PyTorch进阶之路:使用logistic回归实现图像分类
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch进阶之路:使用logistic回归实现图像分类相关的知识,希望对你有一定的参考价值。
选自Medium
机器之心编译
参与:Panda
前段时间,机器之心已经编译介绍了「PyTorch:Zero to GANs」系列的前两篇文章,参阅《PyTorch 进阶之路:、》,其中讲解了张量、梯度、线性回归和梯度下降等基础知识。本文是该系列的第三篇,将介绍如何使用 logistic 回归实现图像分类。
在本教程中,我们将使用我们已有的关于 和的知识来求解一类非常不同的问题:图像分类。我们将使用著名的 MNIST 手写数字数据库作为我们的训练数据集。其中含有 28×28 像素的灰度手写数字图像(0 到 9),并且每张图像都带有指示该图像的数字的标签。下面是一些来自该数据集的样本:
图源:http://yann.lecun.com/exdb/mnist/
系统设置
如果你想一边阅读一边运行代码,你可以通过下面的链接找到本教程的 Jupyter Notebook:
https://jvn.io/aakashns/a1b40b04f5174a18bd05b17e3dffb0f0
你可以克隆这个笔记,使用 conda安装必要的依赖包,然后通过在终端运行以下命令来启动 Jupyter:
pip install jovian --upgrade # Install the jovian library
jovian clone a1b40b04f5174a18bd05b17e3dffb0f0 # Download notebook
cd 03-logistic-regression # Enter the created directory
conda env update # Install the dependencies
conda activate 03-logistic-regression # Activate virtual env
jupyter notebook # Start Jupyter
如果你的 conda 版本更旧一些,你也许需要运行 sourceactivate 03-logistic-regression 来激活环境。对以上步骤的更详细的解释可参阅本教程的前一篇文章。
探索数据
我们首先导入 torch 和 torchvision。torchvision 包含一些用于操作图像数据的实用程序。其中还有辅助工具类,可用于自动下载和导入 MNIST 等常用数据集。
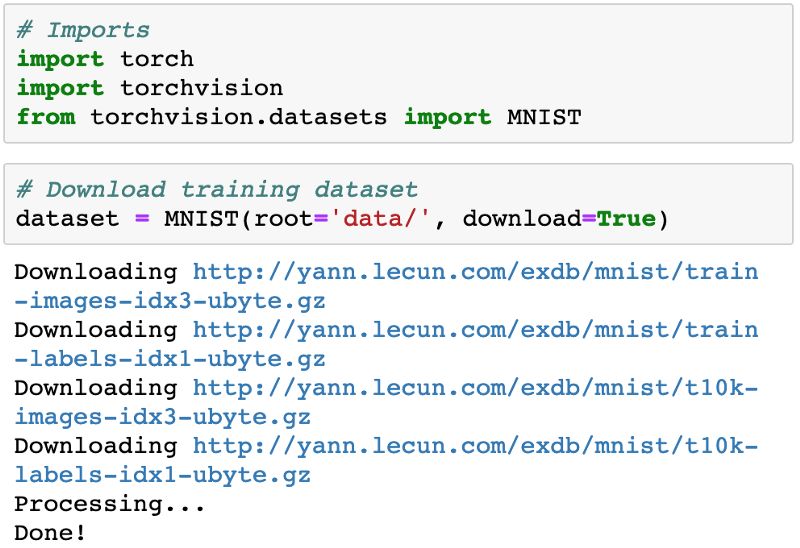
第一次执行该语句时,数据会被下载到笔记本旁边的 data/ 目录并创建一个 PyTorchDataset。在后续执行时,因为数据已经下载完成,所以这个下载步骤会跳过。我们检查一下数据集的大小:

这个数据集中有 60000 张可用于训练模型的图像。另外还有一个额外的测试集,包含 10000 张图像;你可以通过向 MNIST 类传递 train=False 来创建它。

我们看看训练集的一个样本元素:

这是一个数据对——包含一张 28×28 的图像和一个标签。这个图像是PIL.Image.Image 类的一个对象,而 PIL.Image.Image 又是 Python 图像处理库 Pillow 的一分子。我们可以使用 matplotlib在 Jupyter 中查看图像,事实上这是 Python 的数据科学绘图制图库。

