深度学习实战pytorch中如何处理RNN输入变长序列padding
Posted 机器学习算法与自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习实战pytorch中如何处理RNN输入变长序列padding相关的知识,希望对你有一定的参考价值。
1为什么RNN需要处理变长输入
假设我们有情感分析的例子,对每句话进行一个感情级别的分类,主体流程大概是下图所示:
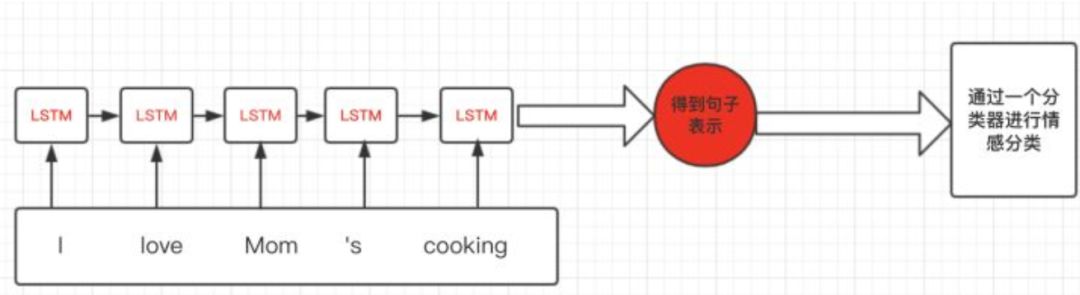
思路比较简单,但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding,将短句子padding为跟最长的句子一样。
比如向下图这样:
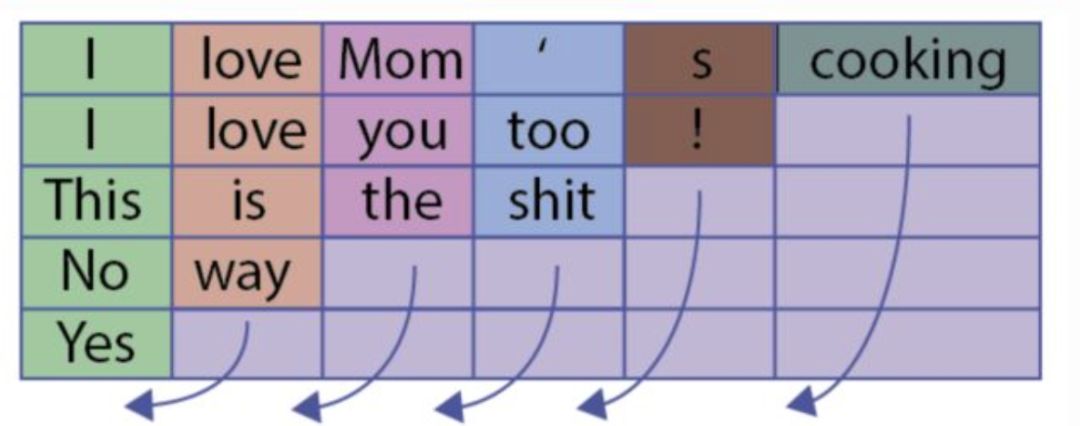
但是这会有一个问题,什么问题呢?比如上图,句子“Yes”只有一个单词,但是padding了5的pad符号,这样会导致LSTM对它的表示通过了非常多无用的字符,这样得到的句子表示就会有误差,更直观的如下图:
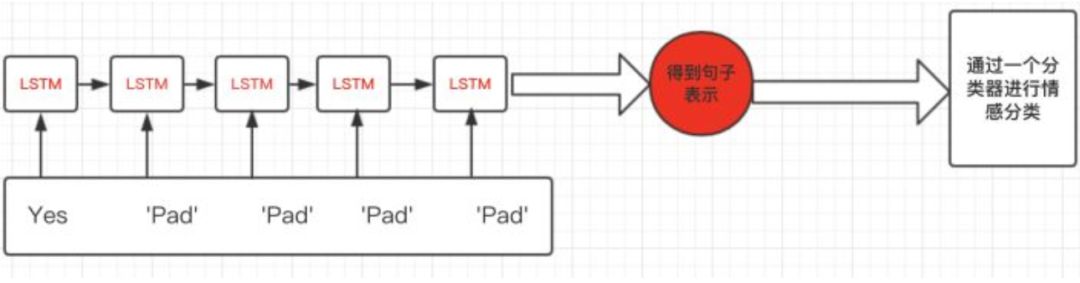
那么我们正确的做法应该是怎么样呢?
