解决ASP.NET中的各种乱码问题
Posted DotNet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决ASP.NET中的各种乱码问题相关的知识,希望对你有一定的参考价值。
来源:Fish Li
cnblogs.com/fish-li/archive/2012/10/14/2723631.html
经常发现有人被乱码困扰着,而我感觉比较幸运,很少为此烦恼过。
在这篇博客中,我将把我想到的一些与乱码有关的经验总结出来,供大家参考。
页面显示乱码问题
在一个网站中,有些页面会正常显示,然而,有些页面会显示成乱码。 如果发生这种情况,可以检查一下web.config和文件编码。
如果web.config是这样配置的:
<globalization fileEncoding="utf-8" />
而文件的编码不是UTF-8:
那么就会有乱码问题。
注意:反之是不是会出现乱码的。
1. 不设置fileEncoding,此时不会有乱码现象。
2. fileEncoding="gb2312",文件以utf-8编码,此时也不会有乱码现象。
因此,我建议最好让所有文件都以UTF-8编码保存,从而解决这类乱码问题。
AJAX提交的数据乱码问题
AJAX技术流行了这么多年了,我想现在没有几个网站不使用这种技术的。 然而,有些人在使用AJAX时,遇到了乱码问题。
通过分析这类乱码案例中,我发现几乎都是采用这种方式向服务端提交数据: “key1=” + escape(value1) +“&key2=” + escape(value2)
这种方法在多数情况下,的确能够正常工作,然而遇到一些特殊字符,就行不通了。原因我后面再来解释。
我为这类不正确的方法准备了一个示例 (为了保持示例简单,我演示一个拼接URL),
页面代码如下:
<p><a id="link2" href="#" target="_blank">escape</a></p>
<script type="text/javascript">
var str = "aa=1&bb=" + escape("fish li + is me.") + "&cc=" + escape("大明王朝1368");
$("#link2").attr("href", "/test_url_decode.ashx?method=escape&" + str);
</script>
服务端的代码就是从QueryString读取那些参数值,然后输出。由于代码实在太简单,就不贴出了。(可下载示例代码)
当我点击链接时,服务端返回了这样的结果:
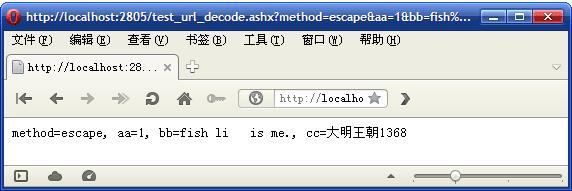
注意:"fish li + is me." 中间的加号没有了。
解决这个问题有个简单的方法,那就是使用JQuery的$.param()方法,修改后的代码如下:
<script type="text/javascript">
var myobject = { aa: 1, bb: "fish li + is me.", cc: "大明王朝1368" };
$("#link1").attr("href", "/test_url_decode.ashx?method=param&" + $.param(myobject));
</script>
另外,我非常反感拼接这种提交数据:“key1=” + escape(value1) +“&key2=” + escape(value2)
因为这种代码的可读性太差了,在此,我建议在AJAX调用时,最好直接使用JQuery的$.ajax方法向服务端提交数据。
请看下面的示例代码(注意我为data属性赋值的方式):
<p><a id="btnTestParam" href="javascript:void(0);">Click me! 【点击我】</a></p>
<div id="divResult"></div>
<script type="text/javascript">
$(function() {
$("#btnTestParam").click(function() {
$.ajax({
url: "/TestParam.ashx", type: "GET", cache: false,
data: { id: 2,
name: "fish li + is me.",
tel: "~!@#$%^&*()_+-=<>?|",
"x?x!x&x": "aa=2&bb=3&cc=汉字。", // 特殊的键名,值内容也特殊。
encoding: "见鬼去吧。?& :)",
中文键名: "大明王朝1368"
},
success: function(responseText) {
$("#divResult").html(responseText);
}
});
});
});
</script>
运行结果:
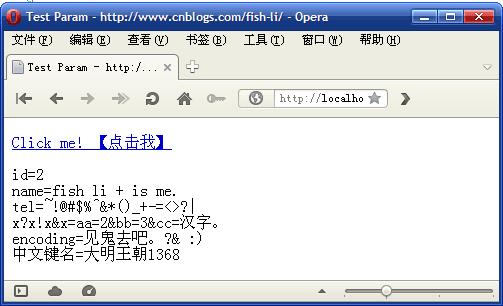
JavaScript中正确的URL编码方式
看过前面的示例,您有没有想过:为什么escape不能解决的问题,JQuery就能解决呢?
