PyTorch 特辑!网红 5 分钟带你入门 PyTorch
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 特辑!网红 5 分钟带你入门 PyTorch相关的知识,希望对你有一定的参考价值。
关注 AI 研习社后,回复【1】获取
【千 G 神经网络 / AI / 大数据、教程、论文!】
---------------------------------------------
Siraj Raval 作为深度学习领域的自媒体人在欧美可以说是无人不知、无人不晓。
凭借在 Youtube 上的指导视频,Siraj Raval 在全世界吸粉无数,堪称是机器学习界的网红。说他是全球范围内影响力最大的 ML 自媒体人,怕也无异议。
因此,雷锋网 AI 研习社联系到了Siraj 本人,并获得授权将他最精华的 Youtube 视频进行字幕汉化,免费推送给大家。我们将不定期更新,敬请关注!
今天 Siraj 跟大家讲讲 PyTorch(点击文末阅读原文抵达 GitHub)。
视频主要介绍了PyTorch的两大特性以及与Tensorflow 的比较,内容浅显易懂,有丰富的实例展示。关注今年 ICLR 的小伙伴们一定注意到了 Pytorch 崛起迅猛,如果你还在 Pytorch 与 Tensorflow 之间纠结的话,不妨看看该视频,相信一定能获得心中的答案。
(建议在Wi-Fi环境下观看视频,土豪随意~)
为了方便流量不足的小伙伴们在路上看,我们特意整理出了文字版和动图~
PyTorch这个名字来源于知名深度学习框架Torch。Torch是用Lua语言写的,对于才开始接触深度学习的人而言,学习Lua入门艰难。这是因为Lua没有模块化功能,不像更易于上手的编程语言那样会提供友好的外部库交互接口。所以几名AI研究员受Torch的编程风格启发,决定在Python环境中实现Torch,也就有了PyTorch。
开发者还给PyTorch增加了一些很酷的功能,Siraj主要介绍了其中两点:
1. PyTorch的第一个关键特性是命令式编程
命令式编程就是输入什么便执行什么。大部分Python代码都是命令式的。以这个NumPy为例:
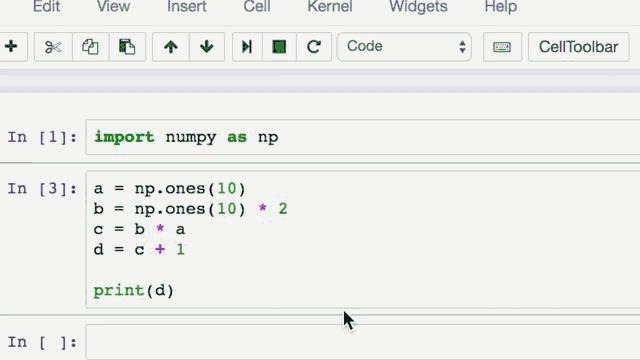
我们写了4行代码来计算d的值。当程序运行到语句c=b*a时,就按照你所定义的命令执行了计算。然而在符号式编程中,定义计算图和编译程序之间却有着明显的不同。如果我们将刚才的代码以符号式编程的方式重新编写:
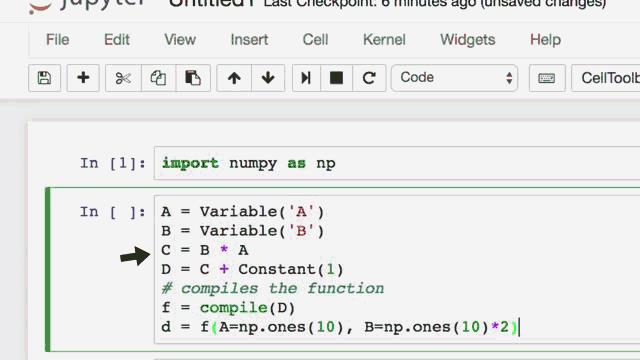
那么当命令C=B*A被执行时,这一行命令实际上并没有被计算,而是生成了一个计算操作或者符号图,然后程序将符号图转为函数。该函数在编译时会被调用,所以计算实际上在代码的最后一步才执行。
符号式编程更为高效,因为可以重用内存中的值进行原地计算,Tensorflow就采用了符号式编程。而命令式编程则更为灵活。Python更适合命令式编程,因此你可以利用Python的这点原生特性,比如输出计算的中间结果,以及将循环注入计算流本身。
2. PyTorch的第二个关键特性是动态计算图
PyTorch的计算图是在运行过程中被定义的,因此在程序运行时系统生成了计算图的结构。Tensorflow的计算图则是先定义后运行,我们先在(计算)图结构中定义条件和迭代,这就好像在运行之前先将完整的程序写好,因此Tensorflow的灵活性更差些。
但是在Tensorflow中我们只定义一次计算图,然后我们可以多次执行该计算图。这样做最大的好处在于我们可以在最开始时就优化好计算图。假设我们想在模型中采用某种策略,以便于将计算图分配到多个机器上,通过复用同一个计算图就可以减少这种计算昂贵的优化。
静态(计算)图在固定结构的神经网络中表现良好,比如前馈网络或者卷积网络。但是在很多情况下,比如使用递归神经网络时,如果计算图结构能基于输入的数据而改变,那将更为有用。在这个代码段中,我们使用Tensorflow在词向量上展开递归神经单元。
