PyTorch进阶之路:张量与梯度
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch进阶之路:张量与梯度相关的知识,希望对你有一定的参考价值。
选自medium
机器之心编译
PyTorch 是 Facebook 开发和维护的一个开源的神经网络库,近来的发展势头相当强劲,也有越来越多的开发者为其撰写,本文也是其中之一。这是「PyTorch: Zero to GANs」系列教程的第一篇,介绍了 PyTorch 模型的基本构件:和梯度。
完整系列教程包括:
PyTorch 基础:张量&梯度(本文)
& :https://medium.com/jovian-io/linear-regression-with-pytorch-3dde91d60b50
用 Logistic 回归进行分类:https://medium.com/jovian-io/image-classification-using-logistic-regression-in-pytorch-ebb96cc9eb79
未完待续.. (神经网络、CNN、RNN、GAN 等)
本系列教程旨在让用户更好地利用 PyTorch 学习深度学习和神经网络。本文将介绍 PyTorch 模型的基本构件:张量和梯度。
系统设置
通过在 Jupyter 内部直接运行单个命令,Jovian 使得在云端共享 Jupyter notebook 变得很容易。它还可以捕获你运行 notebook 所需的 Python 环境和库,因此任何人(包括你自己)都能复现你的研究。
操作步骤如下:
1. 根据以下指南安装 Anaconda。你可能还要将 Anaconda 二进制文件添加到 PATH 系统中,以便能够运行 conda 命令行工具。
2. 通过在 Mac/Linux 终端或 Windows 命令提示符下运行以下命令(不要$)来安装 jovian Python 库:
$ pip install jovian --upgrade3. 使用 jovian clone 命令下载本文的 notebook:
$ jovian clone e5cfe043873f4f3c9287507016747ae5这样做可以创建目录 01-pytorch-basics,包含 Jupyter notebook 和 Anaconda 环境文件夹。
$ ls 01-pytorch-basics
01-pytorch-basics.ipynb environment.yml4. 现在我们可以打开目录,使用 conda 通过单个命令安装所需的 Python 库(Jupyter、PyTorch 等):
$ cd 01-pytorch-basics
$ conda env update5. 通过运行以下命令,激活虚拟环境:
$ conda activate 01-pytorch-basics对于旧版 conda 的安装,你可能需要运行命令:source activate 01-pytorch-basics。
6. 一旦激活了虚拟环境,我们通过运行以下命令来启动 Jupyter:
$ jupyter notebook7. 现在,你可以通过点击终端上显示的链接或访问 http://localhost:8888 来访问 Jupyter 的 web 界面。
然后,你可以点击 01-pytorch-basics.ipynb 文件夹,打开它然后运行代码。如果想自己输入代码,你还可以通过点击「New」键来创建新的 notebook。
首先导入 PyTorch:

张量
本质上来说,PyTorch 是一个处理张量的库。一个张量是一个数字、向量、矩阵或任何 n 维数组。我们用单个数字创建一个张量:
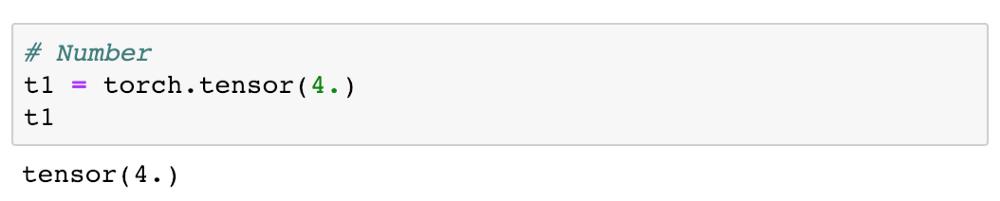
4. 是 4.0 的缩写。它用来表示你想创建浮点数的 Python(和 PyTorch)。我们可以通过检查张量的 dtype 属性来验证这一点:

我们可以试着创建复杂一点的张量:
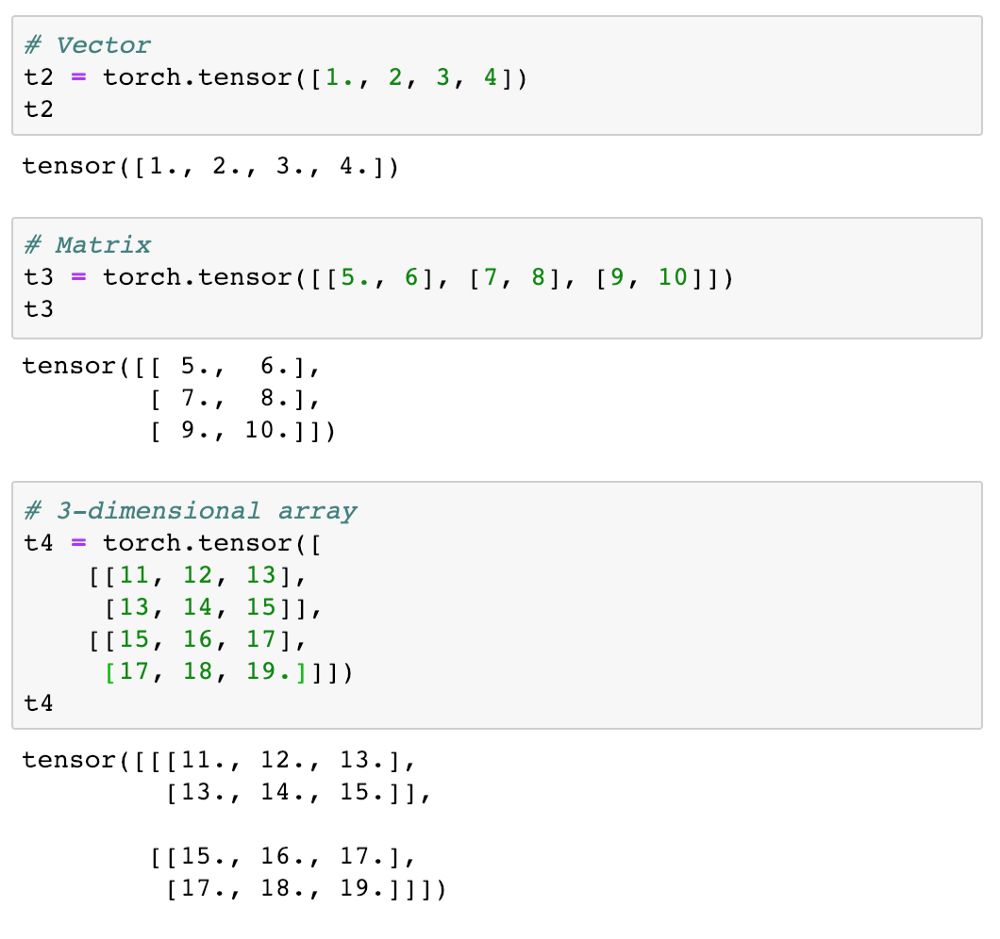
张量可以有任何维数。每个维度有不同的长度。我们可以用张量的.shape 属性来查看每个维度的长度。

张量运算和梯度
我们可以将张量与常用的算数运算相结合。如下:

我们已经创建了 3 个张量:x、w 和 b。w 和 b 有额外的参数 requires_grad,设置为 True。一会儿就可以看看它能做什么。
通过结合这些张量,我们可以创建新的张量 y。
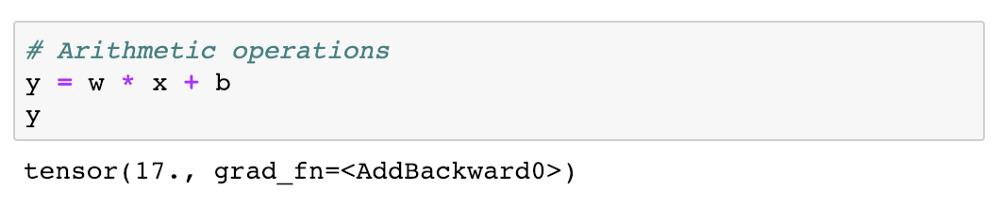
如预期所料,y 是值为 3 * 4 + 5 = 17 的张量。PyTorch 的特殊之处在于,我们可以自动计算 y 相对于张量(requires_grad 设置为 True)的导数,即 w 和 b。为了计算导数,我们可以在结果 y 上调用.backward 方法。

