《云计算(第三版)》精华连载14:Google应用程序引擎
Posted 刘鹏看未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《云计算(第三版)》精华连载14:Google应用程序引擎相关的知识,希望对你有一定的参考价值。
应用程序引擎
如果说Amazon给开发人员配置了一台可以在上面安装许多软件的虚拟机的话(参见第3章),Google App Engine[22]可以说是给开发人员提供了一个基于Python语言的Django框架。由于Google App Engine与Google自身的操作环境联系比较紧密,涉及底层的操作很少,用户比较容易上手。并且Python语言相对而言简单易学,开发人员可以很容易地开发出自己的程序。但是Google App Engine简单方便的同时,却在提供的解决方案上有着自己的局限性。
2.9.1 Google App Engine简介
Google公司发展迅速,不断推出自己的新产品,比如Google搜索、Google Maps、Google Earth、Google AdSense、Google Reader等。在推出自己产品的同时,Google倾力打造了一个平台,来集成自己的服务并供开发者使用,这就是Google App Engine平台。
简单地说,Google App Engine是一个由Python应用服务器群、Bigtable数据库及GFS数据存储服务组成的平台,它能为开发者提供一体化的可自动升级的在线应用服务。
从云计算平台的分类来看,Amazon提供的是IaaS平台,而Google提供的Google App Engine是一个PaaS平台,用户可以在上面开发应用软件,并在Google的基础设施上运行此软件。其定位是易于实施和扩展,无须服务器维护。
Google App Engine可以让开发人员在Google的基础架构上运行网络应用程序。在Google App Engine之上易构建和维护应用程序,并且应用程序可根据访问量和数据存储需要的增长轻松进行扩展。使用Google App Engine,开发人员将不再需要维护服务器,只需要上传应用程序,它便可立即为用户提供服务。
在Google App Engine中,用户可以使用appspot.com域上的免费域名为应用程序提供服务,也可以使用Google企业应用套件从自己的域为它提供服务。开发人员可以与全世界的人共享自己的应用程序,也可以限制为只有自己组织内的成员可以访问。
除此之外,还可以免费使用Google App Engine。注册一个免费账户即可开发和发布应用程序,而且不需要承担任何费用和责任。免费账户可以使用多达500MB的持久存储空间,以及可支持每月约500万页面浏览量的超大CPU和带宽。
Google App Engine作为一个开发平台,有其自身的特点。
Google App Engine的整体架构如图2-54[23]所示。Google App Engine的架构可以分成四部分:前端和静态文件负责将请求转发给应用服务器并进行负载均衡和静态文件的传输;应用服务器则能同时运行多个应用的运行时(Runtime);服务器群提供了一些服务,主要有Memcache、Images、URLfetch、E-mail和Data Store等;Google App Engine还有一个应用管理节点,主要负责应用的启停和计费。
