从0到1玩深度学习(0.02):PyTorch简介
Posted 君君玩科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1玩深度学习(0.02):PyTorch简介相关的知识,希望对你有一定的参考价值。
深度学习相比较于之前的数学模型而言更容易上手。大多数研究深度学习的人都是在用那些牛人们创造的模型,只需要换一个不同当应用,再重新调一调参数,就可以开始着重编故事写论文了。就连深度学习玩的非常溜的同事们也自嘲“调得一手好参数,编得一手好故事”。无论如何,深度学习平民化终归是一件好事。

就在这种背景下,pytorch的出现更是加速了深度学习工具包的平民化。虽然研究深度学习对数学理论的要求没那么深,但是深度学习工具包的使用还是让很多久经沙场的程序员们很头疼的。比如一个新手配置一个caffe环境大概需要一个星期到一个月左右的时间,里面需要解决很多层出不穷的bug。虽然谷歌的tensorflow出现之后,这个情况有所缓解,但是tensorflow很难用。具体问题比如tensorflow无法直接把学习过程中的某一层网络特征调出来看,也无法直接使用多个gpu进行训练。当然,国外有一篇文章对tensorflow给出了比较全面而深刻的评价,大家可以移步:https://indico.io/blog/the-good-bad-ugly-of-tensorflow/。
关于深度学习的其它工具包,我会在下一次教程里给出。这里不再细说。在这次教程里,我根据自己的理解,主要借鉴(翻译)了PyTorch的官网上给出的教程,原文在http://pytorch.org/tutorials/。
PyTorch是什么
PyTorch是一款很实用的深度学习工具包,比之前的谷歌推出的TensorFlow,微软推出的CNTK,以及一些其他工具包Caffe,Theano,MatConvNet,MXNet要方便不少。
PyTorch的前身是Torch。Torch这个工具包本身很好用,但是因为它是由一门很小众的编程语言Lua写成,所以大多数人还是选用基于Python语言的TensorFlow。Facebook的深度学习组的大牛们一看,哇,原来Python的受众群这么大,于是放下身段,放弃了高逼格的Lua语言,改用Python语言重新写了一遍Torch工具包,并在很多方面有了明显的改进。于是,在今年年初,工业界和学术界评价最好的深度学习工具包PyTorch诞生了!诞生没多久,使用PyTorch的科学家和工程师们就急速上升,见下图:
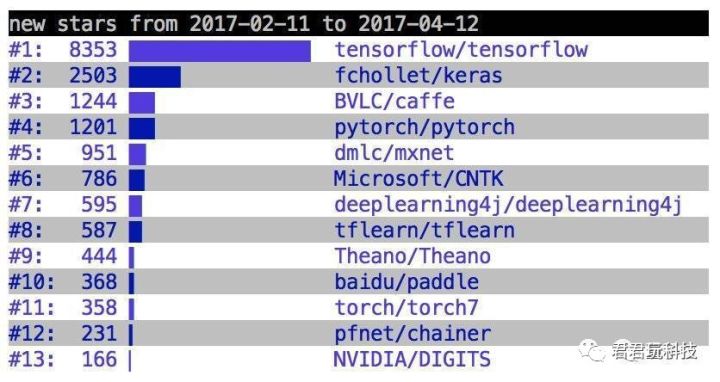
PyTorch出现不到2个月,在github上使用其新成立的项目就多达1201个,迅速上升至第4位。最近的数据我暂时没有找到,等有空专门搜索一下再提供给大家参考。
正如官网上说的,PyTorch有两大特点:可以有效利用GPU(use the power of GPUs)和提供了最大的灵活性和速度(provides maximum flexibility and speed)。
Tensors(张量)
Tensor的中文意思是张量,张量是一种数据结构的通用表现形式。张量是分不同的阶的。一个数字是0阶张量,一个向量是1阶张量,我们常用的矩阵是2阶张量。大家可以通过下图有一个直观的感受:

在PyTorch中,Tensors和numpy中的ndarrays较为相似, 因此Tensor也能够使用GPU来加速运算。
在python界面里,我们可以先引入torch:
from __future__ import print_function
import torch
然后我们可以用Tensor构造一个矩阵,比如
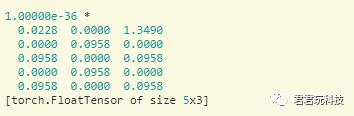
x=torch.Tensor(5,3)
print(x)
输出的是一个5x3的矩阵,没有初始化:
我们也可以用传统的random模式构建随机矩阵:
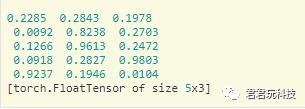
x=torch.rand(5,3)
print(x)
输出的是一个5x3的矩阵,有初始化:
既然我们可以产生任意维度的张量,那么我们就可以在这些量上定义加、减、乘、除等操作,比如最简单的加法:
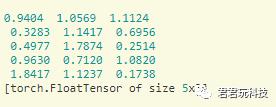
x=torch.rand(5,3)
y=torch.rand(5,3)
print(x+y) 或 print(torch.add(x,y))
我们得到:
如果我们需要把x+y作为一个结果存起来,也很容易:
result=torch.Tensor(5,3)
torch.add(x,y,out=result)
print(result)
得到的结果和上图中的结果一样。
如果只想看矩阵中的某一列,可以用
print(x[:,1])
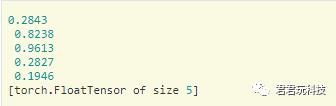
以后我会详细介绍PyTorch中的100多种Tensor操作,对,你没看错,操作有100多种,时刻让你有一种“还有这种操作?!”的错觉!
Troch张量和Numpy数组的互相转换
我们把PyTorch中的张量转变成Python中常用的Numpy数组也是非常容易的事情。
先在torch中定义一个tensor,如
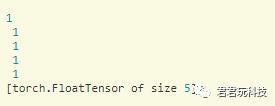
a=torch.ones(5)
print(a)
得到的是
我们把a转成numpy中的数组只需要执行代码:
b=a.numpy()
print(b)
得到的是[1.1.1.1.1.]这样的数组。
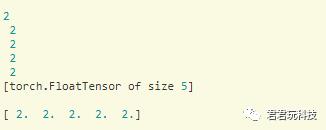
我们改变数组a的值也很容易(b的值也被改变),比如
a.add_(1)
print(a)
print(b)
把numpy数组转成torch中的张量也很简单,只需要torch.from_numpy这个指令:
import numpy as np
a=np.ones(5)
b=torch.from_numpy(a)
np.add(a,1,out=a)
print(a)
print(b)
我们得到
GPU中的Tensor
把数据放在GPU上处理是很有必要的,因为GPU比CPU更适合处理张量数据模式。
如果我们想在GPU上处理数据,只需要在电脑里装上合适版本的CUDA,并用到.cuda函数就可以了。
# let us run this cell only if CUDA is available
if torch.cuda.is_available():
x=x.cuda()
y=y.cuda()
x+y
上面的代码里,我们就把x通过x.cuda()放在了GPU上,并且让x和同样在GPU里的y相加。
本教程代码
本教程的代码可以在这里下载:http://pytorch.org/tutorials/_downloads/tensor_tutorial.py
以上是关于从0到1玩深度学习(0.02):PyTorch简介的主要内容,如果未能解决你的问题,请参考以下文章