脸书AI首席开发布道师:如何贡献PyTorch代码
Posted 读芯术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了脸书AI首席开发布道师:如何贡献PyTorch代码相关的知识,希望对你有一定的参考价值。
全文共9175字,预计学习时长18分钟

本文作者是Facebook的机器学习/人工智能首席开发布道师,为其麾下的PyTorch团队助力,曾经是一名软件工程师。
值得注意的是,在之前,作者从未使用过PyTorch。他将用自己的亲身经历告诉你:PyTorch并不难学。

PyTorch内容集锦
PyTorch及其工作原理:
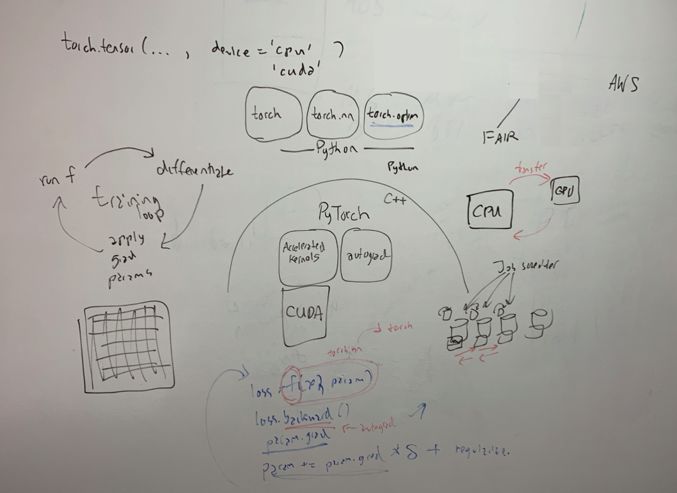
• PyTorch是Facebook开发的深度学习框架,用于快速灵活实验。这是一个基于Python的计算软件包,含有 C++后端API。
• PyTorch的Python前端有三个不同部分:
Torch
这是一个包含多维张量与数学运算的数据结构包。
Torch.nn
用于创建并训练神经网络。区域块的导入数据以张量形式传递。
例如:为处理图像而训练卷积神经网络时,可使用nn.conv2D模块(这一想法来自笔者同事塞斯)。
Torch.optim
该优化算法可训练神经网络。
例如:适用于初学者的SGD或适合进阶者的Adam等算法,都可训练神经网络(这个好例子也源自塞斯)。
Tensors(张量)
PyTorch的Tensors 与Numpy数组类似。不同之处在于,Tensors数据可以是单个数字,或一维矩阵(向量),或囊括各种数据的多维结构。
算梯度即求导(没错,机器学习即微积分)。求出张量的梯度,便可最大程度地规避错误。
梯度下降这一算法能有效实现错误最小化。错误由数据决定,而数据的分类也有适当与不适当之别。
通过梯度降低不当分类项目数。
张量最重要的特点即自动跟踪梯度。每个张量中的数据代表神经网路的连接层。这其中,有三点值得一提:
• 阶 (rank): 确定张量的维数。例如,向量为一阶。
• 形状 (shape): 行数和列数,表现形式为tensor. Size ([x]).
• 数据类型 (type): 给张量元素所指定的数据类型。
PyTorch的神经网络训练循环如下:确定目标函数、迭代输入其他数据、将数据运用于神经网络、执行梯度操作减少误差,将异常参数运用于神经网络。
在神经网络中重复迭代整个训练数据集即可。
C++ 后端
C++“后端”有五个不同部分。
• Autograd: 自动求导,即张量上的记录操作,进而生成自动求导图,基本上依据梯度张量求导。
• ATen: 张量及数学运算库。
• TorchScript: 连接TorchScript的JIT编译器与解释器的界面(JIT为“即时”)
• C++前端: 训练与评价机器学习模型的高级构造。
• C++ 扩展: 通过自定义C++与CUDA的例程扩展,扩展Python的API.