除了导入 matplotlib,我们还加上了一个特殊的语句 %matplotlib inline,这是为了指示 Jupyter 我们希望在笔记内绘图。如果没有这一行,Jupyter 将会以弹窗形式展示图像。以 % 开头的指令被称为 IPython 魔法命令,可用于配置 Jupyter 自身的行为。你可在下列链接找到完整的魔法命令列表:
https://ipython.readthedocs.io/en/stable/interactive/magics.html
我们试试查看几张数据集中的图像。
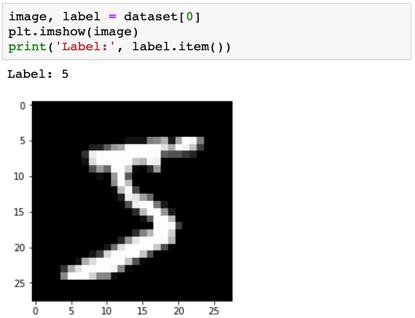
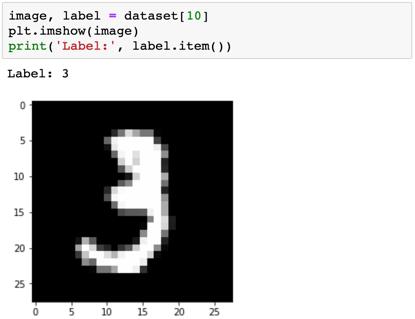
很明显这些图像的尺寸很小,有时候甚至人眼都难以辨认具体数字。但看看这些图像是有用的,而我们目前只有一个问题:PyTorch 不知道如何处理这些图像。我们需要将这些图像转换成张量。要做到这一点,我们可以在创建数据集时指定一个变换。

在加载图像时,PyTorch 数据集让我们可以指定一个或多个应用于这些图像的变换函数。torchvision.transforms包含很多这种预定义的函数,而我们将使用 ToTensor 变换将这些图像转换成 PyTorch 张量。
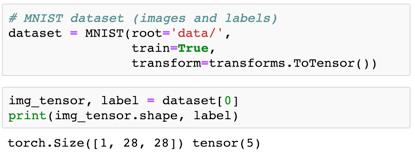
现在图像转换成了 1×28×28 的张量。第一个维度用于跟踪颜色通道。因为 MNIST 数据集中的图像是灰度图像,所以只有一个通道。某些数据集的图像有颜色,这时会有三个通道:红绿蓝(RGB)。我们来看看这个张量中的一些样本值:
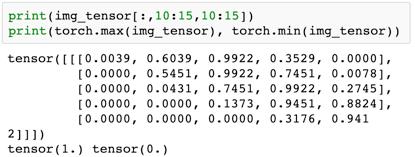
这些值的取值范围是 0 到 1,其中 0 表示黑色,1 表示白色,介于两者之间的值表示不同程度的灰。我们还可以使用 plt.imshow 将张量绘制成图像形式。
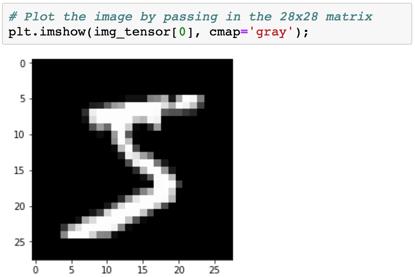
注意,我们只需要将这个 28×28 的矩阵传递给 plt.imshow,而不带颜色通道。我们也可以传递一个颜色分布图(cmap='gray'),以指示我们想得到灰度图像。
训练数据集和验证数据集
在构建真实世界的机器学习模型时,一种常见做法是将数据分为三部分:
训练集——用于训练模型,即计算损失以及使用梯度下降调整模型的权重
验证集——用于在训练时验证模型,调整超参数(学习速率等)以及选取最佳版本的模型
测试集——用于比较不同的模型或不同类型的建模方法,并报告模型的最终准确度
MNIST 数据集有 60000 张训练图像和 10000 张测试图像。这个测试集经过了标准化,因此不同的研究者可以基于同样的图像集报告他们的模型的结果。其中没有预定义的验证集,我们必须手动地将那60000 张图像分为训练数据集和验证数据集。
我们定义一个函数,让其可以随机地选取一定份额的图像作为验证集。

