Dubbo序列化原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo序列化原理相关的知识,希望对你有一定的参考价值。
参考技术A Dubbo序列化的默认方式是Hessian2,对应到源码里面的类便是Hessian2Serialization在服务端,是在ExchangeCodec类中通过Hessian2Serialization来序列化或者反序列化数据
而在消费者端,除了通过ExchangeCodec类来序列化请求,还通过DecodeableRpcResult中的decode方法来反序列化请求结果
Dubbo 的 8000 字图文详解,建议收藏!
扫描下方海报 试读


“ 分布式应用场景有高并发,高可扩展和高性能的要求。还涉及到,序列化/反序列化,网络,多线程以及设计模式的问题。幸好 Dubbo 框架将上述知识进行了封装,让程序员能够把注意力放到业务上。
为了更好地了解和使用 Dubbo,今天来介绍一下 Dubbo 的主要组件和实现原理。
Dubbo 分层
Dubbo 是一款高性能 Java RPC 架构。它实现了面向接口代理的 RPC 调用,服务注册和发现,负载均衡,容错,扩展性等等功能。
Dubbo 大致上分为三层,分别是:
业务层
RPC 层
-
Remoting 层
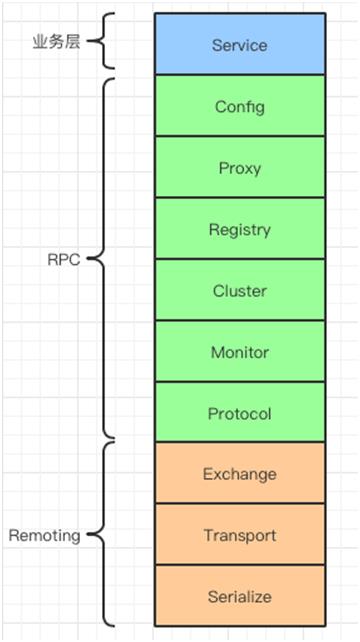
Dubbo 的三层结构
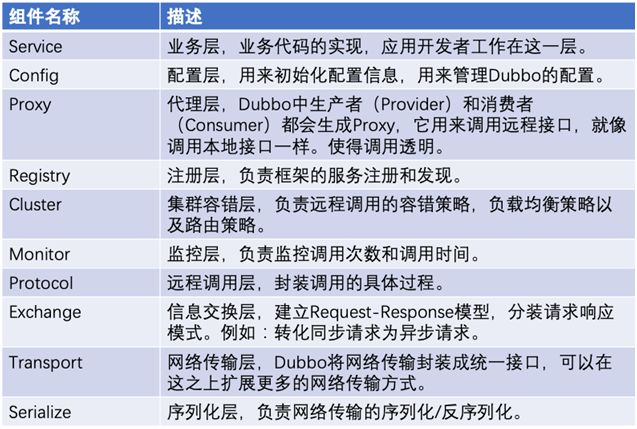
组件功能列表
这里将这些组件罗列出来,能有一个感性的认识。具体开发的时候,知道运用哪些组件。
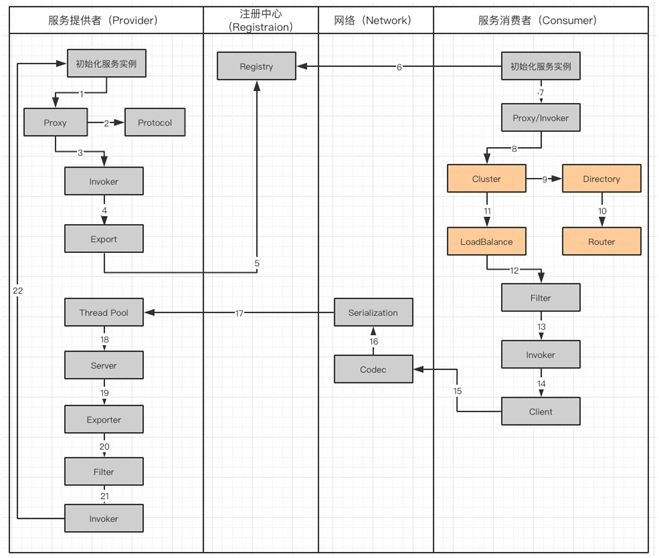
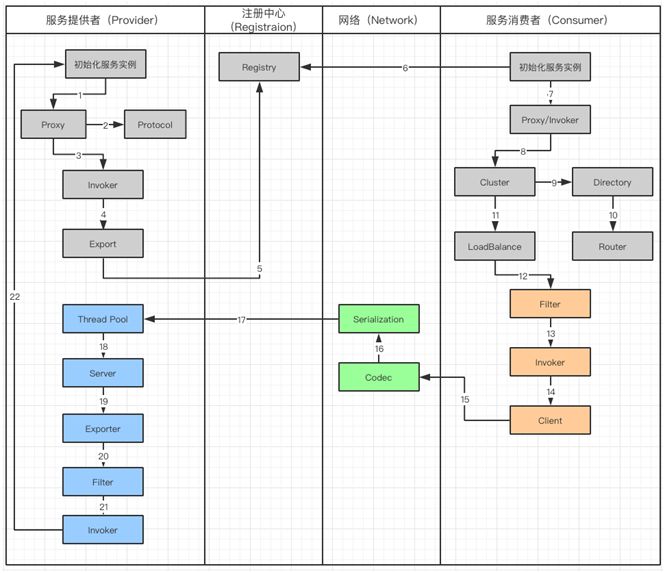
Dubbo 调用工作流
Dubbo 框架是用来处理分布式系统中,服务发现与注册以及调用问题的,并且管理调用过程。
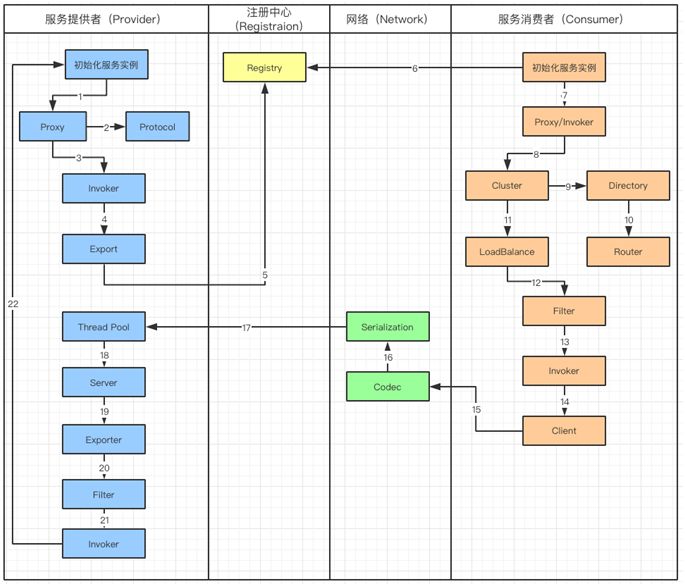
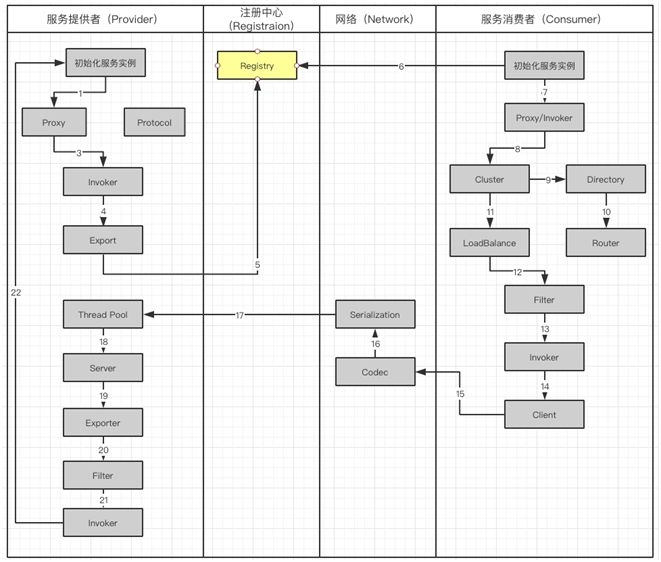
Dubbo 服务调用流程图