关于Google App Engine的一些基本概念,比如应用程序环境、沙盒、Python运行时环境、数据库、Google账户、App Engine服务、开发流程、配额和限制等,总体而言,每个开发程序都将涉及这些概念。每个开发程序有自身的应用程序环境(这个环境由Google App Engine提供),该环境对应用程序提供了一些基本的支持,使应用程序可以在Google App Engine上正常运行。除此之外,Google App Engine为每个应用程序提供了一个安全运行环境(沙盒),该沙盒可以保证每个应用程序能够安全地隔离运行。现阶段,Google App Engine支持Java和Python语言,通过Google App Engine 的 Java 运行时环境,可以使用标准 Java 技术构建应用程序。开发程序时还可能要使用到Python运行时环境,该环境包括Python运行库等模块,并且Google App Engine还提供了一个由Python语言编写的网络应用程序框架Webapp。Google App Engine上开发的应用程序使用的是Data Store数据库,该数据库不同于日常使用的Oracle、SQL Server等数据库,它是一个分布式存储数据库,可以随着应用程序访问量的增加而增加。使用Google App Engine开发应用程序必须拥有一个Google账户,有了该账户之后才可以在Google App Engine上运行开发的程序。为了简化开发流程,Google App Engine提供了一些服务,这些服务统称为App Engine服务,使用Google App Engine开发应用程序必须遵守一定的开发流程。Google App Engine为每个Google账户用户提供了一些免费的空间与流量支持,但是免费的空间和流量有一定的配额和限制。
通过对这些概念的了解,可深入理解Google App Engine。
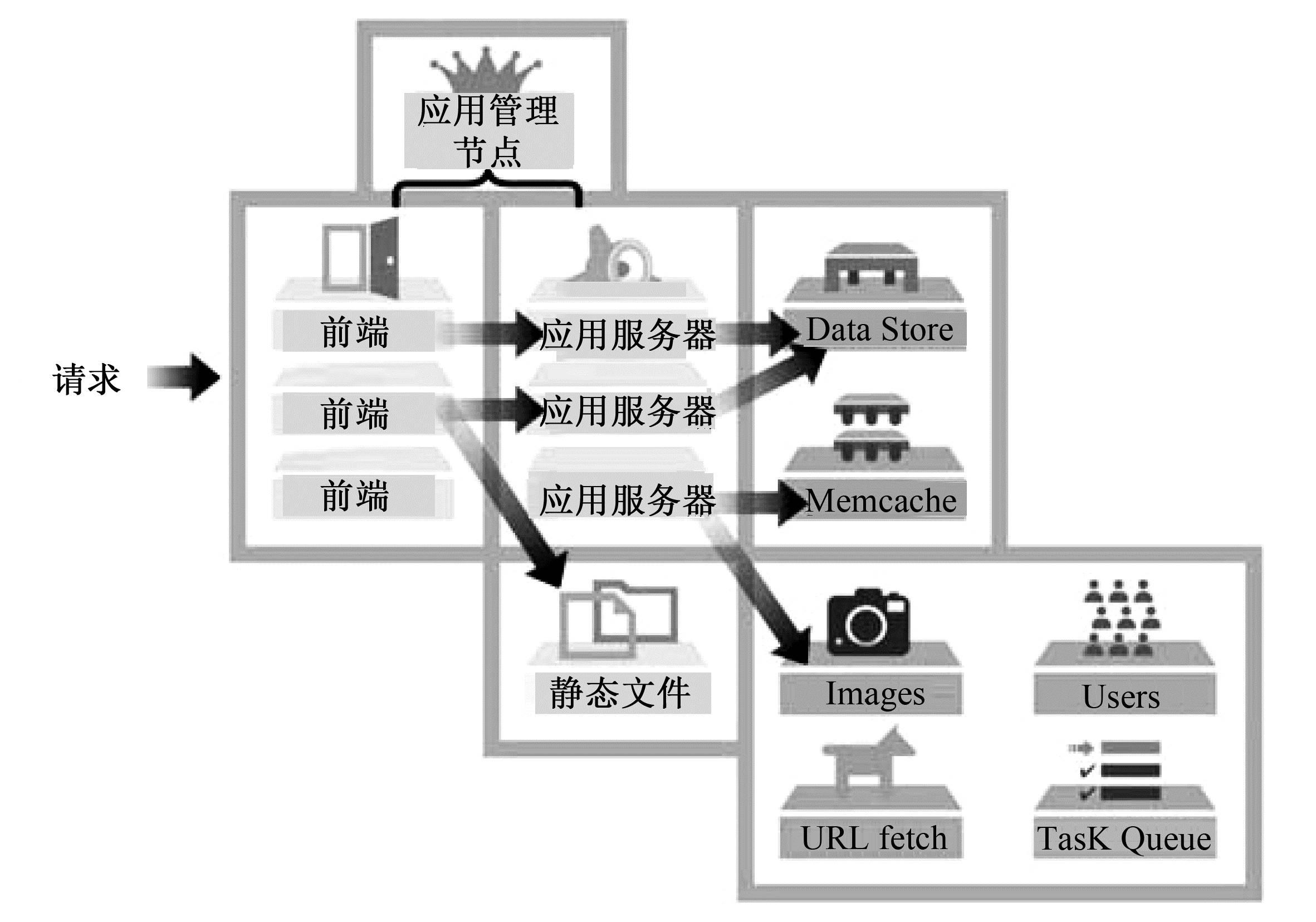 图2-54 Google App Engine的整体架构
图2-54 Google App Engine的整体架构
2.9.2 应用程序环境
Google App Engine有着自身的应用程序环境,这个应用程序环境包括以下特性。
(1)动态网络服务功能。能够完全支持常用的网络技术。
(2)具有持久存储的空间。在这个空间里平台可以支持一些基本操作,如查询、分类和事务的操作。
(3)具有自主平衡网络和系统的负载、自动进行扩展的功能。
(4)可以对用户的身份进行验证,并且支持使用Google账户发送邮件。
(5)有一个功能完整的本地开发环境,可以在自身的计算机上模拟Google App Engine环境。
(6)支持在指定时间或定期触发事件的计划任务。
基于这样的环境支持,Google App Engine可以在负载很重和数据量极大的情况下轻松构建安全运行的应用程序。
最开始Google App Engine只支持Python开发语言,现阶段开始支持Java语言。本书案例中,Google App Engine应用程序使用Python编程语言实现。该运行时环境包括完整的Python语言和绝大多数的Python标准库。在Python运行时环境中使用的是Python 2.5.2版本。这里先详细介绍一下Python运行时环境。
Python运行时环境包括Python标准库,开发人员可以调用库中的方法来实现程序功能,但是不能使用沙盒限制的库方法。这些受限制的库方法包括尝试打开套接字、对文件进行写入操作等。为了便于编程,Google App Engine设计人员将一些模块禁用了,被禁用的这些模块的主要功能是不受运行时环境的标准库支持的,因而,开发者在导入这些模块的代码时程序将给出错误提示。
在Python运行时环境中,应用程序只能以Python语言编写,扩展代码中若有C语言,则应用程序将不受系统支持。Python环境为开发平台中的数据库、Google账户、网址抓取和电子邮件服务等提供了丰富的Python API。此外,Google App Engine还提供了一个简单的Python网络应用程序框架,这个框架称为Webapp。借助于这个框架,开发人员可以轻松构建自己的应用程序。为了方便开发,Google App Engine还包括了Django网络应用程序框架,在开发过程中,可以将Django与Google App Engine配合使用。
