PyTorch 重磅更新,不只是支持 Windows
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 重磅更新,不只是支持 Windows相关的知识,希望对你有一定的参考价值。
翻译 | 林椿眄
这次版本的主要更新一些性能的优化,包括权衡内存计算,提供 Windows 支持,24个基础分布,变量及数据类型,零维张量,张量变量合并,支持 CuDNN 7.1,加快分布式计算等,并修复部分重要 bug等。
▌目录
主要变化
张量/变量合并
零维张量
数据类型
版本迁移指南
新特性
张量
高级的索引功能
快速傅里叶变换
神经网络
权衡内存计算
瓶颈—用于识别代码热点的工具
torch中的分布
24个基础的概率分布
添加 cdf,variance,entropy,perplexity 等方法
分布式计算
便捷使用的Launcher utility
NCCL2 后端
C++ 拓展
Window 支持
改善 ONNX 性能
RNN 支持
性能改善
Bug 修复
▌主要变化
以下我们将为Pytorch用户总结一些频繁使用到的最重要的核心功能。
主要变化及潜在的突破性变化
Tensors/Variables 合并
零维 Tensors 的一些操作
弃用Volatile 标志
性能改善
添加了 dtypes、devices及numpy风格的 tensor 创建函数
支持编写一些不依赖设备的代码
我们编写了一个版本迁移指南,帮助你将代码转换为新版本的 APIs和风格。如果你想要迁移先前版本的 PyTorch代码,请阅读迁移指南。此外,本部分的内容(包括主要核心变化)都包含在迁移指南中。
Tensor 和Variable 类合并
新版本中,torch.autograd.Variable和torch.Tensor将同属一类。更确切地说,torch.Tensor 能够跟踪历史并像旧版本的 Variable 那样运行; Variable 封装仍旧可以像以前一样工作,但返回的对象类型是 torch.Tensor。 这意味着你不再需要代码中的所有变量封装器。
Tensor 的type () 变化
这里需要注意到张量的 type()不再反映数据类型,而是改用 isinstance()或 x.type()来表示数据类型,代码如下:
>>> x = torch.DoubleTensor([1, 1, 1])
>>> print(type(x)) # was torch.DoubleTensor
<class 'torch.autograd.variable.Variable'>
>>> print(x.type()) # OK: 'torch.DoubleTensor'
'torch.DoubleTensor'
>>> print(isinstance(x, torch.DoubleTensor)) # OK: True
True
autograd 用于跟踪历史记录
作为 autograd方法的核心标志,requires_grad现在是 Tensors 类的一个属性。 让我们看看这个变化是如何体现在代码中的。Autograd的使用方法与先前用于 Variable 的规则相同。当操作中任意输入 Tensor的require_grad = True时,它开始跟踪历史记录。代码如下所示,
>>> x = torch.ones(1) # create a tensor with requires_grad=False (default)
>>> x.requires_grad
False
>>> y = torch.ones(1) # another tensor with requires_grad=False
>>> z = x + y
>>> # both inputs have requires_grad=False. so does the output
>>> z.requires_grad
False
>>> # then autograd won't track this computation. let's verify!
>>> z.backward()
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
>>>
>>> # now create a tensor with requires_grad=True
>>> w = torch.ones(1, requires_grad=True)
>>> w.requires_grad
True
>>> # add to the previous result that has require_grad=False
>>> total = w + z
>>> # the total sum now requires grad!
>>> total.requires_grad
True
>>> # autograd can compute the gradients as well
>>> total.backward()
>>> w.grad
tensor([ 1.])
>>> # and no computation is wasted to compute gradients for x, y and z, which don't require grad
>>> z.grad == x.grad == y.grad == None
True
requires_grad 操作
除了直接设置属性之外,你还可以使用 my_tensor.requires_grad_(requires_grad = True)在原地更改此标志,或者如上例所示,在创建时将其作为参数传递(默认为 False)来实现,代码如下:
>>> existing_tensor.requires_grad_()
>>> existing_tensor.requires_grad
True
>>> my_tensor = torch.zeros(3, 4, requires_grad=True)
>>> my_tensor.requires_grad
True
关于 .data
.data 是从 Variable中获取底层 Tensor 的主要方式。 合并后,调用 y = x.data仍然具有相似的语义。因此 y将是一个与 x共享相同数据的 Tensor,并且 requires_grad = False,它与 x的计算历史无关。
然而,在某些情况下 .data 可能不安全。 对 x.data 的任何更改都不会被 autograd 跟踪,如果在反向过程中需要 x,那么计算出的梯度将不正确。另一种更安全的方法是使用 x.detach(),它将返回一个与 requires_grad = False 时共享数据的 Tensor,但如果在反向过程中需要 x,那么 autograd 将会就地更改它。
零维张量的一些操作
先前版本中,Tensor矢量(1维张量)的索引将返回一个Python数字,但一个Variable矢量的索引将返回一个大小为(1,)的矢量。同样地, reduce函数存在类似的操作,即tensor.sum()会返回一个Python数字,但是variable.sum()会调用一个大小为(1,)的向量。
幸运的是,新版本的PyTorch中引入了适当的标量(0维张量)支持! 可以使用新版本中的torch.tensor函数来创建标量(这将在后面更详细地解释,现在只需将它认为是PyTorch中numpy.array的等效项)。现在你可以做这样的事情,代码如下:
>>> torch.tensor(3.1416) # create a scalar directly
tensor(3.1416)
>>> torch.tensor(3.1416).size() # scalar is 0-dimensional
torch.Size([])
>>> torch.tensor([3]).size() # compare to a vector of size 1
torch.Size([1])
>>>
>>> vector = torch.arange(2, 6) # this is a vector
>>> vector
tensor([ 2., 3., 4., 5.])
