由表及里学 ProjectReactor 之上卷
Posted 原力注入
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由表及里学 ProjectReactor 之上卷相关的知识,希望对你有一定的参考价值。
暗中观察
默默关注
我们都知道 ProjectReactor 是借鉴 Rxjava 的,这个在android开发中一个极为重要的库,现在因为后端服务采用Netty,又在Reactive的东风之下,后端也选择采用 响应式编程模式 进行开发,响应式编程不是一个新概念,响应式编程就是用异步数据流进行编程,在传统的GUI应用中因为不能阻塞 绘图IO 所以有很多基于事件的编程模式,响应式编程提高了代码的抽象水平,因此能专注于那些定义业务逻辑的事件的依存关系,而无需摆弄大量的线程相关实现细节。
下文简称 projectreactor 为 PRR。

响应式编程
本质上的 响应式编程模式 就是一个 观察者模式。
为什么需要响应式编程
为什么需要响应式编程,在文档也明确的表示,简而言之就是,我们针对大量的并发用户,我们可以选择
并行化(parallelize):使用更多的线程和硬件资源
基于
现有的资源提高执行效率
第一种方式,往往采用分布式计算,在这里不做多展开。
第二种方式,通过编写 异步非阻塞 的代码,可以减少资源的浪费,在Java中一般采用,回调(Callbacks) 和 Futures ,但是这两种方式都有局限性,
回调很难组合起来,因为很快就会导致代码难以理解和维护(即所谓的“回调地狱(callback hell)”),
Futures 比回调要好一点,但即使在 Java 8 引入了 CompletableFuture,它对于多个处理的组合仍不够好用。 编排多个 Futures 是可行的,但却不易。此外,Future 还有一个问题:当对 Future 对象最终调用 get() 方法时,仍然会导致阻塞,并且缺乏对多个值以及更进一步对错误的处理。
关于原因的详细阅读
官方的例子
userService.getFavorites(userId) ➊
.flatMap(favoriteService::getDetails) ➋
.switchIfEmpty(suggestionService.getSuggestions()) ➌
.take(5) ➍
.publishOn(UiUtils.uiThreadScheduler()) ➎
.subscribe(uiList::show, UiUtils::errorPopup); ➏➊ 根据用户ID获得喜欢的信息(打开一个 Publisher)
➋ 使用 flatMap 操作获得详情信息
➌ 使用 switchIfEmpty 操作,在没有喜欢数据的情况下,采用系统推荐的方式获得
➍ 取前五个
➎ 在 uiThread 上进行发布
➏ 最终的消费行为
➊➋➌➍ 的行为就看起来很直观,这个和我们使用 Java 8 中的 Streams 编程 极为相近,但是这里实现和 Strem 是不同的,在后续的分析会展开。
➎ 和 ➏ 在我们之前的编码(注:传统后台服务)中没有遇见过类似的,这里的行为,我们可以在后续的 Reference#schedulers 中可以得知,publishOn 将影响后续的行为操作所在的线程,那我们就明白了,之前的操作会在某个线程中执行,而最后一个 subscribe() 函数将在 uiThread 中执行。