split_indices 可随机地混洗数组索引 0,1,..n-1,并从中分出所需的比例作为验证集。在创建验证集之前混洗索引是很重要的,因为训练图像通常是按目标标签排序的,即先是 0 的图像,然后是 1 的图像,2 的图像……如果我们选择最后 20% 的图像作为验证集,则该验证集将仅包含 8 和 9 的图像,而训练集中又没有 8 和 9 的图像。使用这样的训练集是不可能得到好模型的,也不可能在验证集(或真实数据集)上取得好的表现。
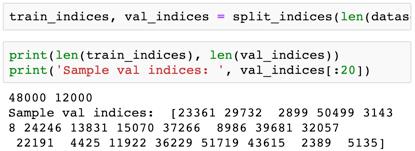
我们已经随机混洗了索引,并选择了一小部分(20%)作为验证集。现在我们可以使用 SubsetRandomSampler 为它们中的每一个创建PyTorch 数据加载器,它可从给定的索引列表随机地采用元素,创建分批数据。
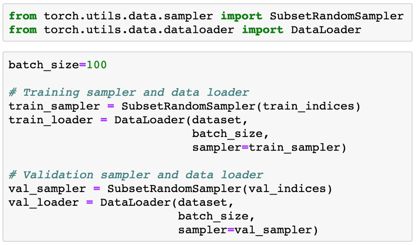
模型
现在我们已经准备好了数据加载器,我们可以定义我们的模型了。
模型几乎就等同于线性回归模型,其中有权重和偏置矩阵,输出是通过简单的矩阵运算(pred= x @ w.t() + b)得到的。
正如我们在线性回归时做的那样,我们可以使用 nn.Linear 创建模型,而不是手动地定义和初始化这些矩阵。
因为 nn.Linear需要每个训练样本都是一个向量,所以每个 1×28×28 的图像张量都需要展平成大小为 784(28×28)的向量,之后再传递给模型。
每张图像的输出都是一个大小为 10 的向量,该向量的每个元素都指示了该图像属于某个具体标签(0 到 9)的概率。为图像预测得到的标签即为概率最高的标签。

当然,在参数数量方面,这个模型比我们之前的模型要大很多。我们看看其中的权重和偏置。
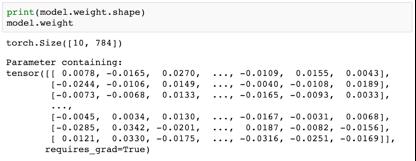

尽管这里总共有 7850 个参数,但概念上没有什么变化。我们试试使用我们的模型生成一些输出。我们将从我们的数据集取出第一批 100 张图像,再将它们传递进我们的模型。
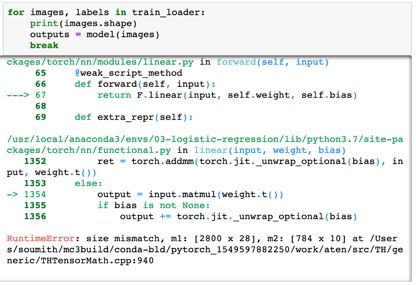
这会有一个报错,因为我们的输入数据形状不对。我们的图像的形状是 1×28×28,但我们需要它们是大小为 784的向量,也就是说我们需要将其展平。我们将使用张量的 .reshape方法,这让我们可以有效地将每张图像「看作是」展平的向量,同时又不会真正改变底层数据。
为了将这种额外的功能纳入我们的模型中,我们需要通过扩展 PyTorch 的 nn.Module 类定义一个定制模型。

在 __init__ 构造器方法中,我们使用 nn.Linear 对权重和偏置进行了实例化。在 forward 方法(在我们将一批输入传入模型时调用)中,我们将输入张量展开,然后将其传递给 self.linear。
xb.reshape(-1, 28*28) 的意思是我们想要 xb 张量的二维视图,其中沿第二个维度的长度是28×28(即 784)。.reshape 的一个参数可以设置为 -1(在这里是第一个维度),以让PyTorch 根据原始张量的形状自动找到它。
注意这个模型不再有 .weight 和 .bias 属性(因为它们现在是在.linear 属性内),但有可返回包含权重和偏置的列表的 .parameters 方法,并且可被 PyTorch优化器使用。