>>> vector.size()
torch.Size([4])
>>> vector[3] # indexing into a vector gives a scalar
tensor(5.)
>>> vector[3].item() # .item() gives the value as a Python number
5.0
>>> sum = torch.tensor([2, 3]).sum()
>>> sum
tensor(5)
>>> sum.size()
torch.Size([])
累计损失函数
考虑在 PyTorch0.4.0 版本之前广泛使用的 total_loss + = loss.data[0] 模式。Loss 是一个包含张量(1,)的Variable,但是在新发布的0.4.0版本中,loss 是一个0维标量。 对于标量的索引是没有意义的(目前的版本会给出一个警告,但在0.5.0中将会报错一个硬错误):使用 loss.item()从标量中获取 Python 数字。
还值得注意得是,如果你在累积损失时未能将其转换为 Python 数字,那么程序中的内存使用量可能会增加。这是因为上面表达式的右侧,在先前版本中是一个Python 浮点型数字,而现在它是一个零维的张量。 因此,总损失将会累积了张量及其历史梯度,这可能会需要更多的时间来自动求解梯度值。
弃用volatile标志
新版本中,volatile 标志将被弃用且不再会有任何作用。先前的版本中,任何涉及到 volatile = True 的 Variable 的计算都不会由 autograd 追踪到。这已经被一组更灵活的上下文管理器所取代,包括 torch.no_grad(),torch.set_grad_enabled(grad_mode)等等。代码如下:
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad():
... y = x * 2
>>> y.requires_grad
False
>>>
>>> is_train = False
>>> with torch.set_grad_enabled(is_train):
... y = x * 2
>>> y.requires_grad
False
>>> torch.set_grad_enabled(True) # this can also be used as a function
>>> y = x * 2
>>> y.requires_grad
True
>>> torch.set_grad_enabled(False)
>>> y = x * 2
>>> y.requires_grad
False
dtypes、devices 及数组风格的新函数
在先前版本的 PyTorch 中,我们通常需要指定数据类型(例如float vs double),设备类型(cpu vs cuda)和布局(dense vs sparse)作为“张量类型”。例如,torch.cuda.sparse.DoubleTensor是 Tensor 类的 double 数据类型,用在 CUDA 设备上,并具有 COO 稀疏张量布局。
在新版本中,我们将引入 torch.dtype,torch.device 和 torch.layout 类,以便通过 NumPy 风格的创建函数来更好地管理这些属性。
torch.dtype
以下给出可用的 torch.dtypes(数据类型)及其相应张量类型的完整列表。
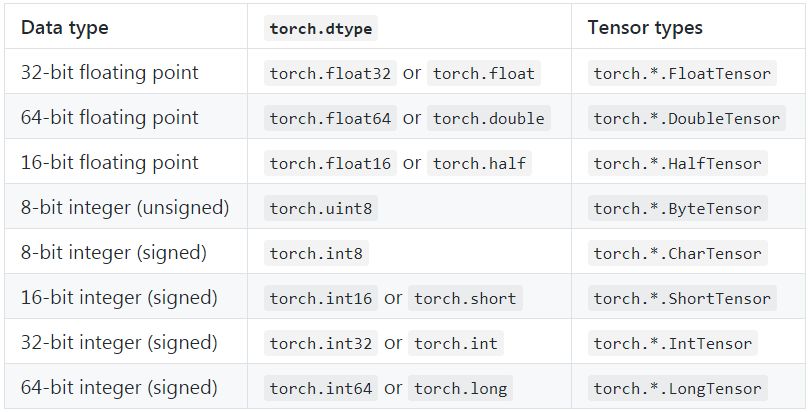
使用 torch.set_default_dtype 和 torch.get_default_dtype来操作浮点张量的默认 dtype。
torch.device
torch.device 包含设备类型('cpu'或'cuda')及可选的设备序号(id)。它可以通过 torch.device('{device_type}')或 torch.device('{device_type}:{device_ordinal}')来初始化所选设备。
如果设备序号不存在,则用当前设备表示设备类型; 例如,torch.device('cuda')等同于 torch.device('cuda:X'),其中 x 是 torch.cuda.current_device()的结果。
torch.layout
torch.layout 表示张量的数据布局。新版本中,torch.strided(密集张量)和torch.sparse_coo(带有 COO 格式的稀疏张量)均受支持。
创建张量
新版本中,创建 Tensor 的方法还可以使用 dtype,device,layout 和 requires_grad选项在返回的 Tensor 中指定所需的属性。代码如下:
>>> device = torch.device("cuda:1")
>>> x = torch.randn(3, 3, dtype=torch.float64, device=device)
tensor([[-0.6344, 0.8562, -1.2758],
[ 0.8414, 1.7962, 1.0589],
[-0.1369, -1.0462, -0.4373]], dtype=torch.float64, device='cuda:1')
>>> x.requires_grad # default is False
False
>>> x = torch.zeros(3, requires_grad=True)
>>> x.requires_grad
True
torch.tensor
torch.tensor 是新添加的张量创建方法之一。它像所有类型的数据一样排列,并将包含值复制到一个新的 Tensor 中。如前所述,PyTorch 中的 torch.tensor等价于 NumPy 中的构造函数 numpy.array。与 torch.*tensor 方法不同的是,你也可以通过这种方式(单个 python 数字在 torch.*tensor 方法中被视为大小)创建零维张量(也称为标量)。此外,如果没有给出 dtype 参数,它会根据给定的数据推断出合适的 dtype。这是从现有数据(如 Python 列表)创建张量的推荐方法。代码如下:
>>> cuda = torch.device("cuda")
>>> torch.tensor([[1], [2], [3]], dtype=torch.half, device=cuda)
tensor([[ 1],
[ 2],
[ 3]], device='cuda:0')
>>> torch.tensor(1) # scalar
tensor(1)
>>> torch.tensor([1, 2.3]).dtype # type inferece
torch.float32
>>> torch.tensor([1, 2]).dtype # type inferece
torch.int64
我们还添加了更多的张量创建方法。其中包括一些有torch.*_like或tensor.new_ *变体。
1. torch.*_like 输入一个 tensor 而不是形状。除非另有说明,它默认将返回一个与输入张量相同属性的张量。代码如下:
>>> x = torch.randn(3, dtype=torch.float64)
>>> torch.zeros_like(x)
tensor([ 0., 0., 0.], dtype=torch.float64)
>>> torch.zeros_like(x, dtype=torch.int)
tensor([ 0, 0, 0], dtype=torch.int32)
2. tensor.new_ * 也可以创建与 tensor 具有相同属性的 tensor,但它需要指定一个形状参数:
>>> x = torch.randn(3, dtype=torch.float64)
>>> x.new_ones(2)
tensor([ 1., 1.], dtype=torch.float64)
>>> x.new_ones(4, dtype=torch.int)
tensor([ 1, 1, 1, 1], dtype=torch.int32)
要得到所需的形状,在大多数情况下你可以使用元组(例如 torch.zeros((2,3)))或可变参数(例如 torch.zeros(2,3))来指定。
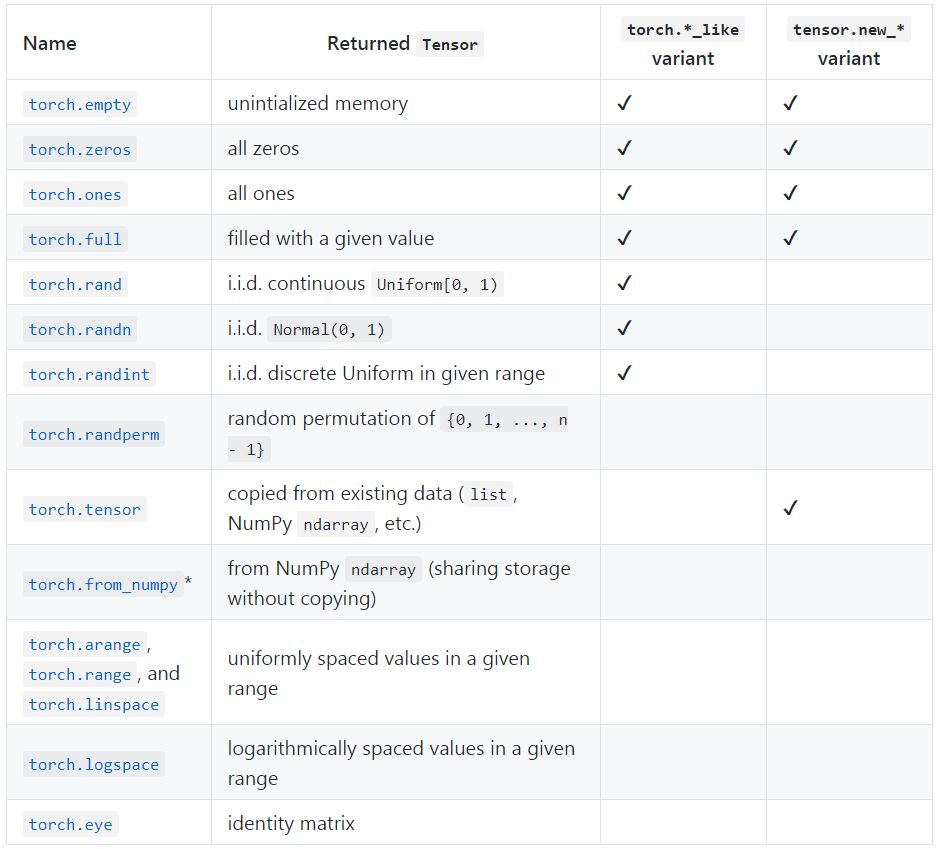
其中 *:torch.from_numpy 只接受一个 NumPy ndarray 类型作为其输入参数。
编写一些与设备无关的代码
先前版本的 PyTorch 很难编写一些设备不可知或不依赖设备的代码(例如,可以在没有修改的情况下,在CUDA环境下和仅CPU环境的计算机上运行)。
在新版本PyTorch 0.4.0中,你通过一下两种方式让这一过程变得更容易:
张量的device属性将为所有张量提供torch.device属性(get_device仅适用于CUDA张量)
Tensors和Modules的to方法可用于将对象轻松移动到不同的设备(而不必根据上下文信息调用cpu()或cuda())
我们推荐用以下的模式:
# at beginning of the script
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
...