如果非常着急话可以先阅读 小结图文
SPI 模型定义
Publisher 即被观察者
Publisher 在 PRR 中 所承担的角色也就是传统的 观察者模式 中的 被观察者对象,在 PRR 的定义也极为简单。
package org.reactivestreams;
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}Publisher 的定义可以看出来,Publisher 接受 Subscriber,非常简单的一个接口。但是这里有个有趣的小细节,这个类所在的包是 org.reactivestreams,这里的做法和传统的 J2EE 标准类似,我们使用标准的 Javax 接口定义行为,不定义具体的实现。
Subscriber 即观察者
Subscriber 在 PRR 中 所承担的角色也就是传统的 观察者模式 中的 观察者对象,在 PRR 的定义要多一些。
public interface Subscriber<T> {
public void onSubscribe(Subscription s); ➊
public void onNext(T t); ➋
public void onError(Throwable t);
public void onComplete(); ➍
}➊ 订阅时被调用
➋ 每一个元素接受时被触发一次
➌ 当在触发错误的时候被调用
➍ 在接受完最后一个元素最终完成被调用
Subscriber 的定义可以看出来,Publisher 是主要的行为对象,用来描述我们最终的执行逻辑。
Subscription 桥接者
在最基础的 观察者模式 中,我们只是需要 Subscriber 观察者 Publisher 发布者,而在 PRR 中增加了一个 Subscription 作为 Subscriber Publisher 的桥接者。
public interface Subscription {
public void request(long n); ➊
public void cancel(); ➋
}➊ 获取 N 个元素往下传递
➋ 取消执行
为什么需要这个对象,笔者觉得是一是为了解耦合,第二在 Reference 中有提到 Backpressure 也就是下游可以保护自己不受上游大流量冲击,这个在 Stream 编程中是无法做到的,想要做到这个,就需要可以控制流速,那秘密看起来也就是在 request(long n) 中。
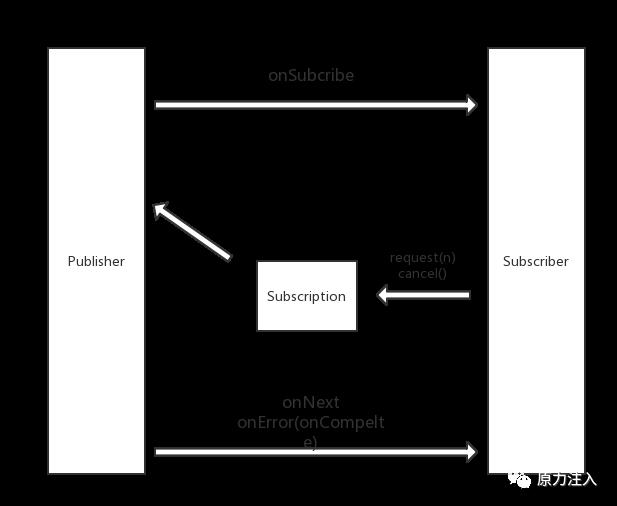
他们如何工作
我们尝试使用最简单的一个例子进行我们的 探险之旅
Flux.just("tom", "jack", "allen")
.map(s-> s.concat("@qq.com"))
.subscribe(System.out::println);我们仅仅是将 String 对象进行增加一个邮箱后缀,然后再打印出来,这是一个非常简单的逻辑。
声明阶段
//reactor.core.publisher.Flux#fromArray
public static <T> Flux<T> fromArray(T[] array) {