工作流涉及到服务提供者(Provider),注册中心(Registration),网络(Network)和服务消费者(Consumer):
服务提供者在启动的时候,会通过读取一些配置将服务实例化。
Proxy 封装服务调用接口,方便调用者调用。客户端获取 Proxy 时,可以像调用本地服务一样,调用远程服务。
Proxy 在封装时,需要调用 Protocol 定义协议格式,例如:Dubbo Protocol。
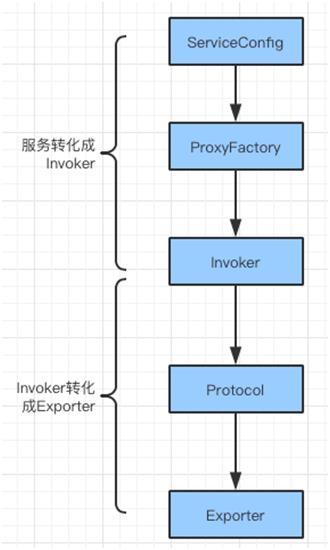
将 Proxy 封装成 Invoker,它是真实服务调用的实例。
将 Invoker 转化成 Exporter,Exporter 只是把 Invoker 包装了一层,是为了在注册中心中暴露自己,方便消费者使用。
将包装好的 Exporter 注册到注册中心。
服务消费者建立好实例,会到服务注册中心订阅服务提供者的元数据。元数据包括服务 IP 和端口以及调用方式(Proxy)。
消费者会通过获取的 Proxy 进行调用。通过服务提供方包装过程可以知道,Proxy 实际包装了 Invoker 实体,因此需要使用 Invoker 进行调用。
在 Invoker 调用之前,通过 Directory 获取服务提供者的 Invoker 列表。在分布式的服务中有可能出现同一个服务,分布在不同的节点上。
通过路由规则了解,服务需要从哪些节点获取。
Invoker 调用过程中,通过 Cluster 进行容错,如果遇到失败策略进行重试。
调用中,由于多个服务可能会分布到不同的节点,就要通过 LoadBalance 来实现负载均衡。
Invoker 调用之前还需要经过 Filter,它是一个过滤链,用来处理上下文,限流和计数的工作。
生成过滤以后的 Invoker。
用 Client 进行数据传输。
Codec 会根据 Protocol 定义的协议,进行协议的构造。
构造完成的数据,通过序列化 Serialization 传输给服务提供者。
Request 已经到达了服务提供者,它会被分配到线程池(ThreadPool)中进行处理。
Server 拿到请求以后查找对应的 Exporter(包含有 Invoker)。