# then whenever you get a new Tensor or Module
# this won't copy if they are already on the desired device
input = data.to(device)
model = MyModule(...).to(device)
▌张量
支持高级的索引方式
新版本的 PyTorch 将完全支持高级索引,遵循 numpy 的高级索引规则。现在你可以使用以下示例:
a = torch.rand(10, 10, 10, 10)
# the indexing elements can have other shapes than 1
b = a[[[3, 2]], :, [[1, 3]]]
# broadcasting also supported in the indices, as well as lists,
# negative indices, slices, elipses, numbers
c = a[[1, -2], 2:4, :, [1]]
# can also support tensors as indices
index = torch.tensor([2, 4])
d = a[index]
# and the indices can be on the GPU
# or CPU
e = a[index.cuda()]
f = a.cuda()[index]
mask = torch.rand(10) > 0.5
# we can now index with a mask that has fewer
# dimensions than the indexing tensor
c = a[mask, :5]
快速傅里叶变换
添加新的 FFT 方法#5856
添加 torch.stft(短时傅立叶变换)和 hann / hamming / Bartlett 窗函数。#4095
在 * FFT#6528 中支持任意数量的批次维度
已更新的 torch 新功能和操作
增加了 torch.log2 和 torch.log10#6272
增加了 torch.isnan#5273
添加 torch.reshape,这与 numpy.reshape 的功能类似。它大致相当于 tensor.contiguous().view(),但在某些情况下避免了复制#5575
添加 torch.unique 的 CPU 实现,它输出张量中的独特元素#5503
a = torch.arange(0, 9).reshape(3, 3)
# the following transposes a
b = torch.einsum('ij->ji', (a,))
添加 torch.det,torch.logdet 和 torch.slogdet,用于计算平方 2D 张量的对数行列式。对于负的行列式,torch.logdet 返回 nan,而 torch.slogdet返回的是对数行列式的符号和行列式绝对值的对数。#3816和#5393
添加 nn.functional.gumbel_softmax,它允许你对离散变量使用重参数化技巧#3341
添加 torch.take 和 Tensor.put_。这些函数相当于 numpy.take和 numpy.put,并且是基础 PyTorch 中高级索引的功能#3263
添加 torch.randint,类似于 numpy.random.randint#6136
添加 torch.diagonal 和 torch.diagflat,类似于 numpy.diagonal和numpy.diagflat。它们作为 torch.diag 的替代品,用于处理构造对角张量以及提取矩阵对角线等问题#5622
添加 torch.einsum,相当于 numpy.einsum。允许你使用einsum符号来执行相关操作,代码如下。#5503
添加 torch.expm1。对于小数值的x来说,它将返回一个数值稳定的 exp(x)-1。#4350
允许用户使用 torch.split 来指定所要单独分割的尺寸#3837
添加 torch.where(condition,tensor1,tensor2),根据条件返回从 tensor1或 tensor2中选择的元素的张量。#4259,#4259
为稀疏张量添加 Tensor.norm(dim)。#4882
针对所有类型使用 torch.neg。#4075
为 torch.trtrs 实现梯度计算。#3972
弃用不适当的 Tensor.resize 和 Tensor.resize_as。这些方法有奇怪的语义,且很难被正确使用。请使用它们的原位变体 Tensor.resize_和 Tensor.resize_as_。#4886
将 .cuda()中的 async 参数重命名为 non_blocking
新版本的 PyTorch 中,转换调用中所需的 async 关键字参数已被弃用,并且被non_blocking所替代。这是必要的,因为 async 将成为 Python3.7中的关键字。
▌神经网络
一个新的 autograd 容器(用于权衡计算内存)
新的 checkpoint 容器允许你存储反向传播过程所需输出的子集。如果缺少输出(为了节省内存),checkpoint 容器将重新计算来自最近检查点的中间输出,以便减少内存使用量(随着计算时间的增加)。以下是一个例子:
# input
input = torch.rand(1, 10)
# suppose we have a very deep model
layers = [nn.Linear(10, 10) for _ in range(1000)]
model = nn.Sequential(*layers)
output = model(input)
上面实例中的模型使用了大量的内存,因为它需要保留反向传播中每个操作的中间值。而 checkpoint 容器可以让你减少内存需求:
# create the input tensors and set the requires_grad=True
# NOTE: the requires_grad=True for the input is a current
# limitation of checkpointing. At least one of the
# model inputs should have requires_grad=True.
# If you don't do it, you might have empty gradients.
input = torch.rand(1, 10, requires_grad=True)
layers = [nn.Linear(10, 10) for _ in range(1000)]
# define function that will define where
# we will checkpoint and store
# intermediate gradients. In this case,
# we will only store one intermediate
# gradient, in the middle of the
# model
def run_first_half(*args):
x = args[0]
for layer in layers[:500]:
x = layer(x)
return x
def run_second_half(*args):
x = args[0]
for layer in layers[500:-1]:
x = layer(x)
return x
# now uses the new checkpoint functionality
from torch.utils.checkpoint import checkpoint
x = checkpoint(run_first_half, input)
x = checkpoint(run_second_half, x)
# last output need to be run without checkpoint
x = layers[-1](x)
x.sum.backward() # works!