// 检查略
return onAssembly(new FluxArray<>(array));
}我们可以清晰的发现,PRR 只是将 array 包裹成了一个 FluxArray 对象,我们来看看它的声明。
final class FluxArray<T> extends Flux<T> implements Fuseable, Scannable {
final T[] array;
@SafeVarargs
public FluxArray(T... array) {
this.array = Objects.requireNonNull(array, "array");
}
}在具体的实例中,FluxArray 也仅仅是将 array 储存了起来,然后就返回回来了,那我们紧接着去看看 .map(s-> s.concat("@qq.com")) 又做了什么。
public final <V> Flux<V> map(Function<? super T, ? extends V> mapper) {
if (this instanceof Fuseable) {
return onAssembly(new FluxMapFuseable<>(this, mapper)); ➊
}
return onAssembly(new FluxMap<>(this, mapper)); ➋
}在 ➊ ➋ 处,我们发现都是简单的将这个 Function<T,V> 包装成一个新的 FluxMapFuseable/FluxMap 对象返回,但是我们可以看到在 FluxMap 的构造函数中需要2个值。
FluxMap(Flux<? extends T> source, Function<? super T, ? extends R> mapper) {
super(source);
this.mapper = Objects.requireNonNull(mapper, "mapper");
}想到了什么?这里和设计模式中的 代理模式 极为接近,我们每次将一个 操作 和 源Publisher 组合变成一个 新Publisher,到这里我们已经明白了在 subscribe() 之前,我们什么都没做,只是在不断的包裹 Publisher 将作为原始的 Publisher 一层又一层的返回回来。终于到了我们最为激动人心的 subscribe() 函数了。
subscribe 阶段
通过一顿 Jump Definition 大法,我们找到
//reactor.core.publisher.Flux#subscribe(reactor.core.CoreSubscriber<? super T>)
public abstract void subscribe(CoreSubscriber<? super T> actual);在 Flux 的 抽象类 中,这是一个抽象函数,也就是函数是需要子类中实现的,那我们在上面的分析过程中,我们知道每一次 Operator 都会包裹出一个新的 Flux,那我们去找到最后一次生成的 FluxMapFuseable 去看看它的实现。
@Override
@SuppressWarnings("unchecked")