这就引出pytorch中RNN需要处理变长输入的需求了。在上面这个例子,我们想要得到的表示仅仅是LSTM过完单词"Yes"之后的表示,而不是通过了多个无用的“Pad”得到的表示:如下图:
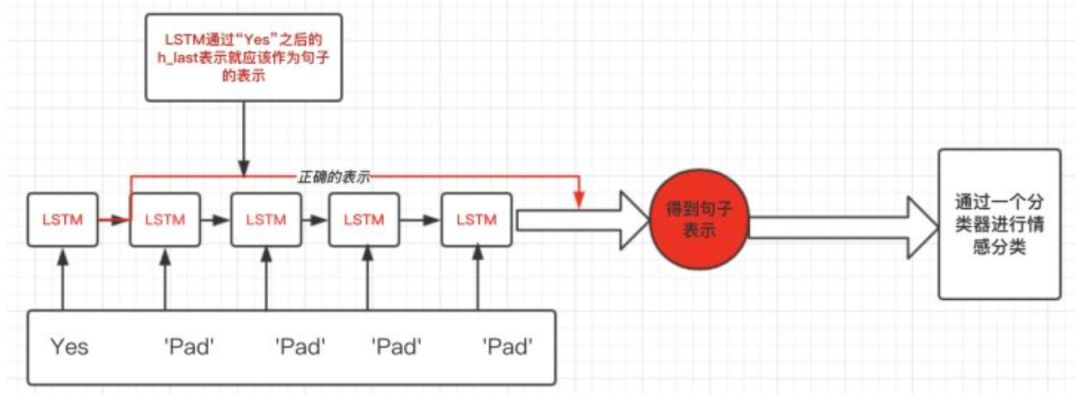
2pytorch中RNN如何处理变长padding
主要是用函数torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来进行的,分别来看看这两个函数的用法。
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后(特别注意需要进行排序)。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
参数说明:
input (Variable) – 变长序列 被填充后的 batch
lengths (list[int]) – Variable 中 每个序列的长度。(知道了每个序列的长度,才能知道每个序列处理到多长停止)
batch_first (bool, optional) – 如果是True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。一个PackedSequence表示如下所示:
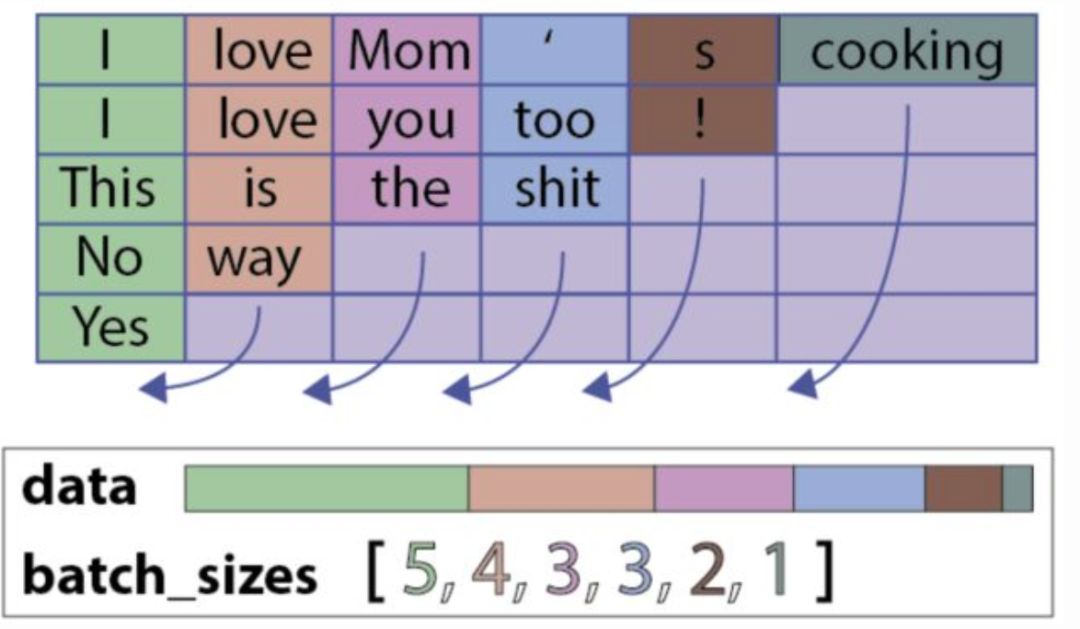
具体代码如下:
embed_input_x_packed = pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True)