对于序列模块(其内部可以具有任意块),提供了辅助函数 checkpoint_sequential,该函数负责处理最常见的用例,代码如下:
input = torch.rand(1, 10, requires_grad=True)
layers = [nn.Linear(10, 10) for _ in range(1000)]
model = nn.Sequential(*layers)
from torch.utils.checkpoint import checkpoint_sequential
# split in two blocks
num_segments = 2
x = checkpoint_sequential(model, num_segments, input)
x.sum().backward() # works!
瓶颈——用于识别代码热点的工具
torch.utils.bottleneck(#5216,#6425)是一个工具,可以用作初始步骤调试程序中的瓶颈。它总结了 Python 分析器和 PyTorch的 autograd 分析器的脚本运行。有关更多详细信息,请参阅瓶颈文档。
reduce=False Losses
在新版本中,所有的损失函数都将支持 reduce 关键字。指定 reduce= False,将返回单位损失的张量,而不是单个减少的损失。#4924,#5346,#5646,#4231,#4705,#5680
模块及其改进
添加 DistributedDataParallelCPU 模块。这与 DistributedDataParallel模块类似,但它更特别支持在 CPU 上运行的模型(这与 DistributedDataParallel模块相反,它更支持 GPU),同时它还支持 mpi,gloo 和 tcp 后端。#5919
添加 Group Normalization 模块(nn.GroupNorm),作为批量标准化的替代方案,这个模块在处理小批量数据时,不会遇到与 BatchNorm模块相同的问题
添加 Layer Normalization 模块(nn.LayerNorm),这是NLP任务中经常用来替代批量标准化的方法。#4922
添加 Local Response Normalization 模块(nn.LocalResponseNorm)。#4922
新版本中,MaxPool3d 模块能够支持双反向功能。同时,MaxPool3d 和 MaxUnpool3d将使用与其他池化方法相一致的索引。#5328
所有损失函数现在都支持用一个 reduce 参数来返回批损失值。#264
将 util 添加到 torch.nn.utils.clip_grad 中的剪辑梯度值,并在 torch.nn.init中将 param 添加到 He 初始化方案中。#6173
将 torch.nn.init.* 方法更名,并最终以下划线结尾的形式,并且弃用旧版本的命名形式,二者的功能没有太大变化 # 6093
在 DataParallel 方法中增加了对返回字典形式的支持#6113
在 torch.nn.Bilinear 方法中增加了对 N-D 张量的支持#5764
添加 Embedding.from_pretrained 模块。这允许使用现有的张量来初始化嵌入层,并绕过它的权重值来随机初始化。
新版本中,你现在可以分别使用 nn.Sequential,nn.ModuleLis t和 nn.ParameterList模块#4491
新版本中,你可以注册 nn.Module 模块的整型参数和缓冲区,它将不再受 module.float(),module.double()及 module.half()调用的影响。#3820
▌torch 中的分布
新版本中,torch.distributions 已扩展到包括24个基本概率分布:伯努利,Beta,二项式,分类,Cauchy,Chi2,Dirichlet,指数,FisherSnedecor,Gamma,几何,Gumbel,拉普拉斯,LogNormal,多项式,多元正态,Normal,OneHotCategorical,Pareto,Poisson,RelaxedBernoulli,RelaxedOneHotCategorical,StudentT和Uniform分布等。
新版本中,Distribution 接口也已扩展为包含许多方法:.cdf(),.icdf(),.mean(),.variance(),.entropy()和 .perplexity()。此外,Distributions 还能将张量维度分解为 sample_shape+ batch_shape + event_shape 的模式。现在,大多数连续分布还能实现了一个自微分过程,如在保证 .has_rsample方法可用性的前提下,你可以使用 .rsample()方法来计算逐路径的导数值,这也称重参数化技巧,代码如下:
>>> loc = torch.tensor(0., requires_grad=True)
>>> scale = torch.tensor(1., requires_grad=True)
>>> samples = Normal(loc, scale).rsample(sample_shape=(1000,))
>>> loss = (samples - 0.5).pow(4).mean() # average over 1000 monte carlo samples
>>> grad(loss, [loc, scale])
(tensor(-7.5092), tensor(15.2704))
大多数离散分布的实现都依赖于 .enumerate_support()方法,在保证 .has_enumerate_support方法可用性的前提下,你可以通过这个方法轻松地汇总所有可能的样本值。
kl_divergence 是为许多分布对定义的,例如:
>>> x = torch.tensor(1.0, requires_grad=True)
>>> kl = kl_divergence(Uniform(-x, x), Normal(0., 1.))