我们新的定制模型可以和之前一样使用。我们来看看效果:

对于这 100 张输入图像中的每一张,我们都会得到 10 个输出,每个输出对应一个类别。正如之前讨论的那样,这些输出表示概率,因此每个输出行的每个元素都应该在 0 到 1 之间且总和为 1,但很显然这里的情况并非如此。
为了将这些输出行转换成概率,我们可以使用 softmax 函数,其公式如下:
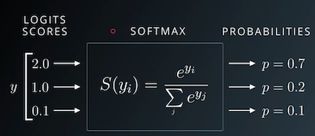
来自:Udacity
我们首先将输出行中的每个元素 yi 替换成 e^yi,使得所有元素为正,然后我们用每个元素除以所有元素的和以确保所得结果之和为1。
尽管实现 函数很容易(你应该试试看!),但我们将使用 PyTorch 内提供的实现,因为它能很好地处理多维张量(在这里是输出行的列表)。

softmax 函数包含在 torch.nn.functional 软件包中,并且需要我们指定 softmax 应用的维度。
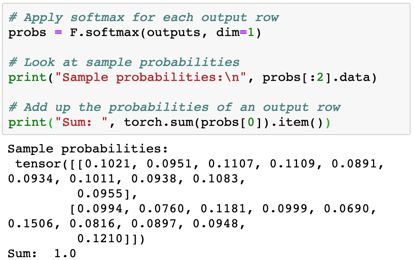
最后,我们只需选择每个输出行中概率最高的元素的索引,确定每张图像的预测标签即可。这可使用torch.max 完成,它会返回沿张量的一个特定维度的最大元素和该最大元素的索引。

上面打印出的数字是第一批训练图像的预测标签。我们将其与真实标签比较一下。

很明显,预测标签和真实标签完全不同。这是因为我们开始时对权重和偏置进行了随机初始化。我们需要训练模型,使之能做出更好的预测,也就是要使用梯度下降调整权重。
评估指标和损失函数
和线性回归时一样,我们需要一种评估模型表现的方法。一种自然的做法是找到标签被正确预测的百分比,也就是预测的准确度。

== 运算符执行的是两个同样形状的张量的逐元素的比较,并会返回一个同样形状的张量,其中0对应相等的元素,1 对应不相等的元素。将结果传递给 torch.sum,会返回预测正确的标签的数量。最后,我们将其除以图像总数,即可得到准确度。
我们先计算一下在第一批数据上当前模型的准确度。很显然,可以预料结果很差。

尽管准确度对我们(人类)而言是很好的评估模型的方法,但却不能用作我们使用梯度下降优化模型的损失函数,原因如下:
这是不可微分的函数。torch.max 和 == 都是非连续的和不可微分的运算,因此我们不能使用准确度来计算与权重和偏置有关的梯度。
它没有考虑模型预测的实际概率,所以不能提供足够的反馈以实现逐渐递进的改进。
由于这些原因,准确度虽然是很好的分类评估指标,但却不是好的损失函数。分类问题常用的一种损失函数是交叉熵,它的公式如下:
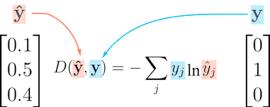
尽管看起来复杂,但实际上相当简单:
对于每个输出行,选取正确标签的预测概率。比如,如果一张图像的预测概率是 [0.1,0.3, 0.2, ...],而正确标签是 1,则我们选取对应的元素 0.3 并忽略其余元素。
然后,求所选概率的对数。如果概率高(即接近 1),则其对数是非常小的负值,接近 0。 如果概率低(即接近0),则其对数是非常大的负值。我们可以将结果乘上 -1,那么糟糕预测的损失就是一个较大的正值了。
最后,在所有输出行上取交叉熵的平均,得到一批数据的整体损失。
不同于准确度,交叉熵是一种连续且可微分的函数,并且能为模型的逐步改进提供良好的反馈(正确标签的概率稍微高一点就会让损失低一点)。这是很好的损失函数选择。
PyTorch 提供了一种有效的且对张量友好的交叉熵实现,这是torch.nn.functional 软件包的一分子。此外,它还能内部执行softmax,所以我们可以不将它们转换成概率地直接传入模型的输出。
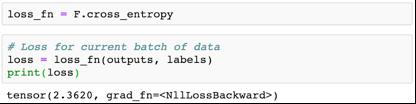
因为交叉熵是正确标签的预测概率的负对数在所有训练样本上的平均,所以解读所得数字(比如 2.23)的一种方式是将 e^-2.23(大约为 0.1)视为正确标签的平均的预测概率。损失越低,模型越好。
优化器
我们将使用 optim.SGD 优化器来在训练过程中更新权重和偏置,但会使用更高的学习率 1e-3。