public void subscribe(CoreSubscriber<? super R> actual) {
if (actual instanceof ConditionalSubscriber) {
ConditionalSubscriber<? super R> cs = (ConditionalSubscriber<? super R>) actual;
source.subscribe(new MapFuseableConditionalSubscriber<>(cs, mapper));
return;
}
source.subscribe(new MapFuseableSubscriber<>(actual, mapper));
}➊ 我们暂时不去关心处理 Fuseable 这个对象
➋ 我们自己的 Subscriber 在这里被包裹成一个 MapFuseableSubscriber 对象,又订阅 source,还记得 source 这个对象吗?我们当前所在的 this 对象是 FluxMapFuseable,而他的上一次的源头也就是我们的FluxArray 对象,这行我们就发现了 MapFuseableSubscriber 只是一个中间人,将我们的源头 FluxArray 和 我们自定义的 Subscriber 关联起来,通过将 Subscriber 包装成新的 MapFuseableSubscriber 的方式
那我们继续看看 FluxArray 是如何处理 subscribe() 函数的。
@SuppressWarnings("unchecked")
public static <T> void subscribe(CoreSubscriber<? super T> s, T[] array) {
if (array.length == 0) {
Operators.complete(s);
return;
}
if (s instanceof ConditionalSubscriber) {
s.onSubscribe(new ArrayConditionalSubscription<>((ConditionalSubscriber<? super T>) s, array)); ➊
}
else {
s.onSubscribe(new ArraySubscription<>(s, array)); ➋
}
}熟悉的味道,➊ ➋ 将 Subscriber 和 Publisher 包裹成一个 Subscription 对象,并将其 作为onSubscribe 函数调用的对象,这样的话,我们就可以完整的理解,为什么 Nothing Happens Until You subscribe() 因为实际上在我们调用 subscribe() 所有的方法都只是在申明对象。只有在 subscribe 之后才能出发 onSubscribe 调用。
那问题又来了 onSubscribe 又做了什么?那我们知道现在的这个 s 也就是 MapFuseableSubscriber 我们去看看它的 onSubscribe 实现就明白了。
onSubscribe 阶段
public void onSubscribe(Subscription s) {
if (Operators.validate(this.s, s)) {