CUDA (计算机统一设备架构) 是由Nvidia推出的并行计算架构及应用程序界面 (API) 模型。
上述内容皆援引自维基百科,总的来说,CUDA常用于GPU上的各项操作。
GPU即图像处理器。可将其视为具有强大运算力的电脑。
“说好的概览呢?这些知识点简直让人摸不着头脑。”虽然上述内容的确晦涩难懂,但它们至关重要。
若想对相关知识有深入全面的了解,请参阅优达课程(https://classroom.udacity.com/courses/ud188)并阅读PyTorch docs(https://pytorch.org/docs/stable/index.html)这份资料,必能让你获益匪浅。
那份资料并不着眼于PyTorch的方方面面,而是帮助读者开始给GitPyTorch开源数据库贡献代码(https://github.com/pytorch/pytorch)。
在这份repo中,你可根据上述信息,自行推断大量所含文件夹的内容。
搭建开发环境
贡献任何代码之前,务必阅读CONTRIBUTING.md这份文档(https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md),切勿有所遗漏。这是笔者从血泪中总结出的教训。
若条件允许,无论是处理Python还是C++问题,最好都借助GPU。
还可采用其他途径(如AWS DLAMI或Nvidia Docker),这会显著提升运行速度。
作为初学者,笔者犯下的第一个错误就是在本地电脑上开工。由于本地电脑性能不够强大,各种令人困惑头疼的段错误也就层出不穷。
最终,笔者用SSH、MOSH、TMUX等登陆GPU服务器,效果极佳。如果想就此做好准备,可参阅以下博文:
• HPC上的GPU运算简介:安装GPU与SSH
https://sydney-informatics-hub.github.io/training.artemis.gpu/setup.html
• PyTorch必备——GPU
https://discuss.pytorch.org/t/solved-make-sure-that-pytorch-using-gpu-to-compute/4870
• GPU内存须知
https://discuss.pytorch.org/t/reserving-gpu-memory/25297
• 安装PyTorch与Tensorflow—— 采用支持CUDA的GPU
https://medium.com/datadriveninvestor/installing-pytorch-and-tensorflow-with-cuda-enabled-gpu-f747e6924779
接下来,搭建PyTorch开发环境。想用SSH登陆GPU,须做好以下内务处理操作:
• 连接GitHub账号,确保在GPU创建SSH密钥,并将其添加至GitHub账号。
• 你的设备很可能会用到Python。须确保用的是Python 3。你很可能已经安装了 pip。如若不然,务必全部安装。
• 安装Miniconda. 这和pip极为类似。官方网站并没有很好的终端安装指南,在此列出笔者的操作方式:
$ with-proxy wget “https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh"$ chmod +x Miniconda-latest-Linux-x86_64.sh$ bash Miniconda3-latest-MacOSX-x86_64.sh
• 重启终端,输入conda,确保操作无误。
• 运行conda config — set auto_activate_base false, 以防止Conda自动激活,不然会干扰机器的运作。
• 运行 conda activate,激活Conda。每次开发前,务必保证conda处于激活态,注意终端的(base)语句即可。
• 安装 ccache。如果无效,在启用conda的情况下执行 conda install ccachewhen conda。若依然无效,请尝试wget。"https://www.samba.org/ftp/ccache/ccache-3.3.3.tar.gz".
• 输入ccache 确保一切奏效,输入conda list确保其出现在安装列表。
• 安装一个faster linker。除非万不得已,不然请勿输入 ln -s /path/to/downloaded/ld.lld /usr/local/bin/ld 指令。笔者曾遇到这种情况,由于它们作用不大,最终还得将相关文档全部删除。
• 运行 pip install ghstack 或 conda install ghstack.
• 运行 pip install ninja 或 conda install ninja.