批大小和学习率等参数需要在训练机器学习模型之前选取,它们也被称为超参数。要在合理的时间内训练出一个准确的模型,选择合适的超参数是至关重要的,这也是一个活跃的研究和实验领域。你可以随意尝试不同的学习率,看看其对训练过程的影响。
训练模型
现在我们已经定义好了数据加载器、模型、损失函数和优化器;万事俱备,就等训练了。这个训练过程几乎与线性回归的完全一样。但是,我们需要给我们之前定义的fit 函数配置参数,以在每轮 epoch 结束时使用验证集评估模型的准确度和损失。
我们先定义一个函数 loss_batch,其作用是:
计算一批数据的损失
如果提供了优化器,则选择性地执行梯度下降更新步骤
使用预测结果和实际目标选择性地计算一个指标(比如准确度)
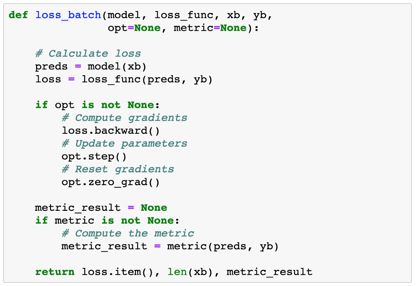
优化器是一个可选参数,作用是确保我们可以重复使用 loss_batch,以便在验证集上计算损失。我们还可返回批的长度作为结果的一部分,因为在为整个数据集组合损失/指标时,这会很有用。
接下来我们定义一个函数 evaluate,用于计算在验证集上的整体损失(如果有提供,也计算一个指标)。

如果该函数的作用不很清晰直观,你可以试试分开单独执行每个语句,然后看看结果。我们还希望重新定义accuracy 以直接操作整个输出批,因此我们可以将其用作 fit 中的一个指标。

注意,我们无需将 softmax 用于输出,因为它不会改变结果的相对顺序。这是因为 e^x 是一个递增函数(即如果 y1 > y2,则 e^y1 > e^y2),并且在对值求平均得到 softmax 之后同样成立。
我们看看使用初始的权重和偏置的模型在验证集上的表现。

初始准确度低于 10%,这样的结果对随机初始化的模型而言是可以预期的(因为随机猜测时,得到正确标签的可能性是十分之一)。还要注意,我们使用了 .format 方法,让消息字符串仅打印至小数点后四位数。
我们可以使用 loss_batch 和 evaluate 相当轻松地定义fit 函数。