this.s = (QueueSubscription<T>) s;
actual.onSubscribe(this);
}
}很简单,我们又获得了我们自己所定义的 Subscriber 并调用它的 onSubscribe 函数,因为我们采用 Lambda 的方式生成的 Subscriber 所以也就是 LambdaSubscriber 对象,在他的实现中是如此写到。
request 阶段
public final void onSubscribe(Subscription s) {
if (Operators.validate(subscription, s)) {
this.subscription = s;
if (subscriptionConsumer != null) {
try {
subscriptionConsumer.accept(s); ➊
}
catch (Throwable t) {
Exceptions.throwIfFatal(t);
s.cancel();
onError(t);
}
}
else {
s.request(Long.MAX_VALUE); ➋
}
}
}无论是 ➊ 还是 ➋ 最为核心的都是调用了 Subscription.request() 函数,还记这个 Subscription 吗?也就是我们上一步的 MapFuseableSubscriber
@Override
public void request(long n) {
s.request(n);
}这这里的S又是我们最外围的 FluxArray,我们继续查看下去。
public void request(long n) {
if (Operators.validate(n)) {
if (Operators.addCap(REQUESTED, this, n) == 0) {
if (n == Long.MAX_VALUE) {
fastPath(); ➊
}
else {
slowPath(n); ➋
}
}
}
}这里进行了一个简单的优化,我们直接去阅读 fastPath() 函数。
调用阶段
void fastPath() {
final T[] a = array;
final int len = a.length;
final Subscriber<? super T> s = actual;
for (int i = index; i != len; i++) { ➊
if (cancelled) { return; }
T t = a[i];
if (t == null) { /** skip **/}
s.onNext(t); ➋
}
/** skip **/
s.onComplete();
}这个函数非常的简单,核心也就是一个循环体 ➊,我们在 ➋ 看出我们最终处理单一元素的 onNext() 函数,而这个 s 对象是 FluxMapFuseable 对象,在它的 onNext() 中
@Override
public void onNext(T t) {
R v;
try {
v = Objects.requireNonNull(mapper.apply(t), "The mapper returned a null value."); ➊
}
catch (Throwable e) {//skip