由于 Export 也会被 Filter 层层包裹
通过 Filter 以后获得 Invoker
最后,对服务提供者实体进行调用。
服务暴露实现原理
上面讲到的服务调用流程中,开始服务提供者会进行初始化,将暴露给其他服务调用。服务消费者也需要初始化,并且在注册中心注册自己。
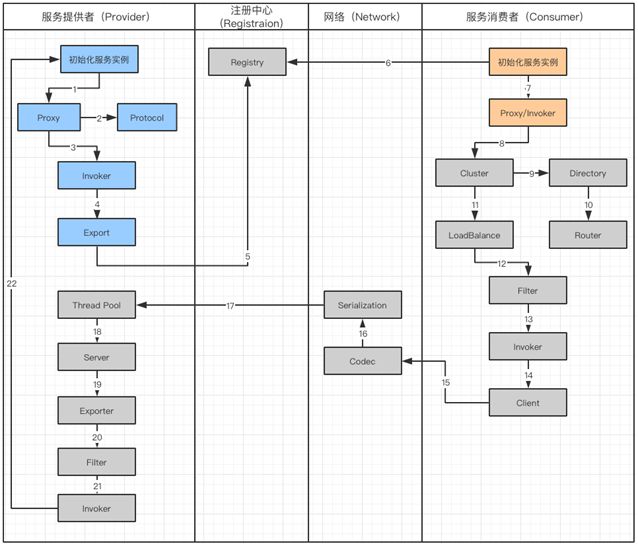
首先来看看服务提供者暴露服务的整体机制:
下面是针对多协议多注册中心进行源代码分析:
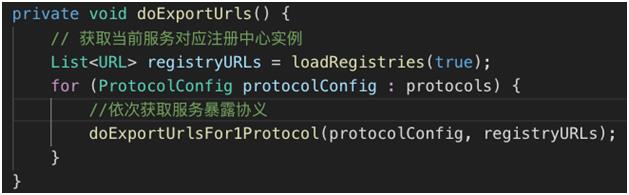
doExportUrls 方法
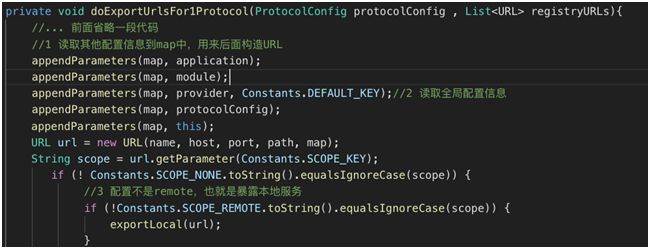
doExportUrlsFor1Protocol 方法-1
读取其他配置信息到 map 中,用来后面构造 URL。
读取全局配置信息。
配置不是 remote,也就是暴露本地服务。
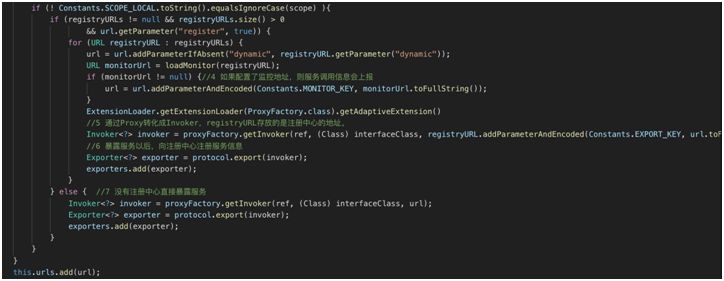
暴露服务以后,向注册中心注册服务信息。
没有注册中心直接暴露服务。
委托具体协议进行服务暴露,创建 NettyServer 监听端口,并保持服务实例。
创建注册中心对象,创建对应的 TCP 连接。
注册元数据到注册中心。
订阅 Configurators 节点。
如果需要销毁服务,需要关闭端口,注销服务信息。
说完了服务提供者的暴露再来看看服务消费者。
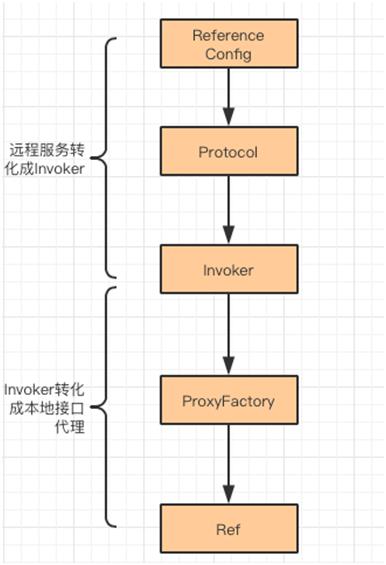
这里一起来看看 createProxy 的源代码:
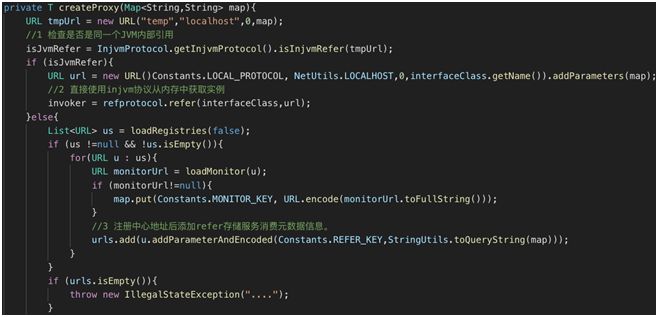
getProxy 代码片段 1
检查是否是同一个 JVM 内部引用。
如果是同一个 JVM 的引用,直接使用 injvm 协议从内存中获取实例。
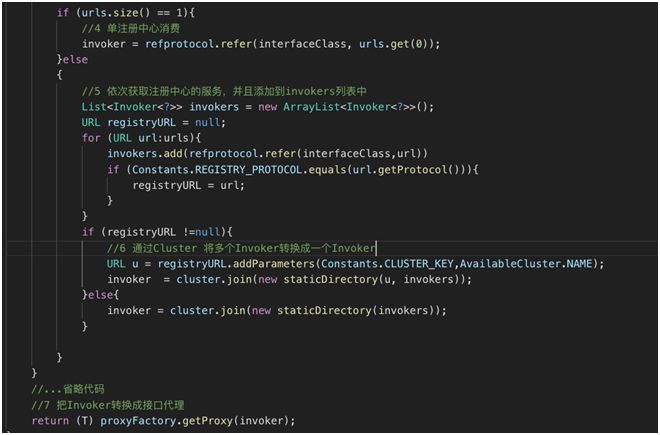
单注册中心消费。
依次获取注册中心的服务,并且添加到 Invokers 列表中。
通过 Cluster 将多个 Invoker 转换成一个 Invoker。
