84 页的 PyTorch 模型训练实用教程中文版发布!
Posted AI有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了84 页的 PyTorch 模型训练实用教程中文版发布!相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
机器之心授权转载,禁二次转载
前言
自 2017 年 1 月 PyTorch 推出以来,其热度持续上升,一度有赶超 TensorFlow 的趋势。PyTorch 能在短时间内被众多研究人员和工程师接受并推崇是因为其有着诸多优点,如采用 Python 语言、动态图机制、网络构建灵活以及拥有强大的社群等。因此,走上学习 PyTorch 的道路已刻不容缓。
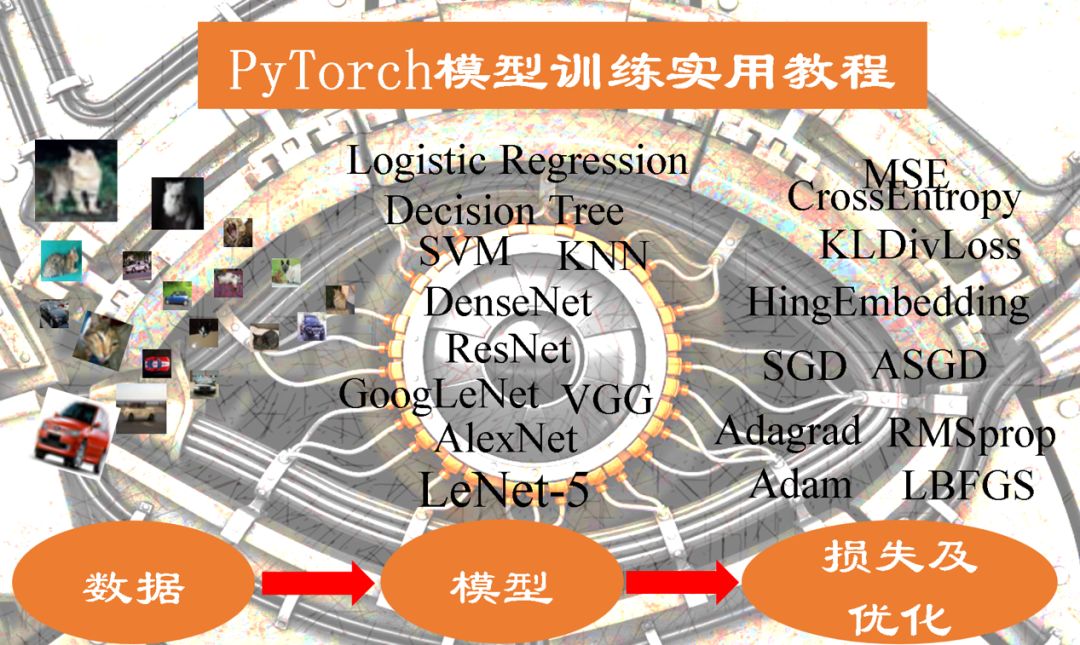
本教程以实际应用、工程开发为目的,着重介绍模型训练过程中遇到的实际问题和方法。如上图所示,在机器学习模型开发中,主要涉及三大部分,分别是数据、模型和损失函数及优化器。本文也按顺序的依次介绍数据、模型和损失函数及优化器,从而给大家带来清晰的机器学习结构。
通过本教程,希望能够给大家带来一个清晰的模型训练结构。当模型训练遇到问题时,需要通过可视化工具对数据、模型、损失等内容进行观察,分析并定位问题出在数据部分?模型部分?还是优化器?只有这样不断的通过可视化诊断你的模型,不断的对症下药,才能训练出一个较满意的模型。
为什么写此教程
前几年一直在用 Caffe 和 MatConvNet,近期转 PyTorch。当时只想快速地用上 PyTorch 进行模型开发,然而搜了一圈 PyTorch 的教程,并没有找到一款适合的。很多 PyTorch 教程是从学习机器学习 (深度学习) 的角度出发,以 PyTorch 为工具进行编写,里面介绍很多模型,并且附上模型的 demo。
然而,工程应用开发中所遇到的问题并不是跑一个模型的 demo 就可以的,模型开发需要对数据的预处理、数据增强、模型定义、权值初始化、模型 Finetune、学习率调整策略、损失函数选取、优化器选取、可视化等等。鉴于此,我只能自己对着官方文档,一步一步地学习。
起初,只是做了一些学习笔记,后来觉得这些内容应该对大家有些许帮助,毕竟在互联网上很难找到这类内容的分享,于是此教程就诞生了。
本教程内容及结构
本教程内容主要为在 PyTorch 中训练一个模型所可能涉及到的方法及函数,并且对 PyTorch 提供的数据增强方法(22 个)、权值初始化方法(10 个)、损失函数(17 个)、优化器(6 个)及 tensorboardX 的方法(13 个)进行了详细介绍。
本教程分为四章,结构与机器学习三大部分一致:
第一章,介绍数据的划分,预处理,数据增强;
第二章,介绍模型的定义,权值初始化,模型 Finetune;
第三章,介绍各种损失函数及优化器;
第四章,介绍可视化工具,用于监控数据、模型权及损失函数的变化。
本教程适用读者:
想熟悉 PyTorch 使用的朋友;
想采用 PyTorch 进行模型训练的朋友;
正采用 PyTorch,但无有效机制去诊断模型的朋友;
干货直达:
1.6 transforms 的二十二个方法
2.2 权值初始化的十种方法
3.1 PyTorch 的十七个损失函数
3.3 PyTorch 的十个优化器
3.4 PyTorch 的六个学习率调整方法
4.1 TensorBoardX
项目代码:https://github.com/tensor-yu/PyTorch_Tutorial







为了展示该教程的内容,读者可试读第二章的第一小节,了解PyTorch如何搭建模型:
第二章 模型
第二章介绍关于网络模型的一系列内容,包括模型的定义,模型参数初始化方法,模型的保存和加载,模型的 finetune(本质上还是模型权值初始化),首先介绍模型的定义。
2.1 模型的搭建
2.1.1 模型定义的三要
首先,必须继承 nn.Module 这个类,要让 PyTorch 知道这个类是一个 Module。
其次,在__init__(self) 中设置好需要的「组件"(如 conv、pooling、Linear、BatchNorm 等)。
最后,在 forward(self, x) 中用定义好的「组件」进行组装,就像搭积木,把网络结构搭建出来,这样一个模型就定义好了。
接下来,请看代码,在/Code/main_training/main.py 中可以看到定义了一个类 class Net(nn.Module),先看__init__(self) 函数:
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
第一行是初始化,往后定义了一系列组件,如由 Conv2d 构成的 conv1,有 MaxPool2d 构成的 poo1l,这些操作均由 torch.nn 提供,torch.nn 中的操作可查看文档:https://PyTorch.org/docs/stable/nn.html#。
当这些组件定义好之后,就可以定义 forward() 函数,用来搭建网络结构,请看代码:
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
x 为模型的输入,第一行表示,x 经过 conv1,然后经过激活函数 relu,再经过 pool1 操作;
第二行于第一行一样;第三行,表示将 x 进行 reshape,为了后面做为全连接层的输入;