我们现在可以训练模型了。试试训练 5 epoch,看看结果。
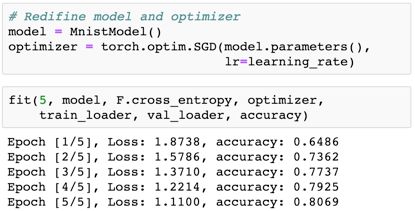
结果很不错!仅仅 5 epoch 训练,我们的模型就在验证集上达到了超过 80% 的准确度。我们多训练几个 epoch,看看能不能进一步提升结果。
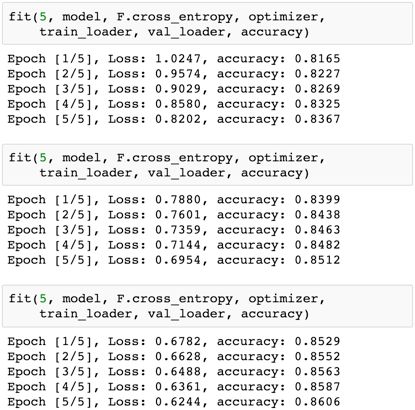
尽管多训练几个 epoch 确实能让准确度持续提升,但每 epoch 提升的程度也越来越小。使用折线图能更清楚地看出这一点。
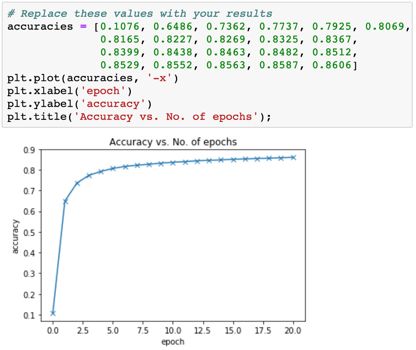
从上图可以相当清楚地看到,即使训练很长时间,该模型可能也无法超越 90% 的准确度阈值。一个可能的原因是学习率太高了。有可能模型的参数在损失最低的最优参数集周围跳变。你可以尝试降低学习率,然后再训练看看。
更可能的原因是模型本身不够强大。还记得我们的初始假设吗?我们假设其输出(在这个案例中是类别概率)是输入(像素强度)的线性函数,是通过执行输入与权重矩阵的矩阵乘法再加上偏置而得到的。这是相当弱的假设,因为图像中的像素强度与其表示的数字之间的关系可能不是线性的。尽管这样的假设在MNIST 这样的简单数据集上表现不错(我们得到了 85% 的准确度),但对于识别日常物体和动物等复制任务而言,我们需要更复杂精细的模型,才能近似图像像素和标签之间的非线性关系。
使用单张图像进行测试
尽管我们现在已经跟踪了模型的整体准确度,但也可了解一下模型在某些样本图像上的表现。我们使用预定义的10000 张图像的测试数据集中的图像测试一下我们的模型。我们先使用ToTensor 变换重新创建测试数据集。

下面是一张来自该数据集的样本图像。
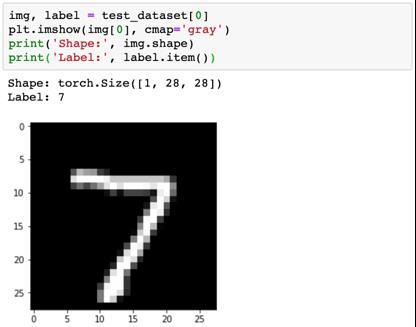
我们定义一个辅助函数 predict_image,使其返回单张图像张量的预测标签。

img.unsqueeze 会直接在1x28x28 张量的起始处增加另一个维度,使其成为一个 1×1×28×28 的张量,模型将其视为一个包含单张图像的批。
我们用一些图像来试试看。
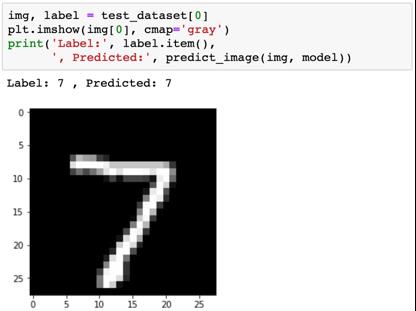
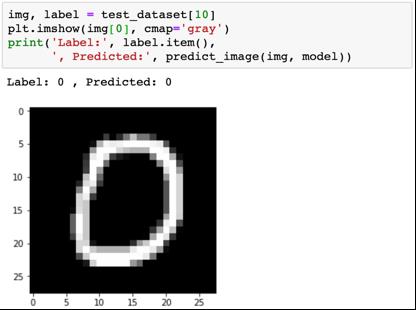
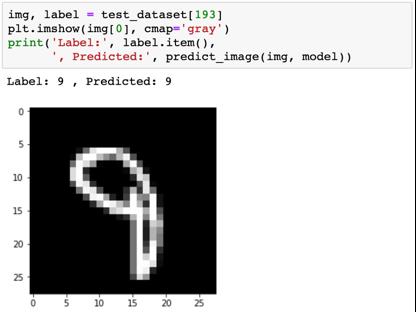
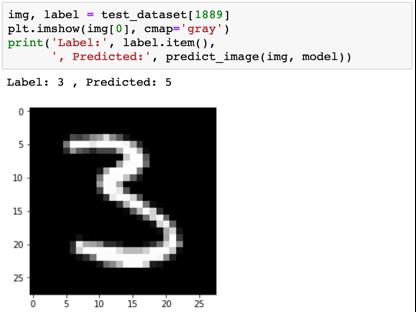
识别模型表现较差的地方有助于我们改进模型,具体做法包括收集更多训练数据、增加/降低模型的复杂度、修改超参数。
最后,我们看看模型在测试集上的整体损失和准确度。