把 Invoker 转换成接口代理。
注册中心
说完服务暴露,再回头来看看注册中心。Dubbo 通过注册中心实现了分布式环境中服务的注册和发现。
动态载入服务。服务提供者通过注册中心,把自己暴露给消费者,无须消费者逐个更新配置文件。
动态发现服务。消费者动态感知新的配置,路由规则和新的服务提供者。
参数动态调整。支持参数的动态调整,新参数自动更新到所有服务节点。
服务统一配置。统一连接到注册中心的服务配置。
配置中心工作流
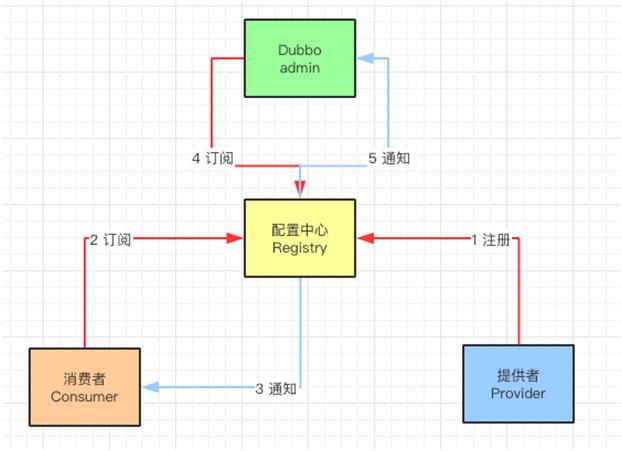
提供者(Provider)启动时,会向注册中心写入自己的元数据信息(调用方式)。
消费者(Consumer)启动时,也会在注册中心写入自己的元数据信息,并且订阅服务提供者,路由和配置元数据的信息。
服务治理中心(duubo-admin)启动时,会同时订阅所有消费者,提供者,路由和配置元数据的信息。
当提供者离开或者新提供者加入时,注册中心发现变化会通知消费者和服务治理中心。
注册中心工作原理
Providers 目录下面,存放服务提供者 URL 和元数据。
Consumers 目录下面,存放消费者的 URL 和元数据。
Routers 目录下面,存放消费者的路由策略。
Configurators 目录下面,存放多个用于服务提供者动态配置 URL 元数据信息。
Dubbo 集群容错
分布式服务多以集群形式出现,Dubbo 也不例外。在消费服务发起调用的时候,会涉及到 Cluster,Directory,Router,LoadBalance 几个核心组件。
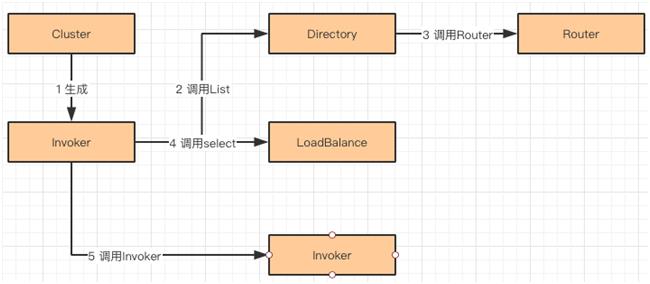
RegistryDirectory:属于动态 Directory 实现,会自动从注册中心更新 Invoker 列表,配置信息,路由列表。
StaticDirectory:它是 Directory 的静态列表实现,将传入的 Invoker 列表封装成静态的 Directory 对象。
同理,路由信息更新了,也会更新服务本地路由信息。如果 Invoker 的调用信息变更了(服务提供者调用信息),会根据具体情况更新本地的 Invoker 信息。
