视频识别怎样理解?其实,我们可以将其可视化!
Posted 雷克世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频识别怎样理解?其实,我们可以将其可视化!相关的知识,希望对你有一定的参考价值。

图:pixabay
原文来源:https://raghavgoyal14.github.io/blog/
「机器人圈」编译:嗯~阿童木呀、多啦A亮
 本文主要描述的是为视频识别设计的深层网络的显著图(saliency maps)。从早前的论文《卷积神经网络的可视化》(European conference on computer vision. Springer, Cham, 2014)、《可识别定位的深度特征学习》(In CVPR, 2016),以及《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》(arXiv preprint arXiv:1610.02391 (2016). In ICCV 2017)可以看出,显著图能够有助于可视化模型之所以产生给定预测的原因,发现数据中的假象,并指向一个更好的架构。
本文主要描述的是为视频识别设计的深层网络的显著图(saliency maps)。从早前的论文《卷积神经网络的可视化》(European conference on computer vision. Springer, Cham, 2014)、《可识别定位的深度特征学习》(In CVPR, 2016),以及《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》(arXiv preprint arXiv:1610.02391 (2016). In ICCV 2017)可以看出,显著图能够有助于可视化模型之所以产生给定预测的原因,发现数据中的假象,并指向一个更好的架构。
任务
从最近发布的的视频中识别人类行为,这需要对Goyal等人所著的《用于学习和评估视觉常识的“something something”视频数据库》中的概念进行细致理解。被称为“Something-Something”的数据集包含了174个类别的100000个视频,其中涵盖了一些诸如掉落、拾起和推之类的概念。
数据集中的几个样本示例

将[something]捡起来

假装将[something]放到[something]上

推动[something],使其从桌子上脱落

将[something]放入[something]中
可视化技术Grad-CAM
Selvaraju等人在《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》(arXiv:1610.02391 (2016). In ICCV 2017)提出的Grad-CAM或梯度加权类激活映射,使我们能够获得任何目标类的定位映射。它涉及,
•计算类logit w.r.t.的梯度,从而得到与最终卷积层相对应的激活图。
•通过使用梯度作为权重,计算对这些激活图的加权平均值。
•最后,应用ReLU函数突出显示与所选类相关的区域。
•将所得到的结果以热图(粗糙的定位地图)的形式投影到输入空间。
请参阅Selvaraju等人所著的《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》(链接:)了解更多详情。
架构详情
对于视频而言,我们一般选择将视频视为一系列图像帧,并在时域上扩展2D-CNN滤镜以获得3D-CNN,D. Tran等人在《用3D卷积网络学习时空特征》(ICCV 2015)和Carreira等人在《Quo Vadis,行动识别?一个新模型和动力学数据集》(arXiv:1705.07750)中,皆证明此方法非常适用于视频识别任务。我们按照《Quo Vadis,行动识别?一个新模型和动力学数据集》中所使用的用于完成Inception-v1中类似工作的方法,对ImageNet中预训练的ResNet-50过滤器在时间域内进行填充,并在数据集对生成模型进行训练,选择了《用于学习和评估视觉常识的“something something”视频数据库》中所描述的一个含有40个类的子集。
最终卷积层的激活维度为16x2048x7x7,输入维度为16x3x224x224,遵循(图像帧数x 信道数 x 宽度 x 高度)的约定。我们在时域内选择了一个大小为3,且padding和步幅为1的统一内核。这导致激活图具有与输入相同的时间维度,但在时间上非相关。
这个含有40个类别的数据子集中总共包含53267个样本,其中按照《用于学习和评估视觉常识的“something something”视频数据库》中所提及的8:1:1比例进行分割。上述架构的测试精度为51.1%,这要比本文所报告的36.2%要好15%左右。
时态定位图
使用上述训练模型,我们采用了一些随机样本,并按照《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》和相关代码资源(下载链接)中所提及的使用Grad-CAM对其进行可视化。数据以4fps采样,并且剪辑大小为16帧(见上文),这些视频最多显示4秒的动作。
下面的样本示例显示了原始视频以及它的热图叠加版本(红色)。此外,每个样本下面都显示了真正的结果和前2个预测结果。
一些正案例:(左侧为原图,右侧为热图版本)

真实:放[something]
预测:1. 放 [something] :– 0.84;2. 扔掉[something] :– 0.10

真实:撕裂[something]
预测:1.撕裂[something]:- 0.99;2.将多个[something]进行堆叠:- 0.00

真实:揭开[something]
预测:1.揭开[something]:–0.99; 2.打开[something]:–0.00
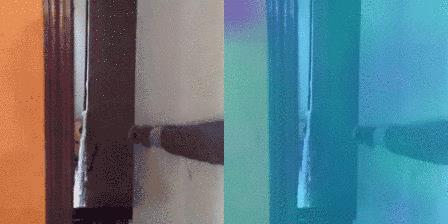
真实:关上[something]
预测:1.关上[something]:–0.96;2.打开[something]:–0.02

真实:推动[something]使其轻微移动
预测:1. 推动[something]使其轻微移动:–0.43; 2.假装将[something]从[somewhere]拿出:–0.20

真实:拿着相机接近[something]
预测:1.拿着相机接近[something]:-0.26;2.扔掉[[something]:-0.15

真实:将[something]捡起
预测:1.将[something]捡起:–0.99;2.放置[something]:–0.00
一些中性案例:(左侧为原图,右侧为热图版本)

真实:将[something]捡起
预测:1. 在拍摄[something]时向下转动相机:–0.67;2. 将[something]捡起:–0.10

真实:握住[something]
预测:1.在拍摄[something]时向左转动相机:–0.21;2.在拍摄[something]时向右转动相机:–0.21

真实:将[something]扔到[something]上
预测:1.抛掷[something]:–0.97;2. 将[something]扔到[something]上:–0.01

真实:将[something]捡起
预测1.用[something]推动[something]:–0.34;2. 将[something]捡起:–0.25
一些负案例:(左侧为原图,右侧为热图版本)

真实:握住[something]
预测:1.将[something]倒置:–0.07;2. 在拍摄[something]时向左转动相机:–0.07

真实:推动[something]使其轻微移动
预测:1.扔掷[something]:–0.50;2. 将[something]捡起:–0.11

真实:握住[something]
预测:1.用[something]推动[something]:–0.19;2. 握住[something]:–0.15
讨论
仔细看,上述例子表明,在大多数情况下,随着时间推移该模型已经学会了关注感兴趣的对象,今后我们将继续跟踪这项工作。
在TwentyBN()上,借助我们专有的数据平台,我们正在收集描述世界上细粒度(fine-grained)概念的视频,目的是使人类从视觉上了解世界。最近,我们发布了两个大型视频数据集(256591个标签视频),我们相信我们在这方面的努力将有助于我们面临更多的挑战。
欢迎加入
关注“机器人圈”后不要忘记置顶哟
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册
以上是关于视频识别怎样理解?其实,我们可以将其可视化!的主要内容,如果未能解决你的问题,请参考以下文章