对于这个问题,我想还是先来看看MSDN中关于escape的说明(截图):

MSDN说的很清楚,我也没有必要再做解释。
不过,我想有人可能会问:我用POST提交数据呢?那可是不经过URL的。
是的,POST数据时,参数没有放在URL中,但是,仍然采用URL编码。
POST数据也采用URL编码,是因为:表单可以采用GET方式提交,那么数据将通过URL提交给服务器。
所以提交的数据都要经过URL编码。
我们再来看一下$.ajax是如何处理数据的提交过程的:
ajax: function( origSettings ) {
var s = jQuery.extend(true, {}, jQuery.ajaxSettings, origSettings);
// ............... 去掉一些无关的代码
// convert data if not already a string
if (s.data && s.processData && typeof s.data !== "string") {
// 注意下面这个调用
s.data = jQuery.param( s.data, s.traditional );
}
再来看jQuery.param的实现过程:
// Serialize an array of form elements or a set of
// key/values into a query string
param: function( a, traditional ) {
var s = [];
// ............... 去掉一些无关的代码
// If an array was passed in, assume that it is an array of form elements.
if ( jQuery.isArray(a) || a.jquery ) {
// Serialize the form elements
jQuery.each( a, function() {
add( this.name, this.value );
});
} else {
// ............... 去掉一些非重点代码
}
// Return the resulting serialization
return s.join("&").replace(r20, "+");
function add( key, value ) {
// If value is a function, invoke it and return its value
value = jQuery.isFunction(value) ? value() : value;
s[ s.length ] = encodeURIComponent(key) + "=" + encodeURIComponent(value);
}
}
这段代码的核心就是add函数的实现了,它在内部调用了encodeURIComponent()函数。
我们应该注意JQuery对数据的处理方式:encodeURIComponent(key) + "=" + encodeURIComponent(value);
JQuery在最后还把%20还替换成 + 号了。
在WEB开发领域,我想大家对JQuery的权威应该不用怀疑吧? 所以我认为JQuery的方法肯定是正确的。
从JQuery的实现方式也可以看出:encodeURI()其实也是不推荐在编码URL数据时使用的。
说到这里,我要说说为什么不推荐使用encodeURI。
encodeURI用于对整个URL字符串进行编码,如果某个参数值本身包含一些特殊字符。
例如:key = "x?x/x&x", value = "aa=2&bb=3&cc=汉字。",这个函数的结果将会不正确。
它通常用于编码URL路径中包含有类似汉字这种场合,不适合处理URL参数。
但是,URL路径中的目录名与文件名,我们可以选择英文字符,所以encodeURI通常没有机会使用。
ASP.NET中正确的URL编码方式
前面介绍了JavaScript中三种URL的编码方式,在服务端,ASP.NET有更多的URL编码方法,今天我也把服务端的编码也做了个总结,因为我发现网上有些资料也是错误的。
在ASP.NET中提供三个URL编码方法:HttpUtility.UrlPathEncode、HttpUtility.UrlEncode、Server.UrlEncode
.NET framework还提供了System.Uri这个类,它也有一些用于URL处理的方法。 比如EscapeUriString,EscapeDataString这二个方法,可用于URL路径与参数的编码任务。
面对这些方法,我该选择哪个?
我建议在 ASP.NET 中,编码查询参数 时选择HttpUtility.UrlEncode(str) ,
并且在拼接URL时,采用 HttpUtility.UrlEncode(key) + "=" + HttpUtility.UrlEncode(value) 的方法。
如果要 编码URL中的路径,请使用HttpUtility.UrlPathEncode()
下面我来解释前面不建议使用的另外的一些方法的原因:
1. Server.UrlEncode: 这个方法其实也是调用HttpUtility.UrlEncode,只是它会尽量使用Response.ContentEncoding所表示的编码格式, 然而HttpUtility.UrlEncode(str)总是会使用UTF-8编码,如果你不希望被字符编码纠缠,那就应该放弃Server.UrlEncode , 毕竟UTF-8编码才是更好的选择。
2. 虽然System.Uri的那二个编码方法,也能实现我们需要的URL编码任务, 但是,当ASP.NET在填充Request.QueryString, Request.Form时,使用的解码方法是HttpUtility.UrlDecode, 因此,如果你执意选择使用System.Uri的相关的编码方法,显然就不能与解码方法匹配,后果如何就难说了。
正确的URL编码方式的总结
由于编码函数(方法)较多,而且又比较重要,我认为有必要再做个总结。
一个完整的URL可以简单地认为包含二个部分:文件路径(含目录) 和 查询参数(QueryString)
在编码时,一定要分开处理。
编码文件路径时,应该选择 encodeURI,HttpUtility.UrlPathEncode 。
编码查询参数时,应该选择 encodeURIComponent,HttpUtility.UrlEncode,而且拼接方式应该是:Encode(key) + "=" + Encode(value)
绝对不能先把整个URL(包含查询参数)拼接起来了,再来考虑该选择哪个编码方法。
再说一遍:在JavaScript中使用escape肯定是错误的。
彻底解决encodeURIComponent()与GB2312乱码问题
前面我建议在JavaScript中使用encodeURIComponent()来处理提交数据, 然而encodeURIComponent()在编码字符时,使用的是UTF-8编码。 也正因为这个原因,有人可能会说:我的网站使用的编码方式是gb2312 !