沙盒是Google App Engine虚拟出的一个环境,类似于PC所使用的虚拟机。在这个环境中,用户可以开发使用自己的应用程序,沙盒将用户应用程序隔离在自身的安全可靠的环境中,该环境和网络服务器的硬件、系统及物理位置完全无关,并且沙盒仅提供对基础操作系统的有限访问权限。
沙盒还可以对用户进行如下限制。
(1)用户的应用程序只能通过Google App Engine提供的网址抓取API和电子邮件服务API来访问互联网中其他的计算机,并且其他计算机如请求与该应用程序相连接,只能在标准接口上通过HTTP或HTTPS进行。
(2)应用程序无法对Google App Engine的文件系统进行写入操作,只能读取应用程序代码上的文件,并且该应用程序必须使用Google App Engine的Data Store数据库来存储应用程序运行期间持续存在的数据。
(3)应用程序只有在响应网络请求时才运行,并且这个响应时间必须极短,在几秒之内必须完成。与此同时,请求处理的程序不能在自己的响应发送后产生子进程或执行代码。
简言之,沙盒给开发人员提供了一个虚拟的环境,这个环境使应用程序与其他开发者开发使用的程序相隔离,从而保证每个使用者可以安全地开发自己的应用程序。
开发人员开发程序必须使用Google App Engine SDK,即Google App Engine软件开发套件。可以先下载这个套件到自己的本地计算机上,然后进行开发和运行。使用SDK时,可以在本地计算机上模拟包括所有Google App Engine服务的网络服务器应用程序,该SDK包括Google App Engine中的所有API和库。该网络服务器还可以模拟沙盒环境,这些沙盒环境用来检查是否存在禁用的模块被导入的情况,以及对不允许访问的系统资源的尝试访问等情况的发生。
Google App Engine SDK完全使用Python实现,这个开发套件可以在装有Python 2.5的任何平台上面运行,包括Windows、Mac OS X和Linux等,开发人员可以在Python网站上获得适合自己系统的Python。
系统中有一个管理控制台,这个管理控制台有一个网络接口,用于管理在Google App Engine上运行的应用程序。开发人员可以使用管理控制台来创建应用程序、配置域名、更改应用程序当前的版本、检查访问权限和错误日志以及浏览应用程序数据库等。
2.9.3 Google App Engine服务
Google App Engine提供了多种服务。这些服务可以帮助开发人员在管理应用程序的同时执行常规操作,可以通过以下API来使用Google App Engine提供的服务。
1.图像操作API
开发的应用程序可以使用Google App Engine提供的图像操作API对图像进行操作,使用该API可以对JPEG和PNG格式的图像进行缩放、裁剪、旋转和翻转等操作。
1)Image类
Image类来自google.appengine.api.images模块,该类可以用来封装图像信息及转换该图像,转换时可以使用execute_transforms()方法;可以使用class Image(image_data)来构造函数,参数image_data表示字节字符串(str)格式的图像数据;可以采用PNG、JPEG、TIFF或ICO等格式对图像数据进行编码。
Image类中主要有如下实例方法。
(1)resize(width=0, height=0):该方法用来缩放图像,可以将图像缩小或放大到参数指定的宽度或者高度。参数width和height都以像素数量来表示,并且必须是int型或long型。