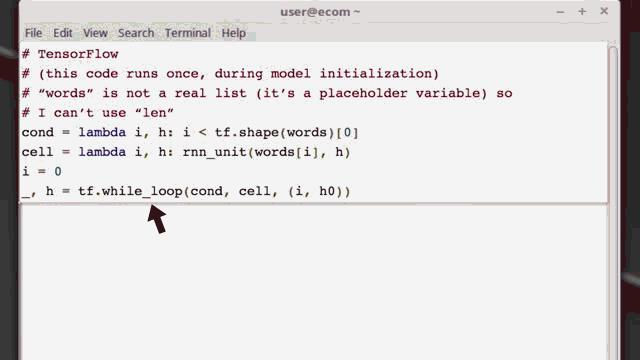
为了实现该操作,我们将需要使用到一个特别的Tensorflow函数while_loop。我们必须使用特殊的节点来表示像循环语句和条件语句这样的基本单元。因为任何的控制流语句只在构建计算图时运行一次,但是一种更简洁的方法是使用动态计算图来代替。
动态计算图可以在运行过程中根据需要进行构造与重构,这种代码更为直接。因为这样我们就可以使用标准的 for 与 if 语句。对于那些工作量不确定的任务,动态计算图将非常有用。而且使用动态计算图使得调试变得非常容易,因为可以直接发现代码中某行出错而不是隐藏在深层次节点中。让我们在PyTorch上构建一个简单的两层神经网络来感受一下。
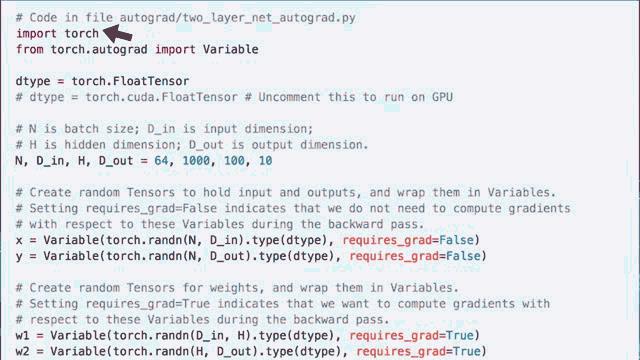
首先引入框架和autograd包,这将使我们的网络自动实现反向传播。然后定义批量大小 输入单元数量 隐藏单元数量和输出单元数量,然后使用这些值来辅助定义张量 用于保持输入和输出,将它们装饰在变量中,将require_grad设置为false,因为在反向传播过程中我们不需要计算这些变量的梯度。
下一组变量将定义我们的权重,将它们初始化为变量 存储着随机的浮点型张量,因为我们想要计算这些变量的梯度,就将标志设置为true。定义一个学习率后我们就可以开始我们的训练循环,迭代次数为500。
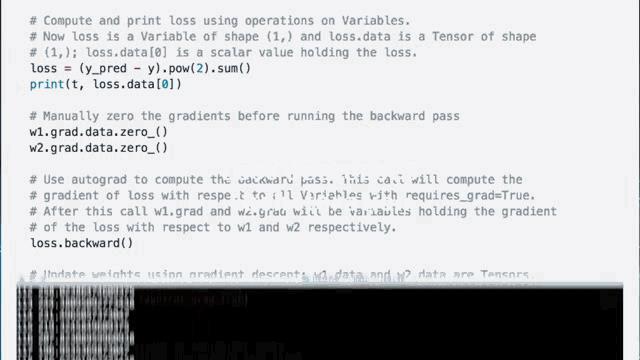
在前向传播的过程中我们可以通过对变量的操作来计算预测标签,mm表示矩阵乘法,clamp则将输入范围内的所有元素限定在最小值和最大值之间。一旦我们将输入值与两组权重进行矩阵乘法运算得到预测值,就可以算出预测值与真实值之间的差异,再求平方。对所有的平方差求和是一种流行的损失函数。
在执行反向传播之前,我们需要手动地将这两组权重的梯度归零。因为梯度缓冲区必须在计算新梯度之前手动重置。然后我们可以通过调用损失的反向函数来完成反向传播计算,它会计算出所有变量的损失梯度。我之前在定义时已经将这部分变量的标志设置为True,然后我们可以通过梯度下降来更新权重。我们的输出看起来很好,非常漂亮!
总之,PyTorch提供了两个非常有用的功能:动态计算图和命令式编程。动态计算图可以在运行时根据需要进行构建和重建,而命令式编程会在运行时就执行计算,定义计算图操作和编译操作之间并没有什么区别。
现在,Tensorflow在网上提供了关于机器学习库的优秀文档,所以它仍然是初学者入门的最佳选择,因为它是以分布式计算为核心构建的,在生产实践中变现优良。但对于研究人员来说PyTorch则具有更加明显的优势。
完整代码和数据集请参考 Github 链接(点击文末阅读原文进入)。
---------------------------------------------
Siraj Raval 何许人也?
Siraj Raval是YouTube极客网红,曾任职于Twilio和Meetup,客户包括Elon Mask和Google,教大家如何使用机器学习开发聊天机器人、无人驾驶车、AI艺术家等视频点击量累计数百万。
Siraj Raval 为什么这么火?
首先,当然是这位哥伦比亚大学高材生活儿好技术好,用自己特有的方式三言两语就能抛出一个原本晦涩的 ML、DL 概念,让听众细细咀嚼。再者,这家伙幽默逗比、口才便给。兴之所至常手舞足蹈,瞳仁奇光掩映,口吐智慧莲华。深度学习讲师不少,但这么风趣可亲的却不多。
延伸阅读:
研习社特供福利 ID:OKweiwu
关注 AI 研习社后,回复【1】获取
雷锋字幕组志愿者
下列同学参与了本文/视频的译制工作!
如果您对我们的工作内容感兴趣,欢迎添加组长微信 “iIoveus2014”加入字幕组~
“TensorFlow & 神经网络算法高级应用班” 要开课啦!
点击图片抵达课程介绍~
以上是关于PyTorch 特辑!网红 5 分钟带你入门 PyTorch的主要内容,如果未能解决你的问题,请参考以下文章