<globalization requestEncoding="gb2312" responseEncoding="gb2312" />
对于这个回答,我有时实在不想再说下去了:你就不能把网站的编码改成UTF-8吗?
现在好了,我设计了一种方法,可以解决在GB1212编码的网站中使用encodeURIComponent(), 这个方法的设计思路比较直接:既然encodeURIComponent()是使用UTF-8编码, 那么,我们是不是只要告诉服务端,客户端提交的数据是UTF-8编码的,此时服务端只要识别后,按照UTF-8编码来解码,问题就解决了。
理清了思路,代码其实很简单。首先来看客户端的代码。
$.ajax({
// 注意下面这行代码,它为请求添加一个自定义请求头
beforeSend: function(xhr) { xhr.setRequestHeader("x-charset", "utf-8"); },
url: "/TestParam.ashx", type: "GET", cache: false,
data: { id: 2,
name: "fish li + is me.",
tel: "~!@#$%^&*()_+-=<>?|",
"x?x!x&x": "aa=2&bb=3&cc=汉字。", // 特殊的键名,值内容也特殊。
encoding: "见鬼去吧。?& :)",
中文键名: "大明王朝1368"
},
success: function(responseText) {
$("#divResult").html(responseText);
}
});
注意:在原来的基础上,我只加了一行代码:
beforeSend: function(xhr) { xhr.setRequestHeader("x-charset", "utf-8"); },
再来看服务端代码。我写了一个HttpModule来统一处理这个问题。
public class ContentEncodingModule : IHttpModule
{
public void Init(HttpApplication app)
{
app.BeginRequest += new EventHandler(app_BeginRequest);
}
void app_BeginRequest(object sender, EventArgs e)
{
HttpApplication app = (HttpApplication)sender;
HttpWorkerRequest request = (((IServiceProvider)app.Context)
.GetService(typeof(HttpWorkerRequest)) as HttpWorkerRequest);
// 注意:我并没有使用 app.Request.Headers["x-charset"]
// 因为:绝大部分程序不访问它,它将一直保持是 null,
// 如果我此时该问这个集合,会导致填充它。
// 我认为填充Headers集合比我下面的调用的成本要高很多,
// 所以,直接通过HttpWorkerRequest读取请求头对性能的损耗会最小。
string charset = request.GetUnknownRequestHeader("x-charset");
if( string.Compare(charset, "utf-8", StringComparison.OrdinalIgnoreCase) == 0 )
// ASP.NET在填充QueryString,Form时,会访问Request.ContentEncoding做为解码时使用的字符编码
app.Request.ContentEncoding = System.Text.Encoding.UTF8;
}
}
改造后的结果是:除非客户端明确添加"x-charset"请求头,否则还是按原来的方式处理,对于服务端代码来说,完全不用修改。
说明:
1. 如果网站的提交全部采用JQuery,也可以统一设置,这是JQuery支持的功能。
2. 如果使用JQuery1.5以上版本,也可以写成:headers: {"x-charset" : "utf-8"}
3. 就算以后网站使用UTF-8编码,所有代码不需要做任何修改。
Cookie乱码问题
前段时间,有人在博客的评论中问我:asp.net服务器端写中文cookie,js客户端读取时乱码。
其实这个问题还是比较好解决的,方法是:写Cookie时用HttpUtility.UrlEncode编码,然后在客户端使用decodeURIComponent把内容转回来就可以了。 在此,我推荐使用jquery.cookie.js这个插件来读写Cookie。 示例代码如下(前端):
$(function() {
var cookie = $.cookie("TestJsRead");