• 通过pip install flake8 flake8-mypy flake8-bugbear flake8-comprehensions flake8-executable flake8-pyi mccabe pycodestyle pyflakes安装 Flake8,它会为你纠错。若想给文档纠错 (lint),输入 flake8 <FILENAME> 即可。
• 安装一个IDE,通过SSH登陆GPU。笔者在Atom. 上查找remote-ssh ,即可得到相关操作说明。
• 最后,安装PyTorch:
$ git clone https://github.com/pytorch/pytorch$ cd pytorch$ git pull --rebase$ git submodule sync — recursive$ git submodule update — init — recursive$ python setup.py develop
python setup.py develop 就是用来编写PyTorch代码的工具。一开始会花些工夫,但一旦写过一次,以后就能使用不少加速方法。
编辑C++时需要构建PyTorch,但编辑Python时则不然。
想把这一系列步骤办好,就得斗志昂扬,心怀热忱。不过一旦完成这不易的任务,你就可以长舒一口气,好好犒赏下自己。
如果碰壁,不要恐慌,笔者也有过类似的经历。参照后文的《常见错误》,或在评论区留言,笔者必竭力相助。搭建好开发环境会花一番工夫,祝各位马到成功。
代码时间到!
开发环境搭建完毕,可以开始写代码了!
如果你之前从未贡献过开源代码,务必略读《行为准则》(https://github.com/pytorch/pytorch/blob/5bc7c1f83dd3ea740ba1d2af286c464862b90743/docs/source/community/governance.rst)。很多代码库都有这样的文档,简言之,做好人,行好事。
关注GitHub的问题 (issues) 选项卡。其中囊括很多社区成员提出的问题。点击训练营 (bootcamp) 标签,查看初学者级别的问题,选择自己能力范围内的任务,加以攻坚。
笔者建议,开始动手前,先阅读相关资料,洞悉个中玄机。还可更新过滤器 (filter) 查看训练营的历史纪录,研究已解决的问题。
如果你胸怀大志,大可点击 pull requests 标签。不是所有的PR都有相关的问题可供参考,有时研究问题本身更容易了解情况。
刚研究这些问题时,“冒牌货综合征”如乌云般笼罩在自己心头。“我又不是科班出身,怎么做得了这个?”打住!相信自己,你能行!
解决问题无须全知全能,找到方向,难题便迎刃而解。
如果你找到一个愿意动手解决的问题,要敢于留言并发问,哪怕是这样的一句话,“我想接下这个任务,请问你能就如何着手给我一些建议吗?”都大有裨益。
这些问题板块下的评论者都很乐于助人,因为如果有人对这些问题感兴趣,他们自己也会很高兴。对此笔者有切身体会,在他们的引导下,笔者解决了一系列问题,自己的PyTorch技术也日臻完善。
接下来是案例分析,阐述笔者如何在一头雾水的情况下解决问题。
第17893号问题:确保Grad_outputs的输出值形状与torch.autograd.grad()一致
幸运的是,据笔者切身经验来说,PyTorch库的作者往往细致缜密,言之有物。
就此例:https://github.com/pytorch/pytorch/issues/17893而言,结合前文的知识,不难发现,由于该问题涉及“接受输入”,所以这必定与Python前端有关。
乍一看这个问题角度很刁钻,虽然本质上与Python相关,但题目中的autograd,却有将人引向C++之嫌。
笔者创建一个新分支并将其导至最高级的torch文件夹(本例中,所涉及的函数正是torch)。
有趣的是,在最早创立的文件夹中,正好有一个名为autograd ,真可谓无巧不成书。
打开 autograd 文件夹,在 grad( 语句中调用git grep ,以确定函数定义。可以确定,其中一个就在 __init__.py 文件中。
更巧的是,在 grad 函数,中 正好有以 *gasp*为名的变量,也就是说只需要做一个简单的condition,一切便迎刃而解。
如题所示, outputs 与 grad_outputs 须形状一致。通过NumPy,有一个简单的法子可以做到这点。
import numpy as np...if np.shape(outputs) != np.shape(grad_outputs):
raise RuntimeError("grad_outputs and outputs do not have the same shape")
作为一名优秀的软件工程师,笔者很清楚只有先测试代码,才能保证自己的PR滴水不漏。不过首先,得确认程序的兼容性没有问题。
据CONTRIBUTING.md 文件所示, 先得运行 python test/run_test.py。
运行结果并不尽如人意,那么究竟是哪里出了纰漏?原来PyTorch在调用NumPy并不直接照搬,而是会做出相应调整。只能这样说,PyTorch可以无损调用NumPy中的函数。在这篇文章(https://github.com/wkentaro/pytorch-for-numpy-users)中,笔者获悉如何实现两种程序的代码转化。
此外,这篇文章中还提到,只能在一个(而非多个)张量中读取形状需求,因此笔者调用shape() 语句时也出了差错。因此,__init__.py 中 grad() 函数代码也须修改,详情如下:
再次测试程序,这次终于成功,接下来是报错测试。
打开test 文件夹,里面是带有test_grad 函数的 test_autograd.py 文件,一切都是那么的简洁明了!