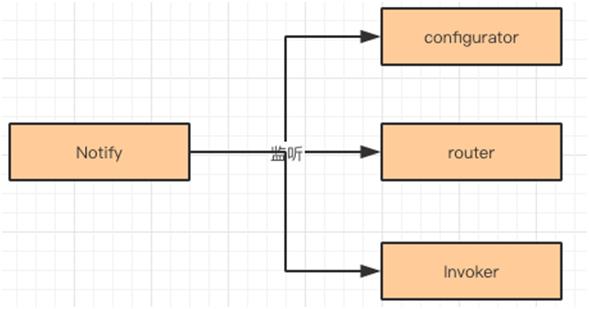
Random LoadBalance,随机,按照权重设置随机概率做负载均衡。
RoundRobinLoadBalance,轮询,按照公约后的权重设置轮询比例。
LeastActiveLoadBalance,按照活跃数调用,活跃度差的被调用的次数多。活跃度相同的 Invoker 进行随机调用。
ConsistentHashLoadBalance,一致性 Hash,相同参数的请求总是发到同一个提供者。
Failover,出现失败,立即重试其他服务器。可以设置重试次数。
Failfast,请求失败以后,返回异常结果,不进行重试。
Failsafe,出现异常,直接忽略。
Failback,请求失败后,将失败记录放到失败队列中,通过定时线程扫描该队列,并定时重试。
Forking,尝试调用多个相同的服务,其中任意一个服务返回,就立即返回结果。
Broadcast,广播调用所有可以连接的服务,任意一个服务返回错误,就任务调用失败。
Mock,响应失败时返回伪造的响应结果。
Available,通过遍历的方式查找所有服务列表,找到第一个可以返回结果的节点,并且返回结果。
Mergable,将多个节点请求合并进行返回。
Dubbo 远程调用
服务消费者经过容错,Invoker 列表,路由和负载均衡以后,会对 Invoker 进行过滤,之后通过 Client 编码,序列化发给服务提供者。
Dubbo 系统有自带的系统过滤器,服务提供者有 11 个,服务消费者有 5 个。过滤器的使用可以通过 @Activate 的注释,或者配置文件实现。
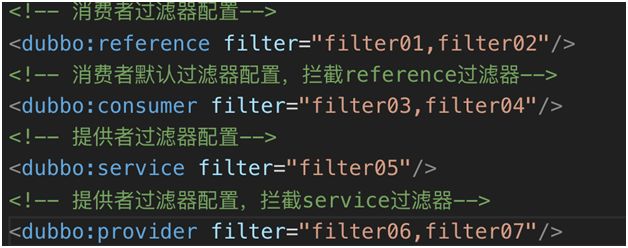
过滤器顺序,过滤器执行是有顺序的。例如,用户定义的过滤器的过滤顺序默认会在系统过滤器之后。
又例如,上图中 filter=“filter01, filter02”,filter01 过滤器执行就在 filter02 之前。
过滤器失效,如果针对某些服务或者方法不希望使用某些过滤器,可以通过“-”(减号)的方式使该过滤器失效。例如,filter=“-filter01”。