}
actual.onNext(v); ➋
}在 ➊ 处进行 Mapper 变形
在 ➋ 将 变形之后的结构传递给下一个 Subscriber
这里的 actual 也就是我们的自己所写的 Subscriber
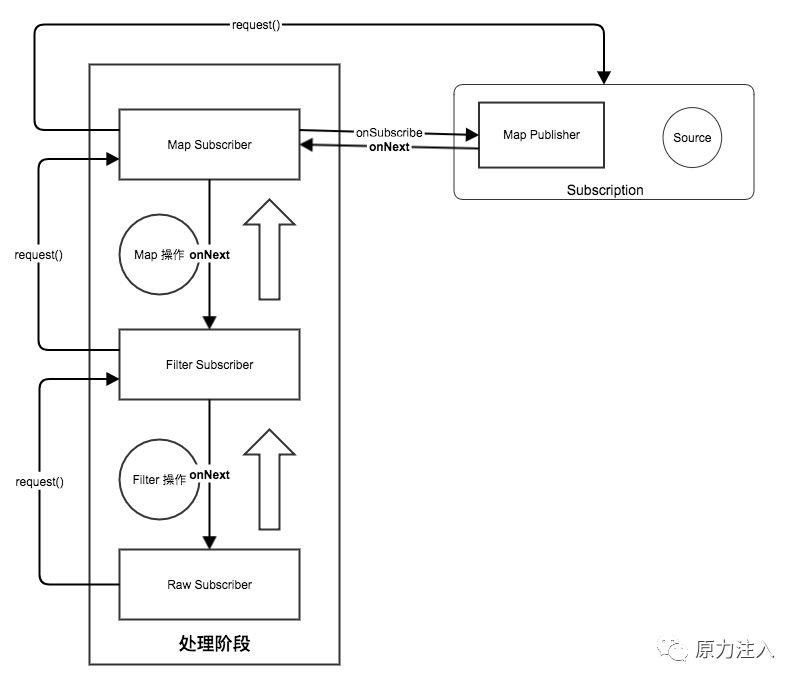
小结一下
1.声明阶段: 当我们每进行一次 Operator 操作 (也就 map filter flatmap),就会将原有的 FluxPublisher 包裹成一个新的 FluxPublisher
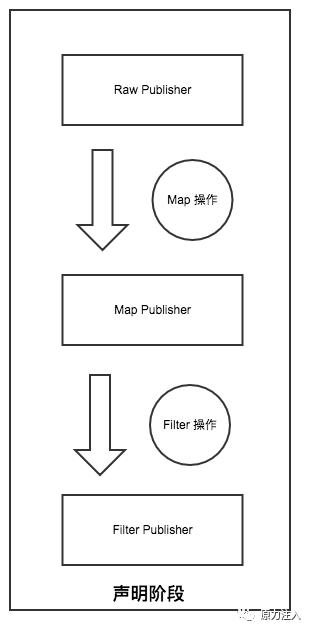
最后生成的对象是这样的
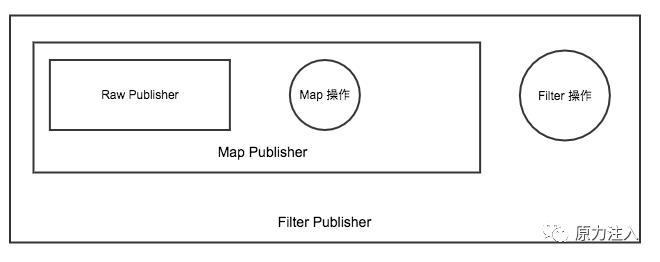
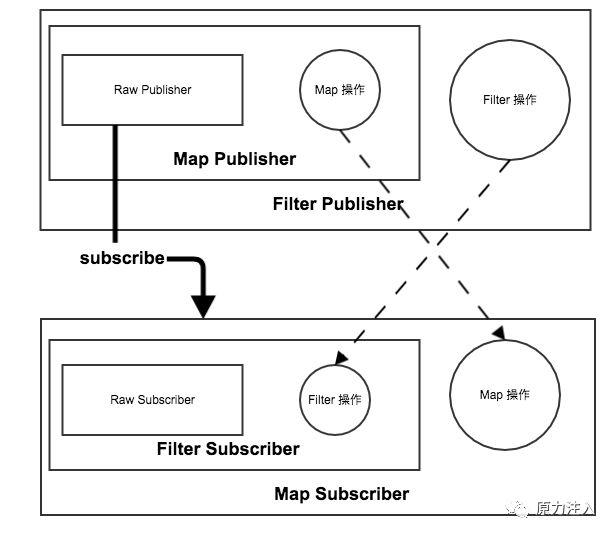
2.subscribe阶段: 当我们最终进行 subscribe 操作的时候,就会从最外层的 Publisher 一层一层的处理,从这层将 Subscriber 变化成需要的 Subscriber 直到最外层的 Publisher
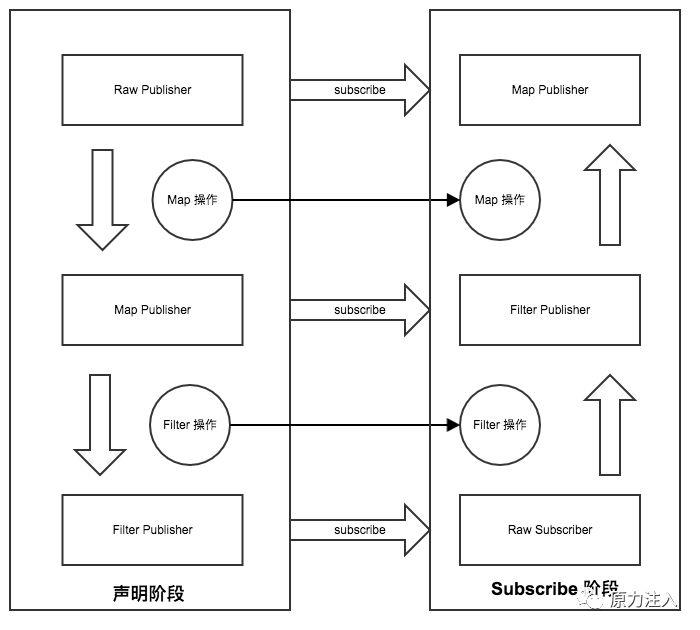
最后生成的对象是这样的
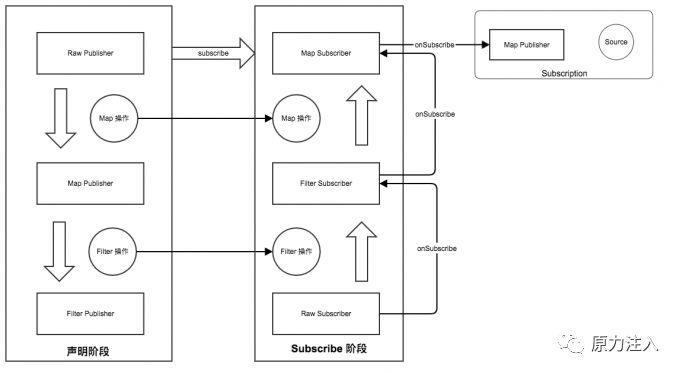
3.onSubscribe阶段: 在最外层的 Publisher 的时候调用 上一层 Subscriber 的 onSubscribe 函数,在此处将 Publisher 和 Subscriber 包裹成一个 Subscription 对象作为 onSubscribe 的入参数。
4.最终在 原始 Subscriber 对象调用 request() ,触发 Subscription 的 Source 获得数据作为 onNext 的参数,但是注意 Subscription 包裹的是我们封装的 Subscriber 所有的数据是从 MapSubscriber 进行一次转换再给我们的原始 Subscriber 的。
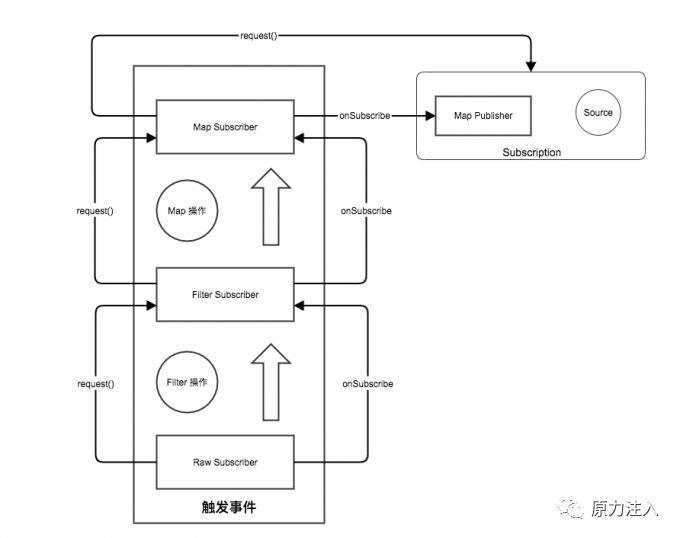
经过一顿分析,整个 PRR 是如何将操作整合起来的,我们已经有一个大致的了解,通过不断的包裹出新的 Subscriber 对象,在最终的 request() 行为中触发整个消息的处理,这个过程非常像 俄罗斯套娃,一层一层的将变化组合形变操作变成一个新的 Subscriber, 然后就和一个管道一样,一层一层的往下传递。
4.最终在 Subscription 开始了我们整个系统的数据处理
其他
读者在自行阅读代码的时候可以使用 Mono 进行分析,也会比较简单些,比如使用下面的代码:
Mono.just("tom")
.map(s -> s.concat("123"))
.filter(s -> s.length() > 5)
.subscribe(System.out::println);
下篇:线程切换 Schedulers
点击阅读原文,了解更多精彩内容
以上是关于由表及里学 ProjectReactor 之上卷的主要内容,如果未能解决你的问题,请参考以下文章
你不知道的Javascript(上卷)读书笔记之二 ---- 词法作用域