开源 | 伯克利AI分布式框架Ray,兼容TensorFlowPyTorch与MXNet
Posted PHP技术大全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源 | 伯克利AI分布式框架Ray,兼容TensorFlowPyTorch与MXNet相关的知识,希望对你有一定的参考价值。
GitHub 链接:https://github.com/ray-project/ray
随着机器学习算法和技术的进步,出现了越来越多需要在多台机器并行计算的机器学习应用。然而,在集群计算设备上运行的机器学习算法目前仍是专门设计的。尽管对于特定的用例而言(如参数服务器或超参数搜索),这些解决方案的效果很好,同时 AI 领域之外也存在一些高质量的分布式系统(如 Hadoop 和 Spark),但前沿开发者们仍然常常需要从头构建自己的系统,这意味着需要耗费大量时间和精力。
例如,应用一个简单概念的算法,如在强化学习中的进化策略(论文《Evolution Strategies as a Scalable Alternative to Reinforcement Learning》)。算法包含数十行伪代码,其中的 Python 实现也并不多。然而,在较大的机器或集群上运行它需要更多的软件工程工作。作者的实现包含了上千行代码,以及必须定义的通信协议、信息序列化、反序列化策略,以及各种数据处理策略。
Ray 的目标之一在于:让开发者可以用一个运行在笔记本电脑上的原型算法,仅需添加数行代码就能轻松转为适合于计算机集群运行的(或单个多核心计算机的)高性能分布式应用。这样的框架需要包含手动优化系统的性能优势,同时又不需要用户关心那些调度、数据传输和硬件错误等问题。
开源的人工智能框架
与深度学习框架的关系:Ray 与 TensorFlow、PyTorch 和 MXNet 等深度学习框架互相兼容,在很多应用上,在 Ray 中使用一个或多个深度学习框架都是非常自然的(例如,UC Berkeley 的强化学习库就用到了很多 TensorFlow 与 PyTorch)。
与其他分布式系统的关系:目前的很多流行分布式系统都不是以构建 AI 应用为目标设计的,缺乏人工智能应用的相应支持与 API,UC Berkeley 的研究人员认为,目前的分布式系统缺乏以下一些特性:
支持毫秒级的任务处理,每秒处理百万级的任务;
嵌套并行(任务内并行化任务,例如超参数搜索内部的并行模拟,见下图);
在运行时动态监测任意任务的依赖性(例如,忽略等待慢速的工作器);
在共享可变的状态下运行任务(例如,神经网络权重或模拟器);
支持异构计算(CPU、GPU 等等)。
一个嵌套并行的简单例子。一个应用运行两个并行实验(每个都是长时间运行任务),每个实验运行一定数量的并行模拟(每一个同时也是一个任务)。
Ray 有两种主要使用方法:通过低级 API 或高级库。高级库是构建在低级 API 之上的。目前它们包括 Ray RLlib,一个可扩展强化学习库;和 Ray.tune,一个高效分布式超参数搜索库。
Ray 的低层 API
开发 Ray API 的目的是让我们能更自然地表达非常普遍的计算模式和应用,而不被限制为固定的模式,就像 MapReduce 那样。
动态任务图
Ray 应用的基础是动态任务图。这和 TensorFlow 中的计算图很不一样。TensorFlow 的计算图用于表征神经网络,在单个应用中执行很多次,而 Ray 的任务图用于表征整个应用,并仅执行一次。任务图对于前台是未知的,随着应用的运行而动态地构建,且一个任务的执行可能创建更多的任务。
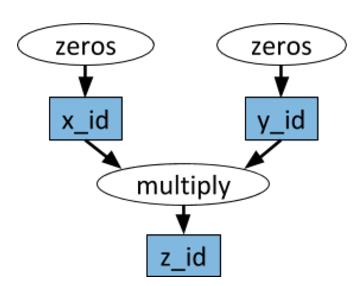
计算图示例。白色椭圆表示任务,蓝色方框表示对象。箭头表示任务依赖于一个对象,或者任务创建了一个对象。
任意的 Python 函数都可以当成任务来执行,并且可以任意地依赖于其它任务的输出。如下示例代码所示:
# Define two remote functions. Invocations of these functions create tasks
# that are executed remotely.
@ray.remote
def multiply(x, y):
return np.dot(x, y)
@ray.remote
def zeros(size):
return np.zeros(size)
# Start two tasks in parallel. These immediately return futures and the
# tasks are executed in the background.
x_id = zeros.remote((100, 100))
y_id = zeros.remote((100, 100))
# Start a third task. This will not be scheduled until the first two
# tasks have completed.
z_id = multiply.remote(x_id, y_id)
# Get the result. This will block until the third task completes.
z = ray.get(z_id)
动作器(Actor)
仅用远程函数和上述的任务所无法完成的一件事是在相同的共享可变状态上执行多个任务。这在很多机器学习场景中都出现过,其中共享状态可能是模拟器的状态、神经网络的权重或其它。Ray 使用 actor 抽象以封装多个任务之间共享的可变状态。以下是关于 Atari 模拟器的虚构示例:
import gym
@ray.remote
class Simulator(object):
def __init__(self):
self.env = gym.make("Pong-v0")
self.env.reset()
def step(self, action):
return self.env.step(action)
# Create a simulator, this will start a remote process that will run
# all methods for this actor.
simulator = Simulator.remote()
observations = []
for _ in range(4):
# Take action 0 in the simulator. This call does not block and
# it returns a future.
observations.append(simulator.step.remote(0))
Actor 可以很灵活地应用。例如,actor 可以封装模拟器或神经网络策略,并且可以用于分布式训练(作为参数服务器),或者在实际应用中提供策略。
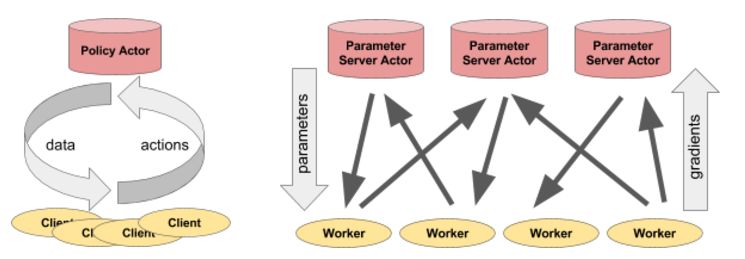
图左:actor 为客户端进程提供预测/操作。图右:多个参数服务器 actor 使用多个工作进程执行分布式训练。
参数服务器示例
一个参数服务器可以作为一个 Ray actor 按如下代码实现:
@ray.remote
class ParameterServer(object):
def __init__(self, keys, values):
# These values will be mutated, so we must create a local copy.
values = [value.copy() for value in values]
self.parameters = dict(zip(keys, values))
def get(self, keys):
return [self.parameters[key] for key in keys]
def update(self, keys, values):
# This update function adds to the existing values, but the update
# function can be defined arbitrarily.
for key, value in zip(keys, values):
self.parameters[key] += value
这里有更完整的示例:http://ray.readthedocs.io/en/latest/example-parameter-server.html
执行以下代码初始化参数服务器:
parameter_server = ParameterServer.remote(initial_keys, initial_values)
执行以下代码,创建 4 个长时间运行的持续恢复和更新参数的工作进程:
@ray.remote
def worker_task(parameter_server):
while True:
keys = ['key1', 'key2', 'key3']
# Get the latest parameters.
values = ray.get(parameter_server.get.remote(keys))
# Compute some parameter updates.
updates = …
# Update the parameters.
parameter_server.update.remote(keys, updates)
# Start 4 long-running tasks.
for _ in range(4):
worker_task.remote(parameter_server)
Ray 高级库
Ray RLib 是一个可扩展的强化学习库,其建立的目的是在多个机器上运行,可以通过示例训练脚本或者 Python API 进行使用。目前它已有的实现为:
A3C
DQN
Evolution Strategies
PPO
UC Berkeley 的开发者在未来将继续添加更多的算法。同时,RLib 和 OpenAI gym 是完全兼容的。
Ray.tune 是一个高效的分布式超参数搜索库。它提供了一个 Python API 以执行深度学习、强化学习和其它计算密集型任务。以下是一个虚构示例的代码:
from ray.tune import register_trainable, grid_search, run_experiments
# The function to optimize. The hyperparameters are in the config
# argument.
def my_func(config, reporter):
import time, numpy as np
i = 0
while True:
reporter(timesteps_total=i, mean_accuracy=(i ** config['alpha']))
i += config['beta']
time.sleep(0.01)
register_trainable('my_func', my_func)
run_experiments({
'my_experiment': {
'run': 'my_func',
'resources': {'cpu': 1, 'gpu': 0},
'stop': {'mean_accuracy': 100},
'config': {
'alpha': grid_search([0.2, 0.4, 0.6]),
'beta': grid_search([1, 2]),
},
}
})
可以使用 TensorBoard 和 rllab's VisKit 等工具对运行状态的结果进行实时可视化(或者直接阅读 JSON 日志)。Ray.tune 支持网格搜索、随机搜索和更复杂的早停算法,如 HyperBand。
更多分享,敬请关注
精彩不落幕Q群:374155314
本文来源网络,侵立删!
以上是关于开源 | 伯克利AI分布式框架Ray,兼容TensorFlowPyTorch与MXNet的主要内容,如果未能解决你的问题,请参考以下文章
重磅!字节跳动开源高性能分布式训练框架BytePS:兼容TensorFlowPyTorch等
伯克利开源 Confluo:吞吐量比 Kafka 高 4 到 10 倍!
MLSQL:融合 Spark+Ray,让企业低成本落地 Data+AI
MLSQL:融合 Spark+Ray,让企业低成本落地 Data+AI