>>> grad(kl, [x])[0]
tensor(-0.6667)
分布变换
通过将 TransformedDistribution 与 torch.distributions.transforms库中的任意数量的 Transform 对象进行组合,来创建新的分布,这包括:ExpTransform,PowerTransform,SigmoidTransform,AbsTransform,AffineTransform,SoftmaxTransform,StickBreakingTransform,LowerCholeskyTransform 以及通过 .inv 属性设置的分布倒数。
分布约束
分布将提供有关它们的支持 .support 及它们的参数约束 .arg_constraints 的元数据。这些 Constraint 对象使用 transform_to()和 biject_to()进行转换注册。 通过约束和转换,可以很容易地以通用的方式指定新的分布,代码如下:
>>> scale = torch.tensor(1., requires_grad=True)
>>> p = Normal(0., scale)
>>> assert p.arg_constraints['scale'] == constraints.positive
>>> prior = TransformedDistribution(Normal(0., 1.),
... transform_to(constraints.positive))
torch.distributions.constraints 库中的约束包括:boolean,greater_than(lower_bound),integer_interval(lower_bound,upper_bound),interval(lower_bound,upper_bound),lower_cholesky,lower_triangular,nonnegative_integer,positive,positive_definite,positive_integer,real,real_vector 和 unit_interval。
▌分布式
启动分布式训练的实用帮助程序
新版本中,我们添加了一个实用程序功能来帮助启动分布式设置下的工作。利用 DistributedDataParallel的脚本,可以启动单节点或多节点程序,我们可以按如下方法使用 torch.distributed launch
python -m torch.distributed.launch my_script.py --arg1 --arg2 --arg3
该脚本简化了 distributed 软件包的日常可用性。
你还可以通过以下链接阅读它的详细用法:
http://pytorch.org/docs/stable/distributed.html#launch-utility
基于 NCCL 2.0 的新分布式后端
新版本的 PyTorch中添加了一个新的分布式后端,它可以利用 NCCL 2.0 获得最高运行速度。它还为多个GPU上的集群操作提供了新的API。
你可以通过如下代码启用新的后端:
torch.distributed.init_process_group("nccl")
其他的分布式更新
合并很多小广播以提高性能#4978
为分布式训练添加混合精度的功能支持#4891
发布 NCCL 分布式后端。在先前的版本中它只是作为实验品#4921
为 Gloo 数据通道启用 Infiniband 支持,并自动检测 IB 设备#4795
▌C++拓展
先前的版本中,使用 C 或 CUDA 为用户编写自定义的扩展模块的一种官方方式是通过 cffi 扩展模块。这种方法的缺点是它需要一个单独的步骤来编译CUDA 内核,这可能有点麻烦。
在新版本中,PyTorch 提供了一个更好的系统来编写自己的 C++/CUDA 扩展。使用这种新扩展支持的示例实现可以在 pytorch/cpp_extensions 仓库中找到。
在此,我们提供两种编译模式:
提前编译:使用新的 CppExtension 或 CUDAExtension 模块编写 setup.py 脚本,这是 setuptools.Extension 模块的扩展;
实时编译:将需要编译的 C++/CUDA 文件列表传递给 torch.utils.cpp_extension.load,它将进行实时编译并为你缓存这些库。以下示例讲说明了实现这种扩展的容易程度:
在 C++中
// my_implementation.cpp
#include <torch/torch.h>
#include <unordered_set>
// can use templates as well. But let's keep it
// simple
using scalar_t = float;
at::Tensor unique_float(at::Tensor input_) {
// only works for floats
AT_ASSERT(input_.type().scalarType() == at::ScalarType::Float, "input must be a float tensor");
// and CPU tensors
AT_ASSERT(!input_.type().is_cuda(), "input must be a CPU tensor");
// make the input contiguous, to simplify the implementation
at::Tensor input = input_.contiguous();
// get the pointer that holds the data
scalar_t* input_data = input.data<scalar_t>();
// let's use a function from the std library to implement
// the unique function
std::unordered_set<scalar_t> set(input_data, input_data + input.numel());
// create the output tensor, with size set.size()
at::Tensor output = input.type().tensor({static_cast<int64_t>(set.size())});
scalar_t* output_data = output.data<scalar_t>();
// copy the content of the set to the output tensor
std::copy(set.begin(), set.end(), output_data);
return output;
}
// this defines the functions exposed to Python
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("unique_float", &unique_float, "Unique for float tensors");
}
在 Python 中
import torch
from torch.utils.cpp_extension import load as load_ext
# pass the source files, they will be compiled on the fly
# and will return a python module
_C = load_ext('my_unique_lib', sources=['my_implementation.cpp'])
# now can use the functions implemented in C++
unique = _C.unique_float
a = torch.tensor([1.0, 2.0, 1.0])
print(unique(a))