可以预计准确度/损失结果与在验证集上时类似。如果不一致,我们可能需要与测试集(通常来自真实世界数据)的数据和分布近似的更好的验证集。
保存和加载模型
因为我们已经训练了模型很长时间并且实现了不错的准确度,所以为了之后能复用该模型以及避免重新开始再训练,我们可以将权重和偏置矩阵保存到磁盘。以下是保存模型的方法。

.state_dict 方法会返回一个 OrderedDict,其中包含映射到该模型的适当属性的所有权重和偏置。

要加载该模型的权重,我们可以实例化 MnistModel 类的一个新对象,并使用 .load_state_dict 方法。

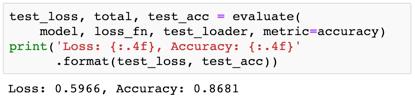
就像进行完整性检查一样,我们在测试集上验证一下该模型是否有与之前一样的损失和准确度。
提交和上传笔记
最后,我们可以使用 jovian 库保存和提交我们的成果。
jovian 会将笔记上传到 https://jvn.io,并会获取其 Python 环境并为该笔记创建一个可分享的链接。你可以使用该链接共享你的成果,让任何人都能使用jovian 克隆命令轻松复现它。jovian 还有一个强大的评论接口,让你和其他人都能讨论和点评你的笔记的各个部分。
总结与进阶阅读
我们在本教程中创建了一个相当复杂的训练和评估流程。下面列出了我们介绍过的主题:
用 PyTorch 处理图像(使用 MNIST 数据集)
将数据集分成训练集、验证集和测试集
通过扩展 nn.Module 类创建有自定义逻辑的 PyTorch 模型
使用 softmax 解读模型输出,并选取预测得到的标签
为分类问题选取优良的评估指标(准确度)和损失函数(交叉熵)
设置一个训练循环,并且也能使用验证集评估模型
在随机选取的样本上手动地测试模型
保存和加载模型检查点以避免从头再训练
其中有很多地方可以试验,我建议你使用 Jupyter 的交互性质试试各种不同的参数。这里有一些想法:
试试更小或更大的验证集,看对模型有何影响。
试试改变学习率,看能否用更少的 epoch 实现同样的准确度。
试试改变批大小,看批大小过高或过低时会怎样。
修改 fit 函数,以跟踪在训练集上的整体损失和准确度,将其与验证损失/准确度比较一下。你能解释结果更高或更低的原因吗?
使用数据的一个小子集进行训练,看是否能达到相近的准确度?
试试为不同的数据集构建模型,比如 CIFAR10 或 CIFAR100 数据集。
下面是一些进一步阅读的参考资料:
想学习相关的数学知识?参考 Coursera 上的机器学习课程:https://www.coursera.org/lecture/machine-learning/classification-wlPeP。本系列教程使用的大部分图像都取自该教程。
本笔记中定义的训练循环的灵感来自 FastAI 开发笔记:https://github.com/fastai/fastai_docs/blob/master/dev_nb/001a_nn_basics.ipynb,其中包含丰富的其它有用的知识(如果你能阅读和理解代码)。
深入理解 softmax和交叉熵,请参阅 DeepNotes 上的这篇博客:https://deepnotes.io/softmax-crossentropy。
想知道验证集为何很重要以及如何创建一个好验证集吗?参阅 FastAI 的 RachelThomas 的这篇博客:https://www.fast.ai/2017/11/13/validation-sets。
原文链接:https://medium.com/jovian-io/image-classification-using-logistic-regression-in-pytorch-ebb96cc9eb79
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于PyTorch进阶之路:使用logistic回归实现图像分类的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch学习5《PyTorch深度学习实践》——逻辑回归[对数几率回归](Logistic Regression)
pytorch学习笔记:逻辑斯蒂回归(Logistic Regression)