$("#cookieValue").text(cookie);
});
服务端代码:
cookie = new HttpCookie("TestJsRead", HttpUtility.UrlEncode("大明王朝1368"));
Response.Cookies.Add(cookie);
下载文件名乱码问题
有时我们需要在程序运行时动态的创建文件,并让用户下载这个在运行时产生的文件, 然而,有时候用户会要求程序能生成一个默认的文件名,方便他们保存。 此时,我们只需要设置Content-Disposition这个响应头,并给一个默认的文件名就可以了。
一般说来,我们只要让默认的下载文件名是英文及数字,问题永远不会出现, 但是,有时候用户可能要求默认的文件中包含汉字, 最终,问题也随之发生了。 请看下面的代码:
public void ProcessRequest(HttpContext context)
{
byte[] fileContent = GetFileContent();
context.Response.ContentType = "application/octet-stream";
string downloadName = "ClownFish性能测试结果.xlsx";
string headerValue = string.Format("attachment; filename=\"{0}\"", downloadName);
context.Response.AddHeader("Content-Disposition", headerValue);
context.Response.OutputStream.Write(fileContent, 0, fileContent.Length);
}
这段代码在我的FireFox, Opera, Safari, Chrome都能正常运行,其中FireFox显示的下载对话框也是我期待的样子:
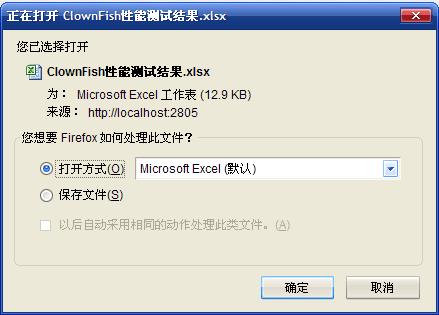
遗憾的是,在我的IE8中是这样的:
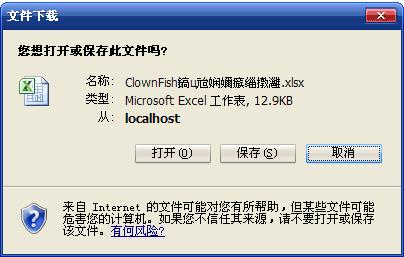
对于这个乱码问题,我们需要把代码做一点修改:
string downloadName = "ClownFish性能测试结果.xlsx";
if( context.Request.Browser.Browser == "IE" )
downloadName = HttpUtility.UrlPathEncode(downloadName);
此时IE显示的文件名就不是乱码了。
说明:我的机器环境是 Windows Server 2003 SP2, 用于测试的浏览器版本分别为:
多语言数据的乱码问题
现在还有一种乱码问题是:同一个程序供多种不同字符集(语言)的用户在使用。
例如:程序是简体中文的,此时,繁体中文的用户无法保存繁体汉字(就算简体汉字能正常显示)。
当发现这种现象时,需要检查一下数据库的字段类型,是否是Unicode或者UTF-8, 因为当数据字段的字符集不支持多种语言时,乱码问题必定产生。
我建议在使用SQL SERVER时,保存文字的字段都使用N开头的类型, 如:nvarchar, nchar,除非明确知道要保存邮政编码或者md5值,才有必要使用char(xxx)这种数据类型。 类似的,在mysql中,我建议使用UTF-8
乱码问题的总结
ASP.NET的乱码问题一般与二个因素有关:
1. 选择了不恰当的字符编码,如:gb2312
2. 选择了不正确的URL编码方法,如:escape()
因此,解决方案其实也不难:
1. 字符编码选择 utf-8 ,包含文件编码,请求/响应编码,数据库字段类型。
2. URL编码方法选择encodeURIComponent,再次强烈推荐直接使用JQuery
我一直认为:正确的方法可以让我在无形中避开许多问题。
如果你还为乱码问题而烦恼,我建议你先想想你是否选择了不正确的编码(方法)。
下载示例代码(http://files.cnblogs.com/fish-li/AspnetEncode.cab.7z)
看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能
以上是关于解决ASP.NET中的各种乱码问题的主要内容,如果未能解决你的问题,请参考以下文章
j-query 中文乱码处理 单词 escape 及其他的中文乱码处理
asp用urlEncode加密后的中文用asp.net UrlDecode解密会出现乱码,请问怎么解决
asp.net 后台 Request.Params时遇到前台发送的中文字符 , 得到乱码怎么解决?
idea ssm项目出现日志中文乱码,封装的json中的msg字段中文乱码(但是json封装的bean中的字段不乱码)等其他各种项目下的中文乱码解决方案