在敲定测试方案前,笔者先加入一些打印语句。谨记,打印语句是Python编程师的鼎力助手。
打印随机变量有助于深入了解张量,并从程序上将其与梯度张量相比较。
此外,读取其他测试,了解项目中相关对象的创建与测试,也能令人获益匪浅。最终,测试如下:
grad_out = torch.ones(2)try:
torch.autograd.grad(
outputs=[grad_sum], grad_outputs=[grad_out],
inputs=[x], create_graph=True)
self.assertFail()
except RuntimeError as error:
self.assertEqual(str(error), "grad_outputs and outputs do not have the same shape")
运行上述测试,万无一失。接下来,用Flake8纠错,在GitHub上提交修改结果,创建PR,添加问题标签,确认与原问题标签一致,提交,搞定收工!
很快,笔者就收到了评论,这些意见逻辑清晰、颇有洞见,因此也极易落实。
第一桩PR圆满完成!幸好只用Python就可解决,毕竟,又有谁敢去编辑臭名昭著的C++呢?不过明知山有虎,偏向虎山行,有请下一个问题!
第22963号问题: 通过Torch.flatten(),输入零维张量,得出零维张量(非一维)
起初,笔者并未意识到该问题涉及C++API, 但仔细一看(再次给出题者点个赞),一切不言而喻。
切勿一见讨论而萌生退意,围绕这些问题的讨论往往蕴含很多信息。在接手问题之前,要确保自己有解决的方法。
该问题涉及两方面,一是“返回值”,二是“输入值”。输入值与“前端”相关,即Python;而“输出值”与“后端”相关,即C++。
创建新分支,大胆一试。大部分编程都是这么一回事——怀揣希望,放手一试。
首先,探寻 flatten() 函数的奥秘。而这便是打印语句的用武之地。
导航回 test 文件夹, 在flatten( 上调用git grep 。经过一番查询,笔者恰好在test_torch.py文件找到test_flatten 函数。
打开文件,研究其断言,明白自己所找何物后,输入如下打印语句:
# Test that flatten returns 1-dim tensor when given a 0-dim tensor
zero_dim_tensor = torch.tensor(123)
one_dim_tensor = torch.tensor([123])
cool_dim_tensor = torch.tensor([1,2,3])
flat0 = zero_dim_tensor.flatten()
flat1 = one_dim_tensor.flatten()
flat2 = cool_dim_tensor.flatten()print("--zero dim tensor--")
print(zero_dim_tensor)
print(zero_dim_tensor.shape)
print(flat0)
print(flat0.shape)
print("--one dim tensor--")
print(one_dim_tensor)
print(one_dim_tensor.shape)
print(flat1)
print(flat1.shape)
print("--cool dim tensor--")
print(cool_dim_tensor)
print(cool_dim_tensor.shape)
print(flat2)
print(flat2.shape)
输出值如下:
--zero dim tensor--
tensor(123)
torch.Size([])
tensor(123)
torch.Size([])
--one dim tensor--
tensor([123])
torch.Size([1])
tensor([123])
torch.Size([1])
—cool dim tensor--
tensor([1, 2, 3])
torch.Size([3])
tensor([1, 2, 3])
torch.Size([3])
结果与问题相吻合。展开后,零维张量与一维张量是等值的。
根据这些打印语句可得,这个等值性是由其形状(shape)为torch.Size([1])决定的。一经展开,零维向量等于一维向量。