# tensor([ 2., 1.])
▌Window 支持
新版本中,PyTorch 将正式支持 Windows。我们为 Python3.5和 3.6 提供预编译的 Conda 二进制文件和 pip 文件。
但是,Windows 上的 PyTorch 不支持分布式训练,这可能会比 Linux/OSX系统上运行得慢一点,因为 Visual Studio 支持较早版本的 OpenMP。
与往常一样,你可以在 Pytorch 官网上(http://pytorch.org)找到在 Windows 系统安装 PyTorch的命令。此外,你还可以通过访问http://pytorch.org/docs/stable/notes/windows.html,这里能够为你解答 Window 系统中 Pytorch 版本可能遇到的所有问题。
▌ONNX 改进
新的 ONNX 操作
支持输出 torch.max(input,dim)和 torch.min(input,dim)#6220
为 ReLU 函数添加符号以支持导出到 ONNX#5759
添加 sum,prod,sqrt 并改进 log_softmax 方法#4579
为 InstanceNorm 方法添加 ONNX 支持#4626
为 Elu 函数添加 ONNX 符号#3453
为 UpsamplingNearest2d 模块添加 ONNX 符号#3450
改进之处
当 ONNX 导出失败时打印目标的源位置#5652
将 onnx protobuf 绑定导出到 python中#6651
在 ConvTranspose 模块中支持 output_padding 方法#4583
更好的 RNN 支持
新版本的 PyTorch 可以将一部分 RNN 导出到 ONNX 中#4409
将 Elman RNN 的输出添加到 ONNX#4613
在 ONNX 导出的填充序列中支持批次优先原则#5360
将双向 Elman RNN 的输出添加到 ONNX 中#5120
将 RNN 导出到 ONNX 中以便正确处理序列长度#4695
支持 GRU 导出到 ONNX 中#4390
Bug修复
修复 ONNX 中的 3D 平均池化bug#6101
修复复制/反射板上的 onnx 导出#4263
▌其他改进
为张量实现 __dir__ 方法,以便能够自动编辑并查询张量中可能的字段
将 numpy()和 from_numpy()方法添加到 HalfTensor中
启用 TensorDataset,以便输入任意数量的张量。
将 padding_value 方法添加到 torch.nn.utils.rnn.pad_sequence模块中
将 total_length 选项添加到 pack_padded_sequence 模块中,这在使用DataParallel 模块时将变得非常有用,因为我们可以确保我们使用相同长度的序列。
提高 torch.arange 的数值精度,使其与 numpy.arange 一致
改进 torch.load()和torch.save()方法以支持任意类似文件的对象
改进 torch.nn.functional.grid_sample 模块以支持 2D(空间)和 3D(体积)的输入
在 DataLoader 中设置 python 的随机种子,以提高实验的可重复性
将 __delitem__ 方法添加到 nn.Sequential 模块中。在新版本中可以删除 nn.Sequential模块的任意元素。例如:
model = nn.Sequential(nn.Linear(2, 2), nn.ReLU(), nn.Linear(2, 2))
del model[1] # deletes nn.ReLU
新版本中的 ReduceLROnPlateau 可以进行序列化#5300
添加选项以清除 CPU上的非正常数字#5294
新版本中 PyTorch 将公开 conv1d,conv2d 和 conv3d 所对应的输入和权重的变化情况#5408
添加对列表或者张量使用时 pack_padded_sequence 的调用支持#5133
支持 nn.Embedding 方法中的 padding_idx 的负索引值#4496
添加对 pack_padded_sequence 反向传播过程的支持#4512
将nn.utils.rnn.pad_sequence和nn.utils.rnn.pack_sequence添加到可变长度张量的填充列表中,并打包一个可变长度张量列表。
添加 torch.cuda.memory_cached,torch.cuda.max_memory_cached,torch.cuda.memory_allocated和 torch.cuda.max_memory_allocated方法,用于检查 CUDA 内存使用情况#4511
如果新的视图尺寸与张量的原始尺寸和步幅兼容,则允许查看非连续张量。#4062
新版本中 NLLLoss 和 CrossEntropyLoss 能够支持2个以上的维度。#4654
添加一个选项以不显示 model_zoo 的下载进度条#4135
新版本中你可以将模块分配给 nn.Sequential 的索引。#4931
新版本中你可以用一个 numpy array 方法 np.longlong 来创建张量#4367
更改autograd执行顺序以便更好的使用,这也将大大改善大模型的内存使用量。#4746
将 AMSgrad 模式添加到 Adam 和 SparseAdam优化器中。#4034
添加更好的 torch.autograd.profiler 以支持使用 cudaEventAPI 进行 CUDA 分析。#3734
新版本中 torch.set_num_threads 能够设置相应的 MKL 选项,因此你不再需要使用环境变量来控制它。#4949
▌性能的提高
加速 CPU 中 nn.EmbeddingBag 模块,使得训练得总体速度提高30%#5433
将 Python 中的 nn.MarginRankingLoss,nn.CosineEmbeddingLoss,nn.HingeEmbeddingLoss 和 nn.TripletMarginLoss移到 Aten 后端,在某些情况下这将使性能提升3倍。#5346,#5646,#5080,#5680
将 pin_memory()作为 NativeFunction 实现#4094
保存用于反向计算 self.numel()函数而不是用于节省内存的 self 参数#5747
在特定情况下,逐点重排列操作可以使性能提高10倍。#4174
在小案例中将 normal_ 向量化可以带来5-6倍性能加速#4312
允许在新版 PyTorch 中使用 GPU Direct 进行广播操作#4183
为3D 输入案例加速 nn.Linear 模块#5279
通过并行化 vol2col 和 col2vol加速 CPU 上的 Conv3D 操作#4824
