化表现好。 具体来说,我们的实验证明了用随机梯度方法训练的、用于图像分类的最先进的卷积网络很容易拟合训练数据的随机标记。这种现象本质上不受显式正则化影响,即使我们通过完全非结构化随机噪声来替换真实图像,也会发生这种现象。我们用一个理论结构证实了这些实验结果,表明只要参数的数量超过实践中通常的数据点的数量,简单两层深的神经网络就已经具有完美的有限样本表达性(finite sample expressivity)。我们通过与传统模型进行比较来解释我们的实验结果。
【一句话总结】通过深入系统的实验,我们指出传统方式无法解释为什么大规模神经网络在实践中泛化表现良好,同时指出我们为何需要重新思考泛化问题。
【ICLR 评委会最终决定】作者提供了深度神经网络拟合随机标注数据能力的迷人研究结果。调查深入,有启发性,鼓舞人心。作者提出了a)一个理论实例,显示具有大量参数和足够大的 wrt 样本的简单浅层网络产生了完美的有限样本表达性;b)系统广泛的实验评价,以支持研究结果和论点。实验评价的考虑非常周全。
【编注】关于这篇“重新理解泛化”的文章,Open Review 网站上还有更多的讨论。实际上,这篇文章也可以算是近来“最受争议的最佳论文”——了解更多,请参见新智元此前的报道
首届 ICLR 2013年在美国亚利桑那州的斯科茨代尔市举办,发起人是深度学习的领军人物Yann LeCun 和 Yoshua Bengio。

在这次大会上,深度学习的另一位大神级人物 Geoffrey Hinton 受邀发表演讲。并且,当年的赞助商只有三家:NEC 实验室、微软研究院和谷歌。
本年度的ICLR赞助商已经达到了18家,分为白金、金牌、银牌和铜牌四个等级。金牌赞助商囊括了世界上顶级的AI公司:亚马逊、百度、DeepMind、Facebook、谷歌、英特尔、英伟达和Saleforce。
另外,从论文投稿数量、参会人数和媒体关注度上来看,ICLR也已经成为当下人工智能,特别是深度学习质量最高的学术会议之一。
从2016年年末开始,ICLR 在社交媒体和学术圈内中的关注度一直非常高。正如其官网写道,大会关注的关键词:无监督、半监督和监督的表示学习、规划和强化学习的表示学习和表征学习的优化等等话题,一直都是关于一年中大家热议的话题。同时,我们也看到,在大会的各个环节,今年获得广泛关注的GAN(对抗生成网络)几乎无处不在,成为大家讨论的一个热门话题。
2017年以来,新智元观察到,机器自主编程的研究工作受到广泛关注。本届ICLR的最佳论文中,有一篇是以 ICLR-16 的最佳论文为基础做了提升——ICLR 2016 的最佳论文,DeepMind 团队开发了一个“神经编程解释器”(NPI),能自己学习并且编辑简单的程序,排序的泛化能力也比序列到序列的 LSTM 更高。
Facebook 研究员田渊栋曾经公开分享过他的观察,他说,在ICLR上,像“让计算机自己写代码”这个想法,在去年的文章里还出现得不多,并且主要是以构建可微分计算机(比如说DeepMind的神经图灵机,可微分神经计算机)的形式,让神经网络通过端对端的梯度下降的优化方法,学会如求和排序等具体任务。但是这个思路有几个比较大的问题,一个是因为神经网络的黑箱性质,对可微分计算机学习后使用的算法没办法解释;第二个是梯度下降法取决于初值的选取,且优化过程较慢;第三个是扩展性不好,对60个数排序可以,100个数就完全不行,有悖人类的直觉。而让计算机生成代码则没有1和3这两个问题,2也可以通过预先训练神经网络生成代码来克服,不通过优化,而用一遍前向传播就可以了。
他们们的第二篇投稿就是基于这个想法,将算法的输入输出的结果抽取特征后,送入卷积神经网络文献中层次式生成图像的经典框架,生成一张二维图,每行就是一行代码,或者更确切地说,是代码的概率分布。有了好的分布,就可以帮助启发式搜索找到正确的程序。而神经网络的训练数据,则由大量的随机代码,随机输入及随机代码执行后得到的输出来提供,所以基本不需要人工干预,算是非监督的办法。
由 Yann LeCun 和 Yoshua Bengio 等大牛发起的 ICLR 会议虽然年轻,但却已经成为深度学习界不可忽视的盛事之一。以 arXiv 为基础起家的 ICLR 比 NIPS、CVPR 迭代的速度更快、评判的标准也更为“平易近人”:ICLR 的一个主要成因就是要聚在一起讨论那些好却被顶会拒之门外的论文。
在今年“匿名评审”环节的争议事件中,我们看到,评审委员会坚持独立、中立、公开的原则。首先将评审过程全部公开,其次没有受到舆论的影响,有态度有理据地进行最后“裁决”。
毫无疑问,不管是学术界还是企业界,都需要这样的专业会议来促进研究者之间的交流,共同推动研究进步。在这一点上,ICLR 做到了。
新智元招聘
职位:客户经理
职位年薪:12 - 25万(工资+奖金)
工作地点:北京-海淀区
所属部门:客户部
汇报对象:客户总监
工作年限:3 年
语 言:英语 + 普通话
学历要求:全日制统招本科
职位描述:
精准把握客户需求和公司品牌定位,策划撰写合作方案;
思维活跃、富有创意,文字驾驭能力强,熟练使用PPT,具有良好的视觉欣赏及表现能力,PS 能力优秀者最佳;
热情开朗,擅长人际交往,良好的沟通和协作能力,具有团队精神;
优秀的活动筹备与执行能力,较强的抗压能力和应变能力,适应高强度工作;
有4A、公关公司工作经历优先;
对高科技尤其是人工智能领域有强烈兴趣者加分。
岗位职责:
参与、管理、跟进上级指派的项目进展,确保计划落实。制定、参与或协助上层执行相关的政策和制度。定期向公司提供准确的市场资讯及所属客户信息,分析客户需求,维护与指定公司关键顾客的关系,积极寻求机会发展新的业务。建立并管理客户数据库,跟踪分析相关信息。
应聘邮箱:jobs@aiera.com.cn
HR微信:13552313024
新智元欢迎有志之士前来面试,更多招聘岗位请点击查看。
以上是关于ICLR-17最全盘点:PyTorch超越TensorFlow,三巨头HintonBengioLeCun论文被拒,GAN泛滥的主要内容,如果未能解决你的问题,请参考以下文章