y 相对于输入张量的导数被存储在对相应张量的.grad 属性中。
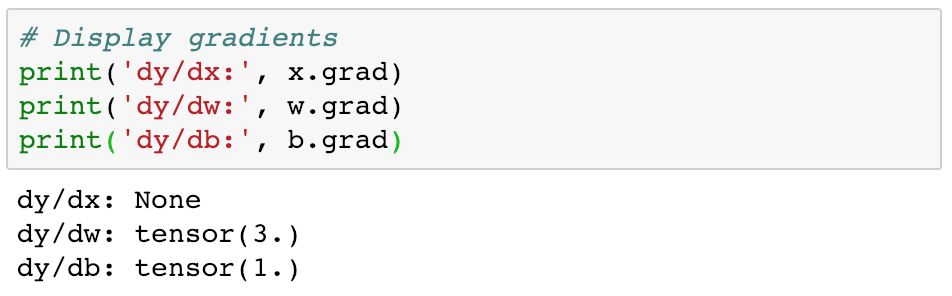
如预期所料,dy/dw 的值与 x 相同(即 3),dy/db 的值为 1。注意,x.grad 的值为 None,因为 x 没有将 requires_grad 设为 True。w_grad 中的「grad」代表梯度,梯度是导数的另一个术语,主要用于处理矩阵。
与 Numpy 之间的互操作性
Numpy 是 Python 中用于数学和科学计算的流行开源库。它支持在大型多维数组上进行高效运算,拥有一个支持多个库的大型生态系统。这些库包括:
用于画图、可视化的 Matplotlib
用于图像和视频处理的 OpenCV
用于文件 I/O 和数据分析的 Pandas
PyTorch 并没有重新创造 wheel,而是与 Numpy 很好地交互,以利用它现有的工具和库生态系统。

可以用 torch.fron_numpy 将 Numpy 数组转化为 PyTorch 张量。

接下来可以验证 Numpy 数组和 PyTorch 张量是否拥有类似的数据类型。

可以使用张量的.to_numpy 方法将 PyTorch 张量转化为 Numpy 数组。
PyTorch 和 Numpy 之间的互操作性真的非常重要,因为你要用的大部分数据集都可能被读取并预处理为 Numpy 数组。
提交及上传 notebook
最后一步是保存并利用 jovian 库提交以上工作
Jovian 将 notebook 上传到 https://jvn.io (https://jvn.io/),用以上方式为你的 notebook 捕获 Python 环境并创建可共享的链接。你可以利用这一链接分享自己的作品,让任何人都可以利用 jovian clone 命令轻松复现。Jovian 还拥有一个强大的评论界面,供你和其他人讨论及评论你 notebook 中的某个部分:
延伸阅读
链接:https://pytorch.org/docs/stable/tensors.html
如果你想利用交互式 Jupyter 环境的优势来进行张量实验并尝试上述的各种不同运算组合,可以尝试下面这些:
如果上面提到的例子中,一个或多个「x」、「w」或「b」是矩阵,而不是数字,该怎么办?在这种情况下,结果「y」、梯度 w.grad 和 b.grad 看起来将是怎样的?
如果「y」是用 torch.tensor 创建的矩阵,矩阵的每个元素都表示为数字张量「x」、「w」和「b」的组合,该怎么办?
如果我们有一个运算链,而不止一个运算,即 y = x * w + b, z = l * y + m, e =c * z + d,该怎么办?调用 e.backward() 会发生什么?
如果你对此感兴趣,且想了解更多关于矩阵导数的信息,可以参考:
链接:https://en.wikipedia.org/wiki/Matrix_calculus#Derivatives_with_matrices
以上,我们完成了关于 PyTorch 中张量和梯度的讨论,下一步的主题将是线性回归。
该系列文章主要受到下面两篇文章的启发:
Yunjey Choi,PyTorch Tutorial for Deep Learning Researchers
Jeremy Howard,FastAI development notebooks
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于PyTorch进阶之路:张量与梯度的主要内容,如果未能解决你的问题,请参考以下文章