第四,第五行的操作都一样,先经过全连接层 fc,然后经过 relu;
第六行,模型的最终输出是 fc3 输出。
至此,一个模型定义完毕,接着就可以在后面进行使用。例如,实例化一个模型 net = Net(),然后把输入 inputs 扔进去,outputs = net(inputs),就可以得到输出 outputs。
2.1.2 模型定义多说两句
上面只是介绍了模型定义的要素和过程,但是在工程应用中会碰到各种各样的网络模型,这时,我们就需要一些实用工具来帮助我们定义模型了。
这里以 Resnet34 为例介绍「复杂」模型的定义,这部分代码从 github 上获取。
class ResidualBlock(nn.Module):
'''
实现子module: Residual Block
'''
def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel) )
self.right = shortcut
def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet34(BasicModule):
'''
实现主module:ResNet34
ResNet34包含多个layer,每个layer又包含多个Residual block
用子module来实现Residual block,用_make_layer函数来实现layer
'''
def __init__(self, num_classes=2):
super(ResNet34, self).__init__()
self.model_name = 'resnet34'
# 前几层: 图像转换
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
# 重复的layer,分别有3,4,6,3个residual block
self.layer1 = self._make_layer( 64, 128, 3)
self.layer2 = self._make_layer( 128, 256, 4, stride=2)
self.layer3 = self._make_layer( 256, 512, 6, stride=2)
self.layer4 = self._make_layer( 512, 512, 3, stride=2)
#分类用的全连接
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
'''
构建layer,包含多个residual block
'''
shortcut = nn.Sequential(
nn.Conv2d(inchannel,outchannel,1,stride, bias=False),
nn.BatchNorm2d(outchannel))
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x, 7)
x = x.view(x.size(0), -1)
return self.fc(x)
还是从三要素出发看看是怎么定义 Resnet34 的。
首先,继承 nn.Module;
其次,看__init__() 函数,在__init__() 中,定义了这些组件,self.pre,self.layer1-4, self.fc ;
最后,看 forward(),分别用了在__init__() 中定义的一系列组件,并且用了 torch.nn.functional.avg_pool2d 这个操作。
至此,网络定义完成。
以为就完了?怎么可能,__init__() 函数中的组件是怎么定义的,在__init__() 中出现了 torch.nn.Sequential。
组件定义还调用函数_make_layer(),其中也用到了 torch.nn.Sequential,其中还调用了 ResidualBlock(nn.Module),在 ResidualBlock(nn.Module) 中有一次调用了 torch.nn.Sequential。
torch.nn.Sequential 到底是什么呢?为什么都在用呢?
2.1.3 nn.Sequetial
torch.nn.Sequential 其实就是 Sequential 容器,该容器将一系列操作按先后顺序给包起来,方便重复使用。例如 Resnet 中有很多重复的 block,就可以用 Sequential 容器把重复的地方包起来。
官方文档中给出两个使用例子:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
小结:
模型的定义就是先继承,再构建组件,最后组装。
其中基本组件可从 torch.nn 中获取,或者从 torch.nn.functional 中获取,同时为了方便重复使用组件,可以使用 Sequential 容器将一系列组件包起来,最后在 forward() 函数中将这些组件组装成你的模型。
获取方式:
链接:
https://pan.baidu.com/s/11hvPGusAopXNwuCsuLilCA
提取码:
anw5
【推荐阅读】
以上是关于84 页的 PyTorch 模型训练实用教程中文版发布!的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch模型训练实用教程学习笔记:一数据加载和transforms方法总结