为 sigmoid 函数添加 AVX2 实现,实验表明这将带来大约10倍的性能加速#5010
使用快速整数除法算法来避免内核中的除法运算的内存占用。#5054
提高 CUDA 中随机数生成的内存占用率#5710
为常规规范的优化添加标准优化形式#5722
添加快速融合的 GLU 反向传播过程#5782
通过使用 std :: vector + sort 而不是 std ::set 来优化独特排序,这可以带来高达5倍的性能加速。#5913
加快维数的求和过程#6026
在前向和反向过程启用 MKLDNN 卷积操作。#6062
使用 OpenMP 并行化非连续的逐点操作#2764
将 Cudnn Tensor Core 操作添加到 Volta 的 RNN 中#3409
向量化 exp,log,sin,cos#6078
在多个反向过程中通过 grad_inputs 来重复使用中间结果#3526
分布式
DistributedDataParallel:使用混合精度支持的 NCCL 后端,这将带来10%的性能提升#5064
略微提高 DistributedDataParallel 模块在多进程分布式训练方面的性能(单 GPU 绑定)#4870
▌bug 修复
torch 操作
改进 torch.digamma 操作以提高极点附近的精度#6517
修复 Tensor.random 操作的负输入 bug#6463
修复 tensor.permute(dims)操作在反向过程中对负值 dims 未定义行为 bug#5945
修复 torch.remainder 运算符中的整数溢出bug(它将在以2**48为除数时中断)#5906
修复 torch.bmm 操作中的内存泄漏 bug#5744
使 scatter_add_ 的维度检查器与 scatter_ 的一致#5659
修复 CPU torch.multinomial 操作中非连续概率的张量输入 bug(先前的版本,它会覆盖输入的数据)#5093
修复 CUDA torch.multinomial 使用不正确的步幅并能够选择零概率事件的 bug#5774,#5238
支持 index_select 的空索引张量#3429
支持 CUDA Tensor.put_ 中的空索引张量#4486
利用空张量提高 torch.cat 的稳定性#3602,#5971,#5819
在任何输入尺寸未对齐的情况下修复 torch.fft #6118
改进 CUDA btrifact 的错误消息#5644
未请求 torch.symeig 时,为特征向量张量返回零#3411
修复张量上的 torch.btrifact 操作#4318
修复张量上的 torch.pstrf 操作#4883
修复 torch.median 中的内存泄漏#6889
当some = False 6870时,修复 SVD 操作中反向过程的非方形矩阵 bug
core
检测 _C 共享库的重新初始化,这通常会导致一些错误 bug#6232
修复所有零字节张量的索引 bug#3926
只允许使用稠密浮点类型作为默认张量类型#5674
在将 CUDA 张量类型设置前初始化 CUDA 以防止其崩溃#4788
如果 CUDA 未初始化,修复 from_dlpack 中的失败错误。#4182
使用 numpy 数组,修复创建 CUDA 张量时的崩溃#5850
在某些操作系统上,修复多处理进程中的空张量共享问题#6229
autograd
还原 allow_unused 功能:当可微分输入未被使用或无法访问时抛出错误#6553
修复 output_nr 未被正确递增的问题。这导致在某些输入不需要 _grad 的操作在反向传播过程中发生崩溃#4812
修复 torch.autograd.profiler 中的 nvprof 解析问题#5840
nn 层
仅支持在特定维度中为自适应池指定大小#3127
修复反射填充边界检查,以避免无效的内存访问#6438
修复 NLLLoss 的错误消息#5299,#6072
在 CUDA 上修复 kl_div 的反向过程。先前版本中它在计算 gradInput时不会考虑 gradOutput#5814
修复线性的错误偏差大小#5992
修复nn.functional.convNd 和 nn.functional.conv_transposeNd 模块的错误消息#5701
检查输入的维度与目标是否匹配,而不是与一些损失函数的元素数量匹配#5085
修复 torch.diag 操作在反向传播过程所返回方形渐变与非方形输入#4538
修复卷积类型不匹配的错误消息#5815
添加 align_corners 选项以便进行线性插值上采样操作,并使默认上采样行为与其他框架相一致#5927
当 log_input = False 时,防止 poisson_nll_loss 出现数值问题#3336
CUDA
确保卷积权重是连续的,以修复 CUDA ConvTranspose 中的双反向操作#4543
二次修复 CUDA 中的反向传播过程#4460
稀疏性
修复当 sparse = True 时的嵌入使用问题#4686
当输入仅包含 padding_idx 时,修复反向传播过程的稀疏嵌入问题#6211
处理从 CPU,GPU 空稀疏张量的复制问题。#5361
DataLoader
将参数检查添加到 torch.utils.data.Sampler 类中,修复 DataLoader尝试将整个数据集加载到非整数批处理大小的问题。#6249
设置 dataloader.batch_size = None 时给出 batch_sampler,修复 DataLoader将 batch_size 报告为1的错误。#6108
改善 DataLoader 中的信号处理问题#4643
关闭时忽略 FileNotFoundError 问题#5380
修复预处理的确定性问题#4640
Optim
在加载优化程序状态字典时以提高张量生成的可用性#3658
以确定性顺序列出模型参数以提高 load_state_dict()的稳定性#6031
为所有优化器添加参数范围检查#6000
修复 SparseAdam 的 AMSGrad 模式问题#4314
分布式和多 GPU
修复由于分离错误而导致的一些分布式训练错误#5829
在 no_grad 模块中运行 DataParallel 时,不要修改 requires_grad#5880
为分布式数据并行稳定性添加 broadcast_coalesce 的 GPU 保护#5655
原文链接:
https://github.com/pytorch/pytorch/releases/tag/v0.4.0
AI科技大本营现招聘AI记者和资深编译,有意者请将简历投至:gulei@csdn.net,期待你的加入!

☟☟☟点击 | 阅读原文 | 查看更多精彩内容
以上是关于PyTorch 重磅更新,不只是支持 Windows的主要内容,如果未能解决你的问题,请参考以下文章