接下来在代码中验证这一观点。笔者在GitHub库中搜索“flatten”的实例。在Python中,的确有Flatten模块这一说法。
由此,笔者第一次意识到自己得处理C++编程,一般来说人们不愿从事模块编辑,而这其中另有玄机。
有这么一种模块框架,名为 caffe2。你大可谷歌百度,简言之,它是PyTorch的一部分,并且人们往往不赞成使用这一框架。对笔者来说,编辑Caffe2不是个好主意。
无奈地盯着tensor_flatten.cpp文件,笔者似乎只能止步于此。这可是让人头疼的C++,就算费上九牛二虎之力,恐怕到头来自己仍一筹莫展。
鼓起勇气求助之前,笔者对着屏幕足足懊丧了一个小时,“冒牌者综合征”如阴云般在脑海中挥之不去。
干坐着泄气可不是理想的应对之策。如果不是坐在办公室,笔者恐怕早就发帖询问该从哪里下手了。所幸的是,办公桌几步之外,便是好心的工程师同伴。谢天谢地,在他们的点拨下,阴云散去,柳暗花明。
解决这一难题的关键在于aten. 因为 ATen 即张量运算库,而flatten 与运算息息相关。
明白这个道理需要花一番工夫。如果你因无处解惑而一筹莫展,可参阅PyTorch技术文档(https://pytorch.org/docs/stable/torch.html?highlight=flatten#torch.flatten)。
这表明,想解决这个问题,须找到带有各种参数(如input, start_dum, end_dim)的flatten 函数,返回一个Tensor 。根据这个说法,很明显之前笔者的尝试有如南辕北辙。
笔者决定在顶层调用 git grep,实现Tensor flatten( 。于是顺理成章地得到atn, TensorShape.cpp。这代码看上去没问题,准没错。
为了彻底理解该代码,笔者审阅了数遍,并确保单步执行的函数符合逻辑。
这代码看起来如何?简洁易懂!这样每当输入一维张量时,它就会模仿flatten 函数,而非返回输入值:
if (self.dim() == 0) {
shape.reserve(1);
shape.push_back(1);
return self.reshape(shape);
}
更新测试,代入合适的结果,然后一切水到渠成。接下来就是纠错,做PR,获取建议反馈,贡献PyTorch代码大功告成!
点滴感悟
笔者贡献开源代码已有些时日,以下几点经验教训值得牢记:
1. 勇于探索 不要对代码心生畏惧。这些代码都是聪明人写出来的(对于大项目来说更是如此),其中蕴含许多玄机可供探索。勇于揭开那些代码的神秘面纱,哪怕不准备为其添砖加瓦,仅仅是了解其工作原理,也能使自己获益匪浅。
2. 勤于发问 不必害羞瑟缩,GitHub开源社区倡导共享精神,主张领导力培养。别人会因为你的发问与参与心潮澎湃,进而伸出援助之手。
3. 乐于学习 你并不是团队中的冒牌者,只要自己乐于学习敢于拼搏,哪怕不是科班出身,不能做到凡事心领神会,你依然可以为团队发展添砖加瓦。
4. 善于钻研 多读资料。查阅README,技术文档,参与论坛,这些都能让人受益颇多。
5. 敢于尝试 哪怕自己不是稳操胜券,想不出万全之策,也不要踌躇不前,要敢于尝试。
望诸位的编程之路一帆风顺!
常见错误一览
Import not found, or import not connecting
1. 确认是否键入输入值。
2. 确认conda 是否激活。
3. 重启PyTorch。
NumPy functions don’t work
1. 先确认能否在不影响效果的情况下,用 PyTorch 替换Numpy。
2. 如若不然,在GitHub上创建问题,征求PyTorch可兼容的函数来达到预期效果。亦可自己写出函数。
Not all the tests on my PR are passing
1. 别气馁,深呼吸,相信自己。
2. 有时,这不是你的错。检查日志文件,留意是否有来自本机的新消息,若收到新消息,重新访问代码。
3. 你并未合并自己的PR,但团队其他成员合并了各自的PR。不过你有个好团队,伙伴们会告知你并为你分忧。

推荐阅读专题
我们一起分享AI学习与发展的干货
编译组:董宇阳、张婷华
相关链接:
推荐文章阅读
读芯君爱你
以上是关于脸书AI首席开发布道师:如何贡献PyTorch代码的主要内容,如果未能解决你的问题,请参考以下文章