PyTorch踩过的坑
Posted CVer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch踩过的坑相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
https://zhuanlan.zhihu.com/p/59271905
本文已授权,未经允许,不得二次转载
1. nn.Module.cuda() 和 Tensor.cuda() 的作用效果差异
无论是对于模型还是数据,cuda()函数都能实现从CPU到GPU的内存迁移,但是他们的作用效果有所不同。
对于nn.Module:
model = model.cuda()
model.cuda()上面两句能够达到一样的效果,即对model自身进行的内存迁移。
对于Tensor:
和nn.Module不同,调用tensor.cuda()只是返回这个tensor对象在GPU内存上的拷贝,而不会对自身进行改变。因此必须对tensor进行重新赋值,即tensor=tensor.cuda().
例子:
model = create_a_model()
tensor = torch.zeros([2,3,10,10])
model.cuda()
tensor.cuda()
model(tensor) # 会报错
tensor = tensor.cuda()
model(tensor) # 正常运行2. PyTorch 0.4 计算累积损失的不同
以广泛使用的模式total_loss += loss.data[0]为例。Python0.4.0之前,loss是一个封装了(1,)张量的Variable,但Python0.4.0的loss现在是一个零维的标量。对标量进行索引是没有意义的(似乎会报 invalid index to scalar variable 的错误)。使用loss.item()可以从标量中获取Python数字。所以改为:
total_loss += loss.item()如果在累加损失时未将其转换为Python数字,则可能出现程序内存使用量增加的情况。这是因为上面表达式的右侧原本是一个Python浮点数,而它现在是一个零维张量。因此,总损失累加了张量和它们的梯度历史,这可能会产生很大的autograd 图,耗费内存和计算资源。
4. torch.Tensor.detach()的使用
detach()的官方说明如下:
Returns a new Tensor, detached from the current graph. The result will never require gradient.
假设有模型A和模型B,我们需要将A的输出作为B的输入,但训练时我们只训练模型B. 那么可以这样做:
input_B = output_A.detach()它可以使两个计算图的梯度传递断开,从而实现我们所需的功能。
5. ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)
出现这个错误的情况是,在服务器上的docker中运行训练代码时,batch size设置得过大,shared memory不够(因为docker限制了shm).解决方法是,将Dataloader的num_workers设置为0.
6. pytorch中loss函数的参数设置
以CrossEntropyLoss为例:
CrossEntropyLoss(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')若 reduce = False,那么 size_average 参数失效,直接返回向量形式的 loss,即batch中每个元素对应的loss.
若 reduce = True,那么 loss 返回的是标量:
如果 size_average = True,返回 loss.mean().
如果 size_average = False,返回 loss.sum().
weight : 输入一个1D的权值向量,为各个类别的loss加权,如下公式所示:
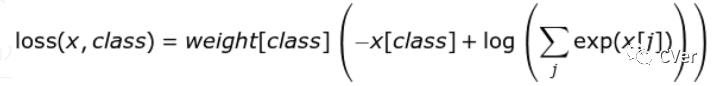
ignore_index : 选择要忽视的目标值,使其对输入梯度不作贡献。如果 size_average = True,那么只计算不被忽视的目标的loss的均值。
reduction : 可选的参数有:‘none’ | ‘elementwise_mean’ | ‘sum’, 正如参数的字面意思,不解释。
7. 在做一些metric learning时候,可能提高模型准确率的技巧
来源于知乎大佬的评论区:
背景:BFE-net 做reid时候backbone选择resnet50,但是没有进行warm-up 后准确率没有达到预期,大佬们的对话和解决方法:

找到作者git commit的记录:
if ep < 50:
lr = 1e-4*(ep//5+1)
elif ep < 200:
lr = 1e-3
elif ep < 300:
lr = 1e-4结论:在2月份新加了2行代码,简单来说就是在前50个epoch 用较低的learning rate 去预热,后面慢慢恢复正常的lr
8. 使用nn.Dataparallel 数据不在同一个gpu 上
背景:pytorch 多GPU训练主要是采用数据并行方式:
model = nn.DataParallel(model)问题:但是一次同事训练基于光流检测的实验时发现 data not in same cuda,做代码review时候,打印每个节点tensor,cuda里的数据竟然没有分布在同一个gpu上
解决:最终解决方案是在数据,吐出后统一进行执行.cuda()将数据归入到同一个cuda流中解决了该问题。
9.pytorch model load可能会踩到的坑:
如果使用了nn.Dataparallel 进行多卡训练在读入模型时候要注意加.module, 代码如下:
def get_model(self):
if self.nGPU == 1:
return self.model
else:
return self.model.module10.pytorch .h5 数据读入问题:
感谢来自评论区@Tio 同学的分享:
背景:我们知道Torch框架需要符合其自身规格的输入数据的格式,在图像识别中用到的是以.t7扩展名的文件类型,同时也有h5格式类型,这种类型的和t7差不多,均可被torch框架使用,但在读入时候有个官方BUG
问题:DataLoader, when num_worker >0, there is bug 读入.h5 数据格式时候如果dataloader>0 内存会占满,并报错
问题解决:
# 测试数据
f = h5py.File('test.h5')
for i in range(256):
f['%s/data' % i] = np.random.uniform(0, 1, (1024, 1024))
f['%s/target' % i] = np.random.choice(1000)解决:
# 错误发生
dataloader = torch.utils.data.DataLoader(
H5Dataset('test.h5'),
batch_size=32,
num_workers=8,
shuffle=True
)
# 解决,num_workers 改为0
dataloader = torch.utils.data.DataLoader(
H5Dataset('test.h5'),
batch_size=32,
num_workers=0,
shuffle=True
)CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID和GAN等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)
▲长按加群
这么硬的总结分享,麻烦给我一个在在看
麻烦给我一个在看!
以上是关于PyTorch踩过的坑的主要内容,如果未能解决你的问题,请参考以下文章