encoder_outputs_packed, (h_last, c_last) = self.lstm(embed_input_x_packed)
此时,返回的h_last和c_last就是剔除padding字符后的hidden state和cell state,都是Variable类型的。代表的意思如下(各个句子的表示,lstm只会作用到它实际长度的句子,而不是通过无用的padding字符,下图用红色的打钩来表示):
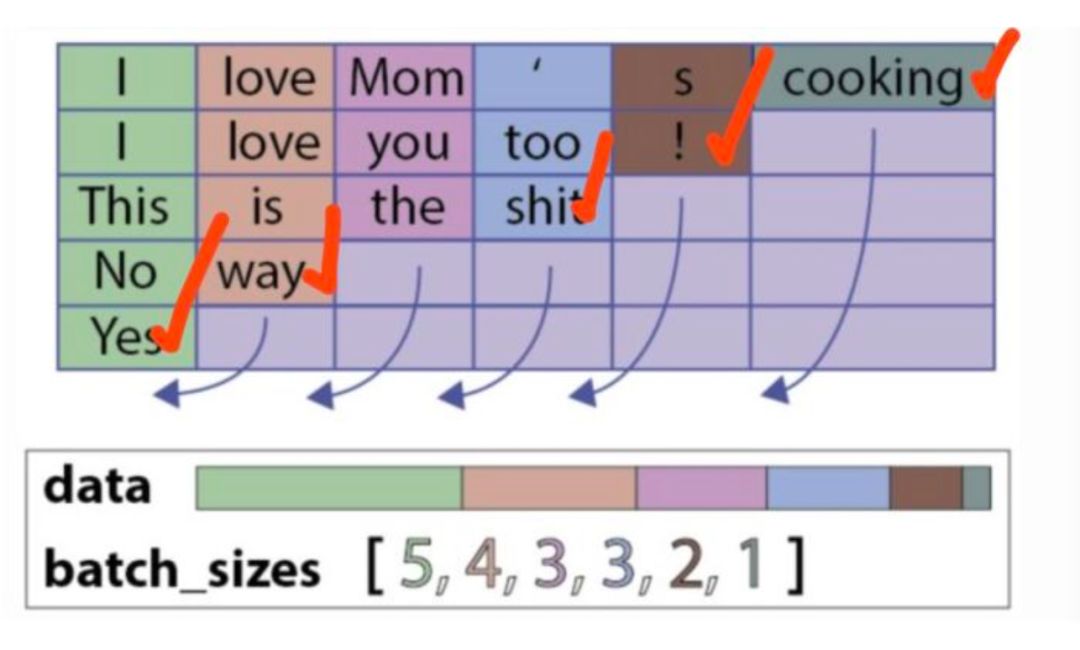
但是返回的output是PackedSequence类型的,可以使用:
encoder_outputs, _ = pad_packed_sequence(encoder_outputs_packed, batch_first=True)
将encoderoutputs在转换为Variable类型,得到的_代表各个句子的长度。
3总结
这样综上所述,RNN在处理类似变长的句子序列的时候,我们就可以配套使用torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来避免padding对句子表示的影响
参考:
pytorch对可变长度序列的处理 - 深度学习1 - 博客园赵普:
pytorch RNN 变长输入 padding,知乎
推荐阅读:
以上是关于深度学习实战pytorch中如何处理RNN输入变长序列padding的主要内容,如果未能解决你的问题,请参考以下文章