过滤器叠加,如果服务提供者和服务消费者都配置了过滤器,那么两个过滤器会被叠加生效。
0-7 位,“魔法数”高位。
8-15 位,“魔法数”低位。前面两个字节的“魔法数”,是用来区别两个不同请求。好像编程中使用的“;”“/”之类的符号将两条记录分开。PS:魔法数用固定的“0xdabb”表示,
16 位,数据包的类型,因为 RPC 调用是双向的,0 表示 Response,1 表示 Request。
17 位,调用方式,0 表示单项,1 表示双向。
18 位,时间标识,0 表示请求/响应,1 表示心跳包。
19-23 位,序列化器编号,就是告诉协议用什么样的方式进行序列化。例如:Hessian2Serialization 等等。
24-31 位,状态位。20 表示 OK,30 表示 CLIENT_TIMEOUT 客户端超时,31 表示 SERVER_TIMEOUT 服务端超时,40 表示 BAD_REQUEST 错误的请求,50 表示 BAD_RESPONSE 错误的响应。
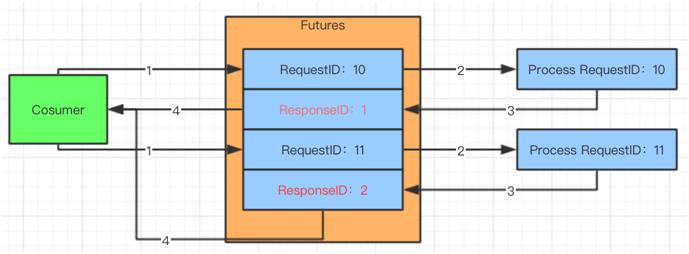
32-95 位,请求的唯一编号,也就是 RPC 的唯一 ID。
96-127,消息体包括 Dubbo 版本号,服务接口名,服务接口版本,方法名,参数类型,方法名,参数类型,方法参数值和请求额外参数。
在 HashMap 中会找到对应的 Request 对象,并且返回给服务消费者。
构造 16 字节的协议头,特别是需要创建前面两个字节的魔法数,也就是“0xdabb”,它是用来分割两个不同请求的。
生成唯一的请求/响应 ID,并且根据这个 ID 识别请求和响应协议包。
通过协议头中的 19-23 位的描述,进行序列化/反序列化操作。
为了提高处理效率,每个协议都会放到 Buffer 中处理。
总结
由于篇幅有限很多功能例如 SPI,Merger 等没有介绍到,有时间再和大家细聊。
END
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
如有收获,请划至底部,点击“在看”,谢谢!
BAT架构经验倾囊相授
以上是关于Dubbo序列化原理的主要内容,如果未能解决你的问题,请参考以下文章