(2)crop(left_x, top_y, right_x, bottom_y):该方法可以将图像裁剪到指定边界框的大小,并且裁剪后以相同的格式返回转换的图像。参数left_x表示边界框的左边界,top_y表示边界框的上边界,right_x表示边界框的右边界,bottom_y表示边界框的下边界。以上四个参数均采用指定为float类型值的从0.0到1.0的图像宽度的比例(其中float值包括了0.0 和1.0)。
(3)rotate(image_data, degrees, output_encoding=images.PNG):该方法用来旋转图像。参数degrees表示图像旋转的量,采用的形式是度数,且这个度数必须是90°的倍数,数据格式必须为int型或long型,使用该函数对图像进行旋转是沿顺时针方向执行的。image_data是指要旋转的图像,是JPEG、GIF、BMP、TIFF或者ICO等格式的字节字符串(str)。output_encoding指转换的图像所需的格式,可以是images.PNG或images.JPEG格式,默认的格式是images.PNG格式。
(4)horizontal_flip(image_data, output_encoding=images.PNG):该函数表示对图像进行水平翻转。参数image_data表示要翻转的图像是JPEG、PNG、TIFF或ICO格式的字节字符串(str)。
output_encoding参数表示要转换的图像所需要的格式,可以是images.PNG或是images.JPEG,默认的格式是images.PNG格式。
(5)vertical_flip(image_data, output_encoding=images.PNG):该函数表示垂直地翻转图像,并且转换后的图像与以前的格式一样。
2)exception类
google.appengine.api.images 包主要为用户提供了以下exception类。
(1)exception Error():这是该包中所有异常的基类。
(2)exception TransformationError():表示尝试转换图像时发生错误。
(3)exception BadRequestError():表示转换参数无效。
2.邮件API
1)允许的附件类型
允许作为电子邮件附件的MIME类型以及相对应的文件扩展名主要有:图像格式包括BMP、GIF、JPEG、JPG、JPE、PNG、TIFF、TIF、WBMP,文本格式包括CSS、CSV、HTM、html、TEXT、TXT、ASC、DIFF、POT,应用程序格式包括PDF、RSS。
send()方法用来发送电子邮件。
(3)函数。google.appengine.api.mail包为邮件API主要提供了以下函数。
② send_mail(sender, to, subject, body, **kw):创建并且发送一封电子邮件。sender、to、subject和body参数是邮件必填的字段。其他的字段也可以指定为关键字参数。
(4)异常。google.appengine.api.mail 包为邮件API主要提供了以下 exception 类。
① exception Error():该包中所有异常的基类。
3.Memcache API
高性能的网络应用程序一般在运行之前需要使用分布式内存数据缓存(Memcache),或用分布式内存数据缓存来代替某些任务的稳定持久存储,Google App Engine为用户提供了这样一个高性能的内存键值缓存,可以使用应用程序的实例来访问这个缓存。Memcache适合存储永久性功能和事务性功能的数据,例如,可以将临时数据或数据库数据复制到缓存以进行高速访问。
Memcache API提供了一个基于类的接口,以便和其他Memcache API相兼容。这里Client类由google.appengine.api.memcache包提供。
1)构造函数
class Client()产生与Memcache服务通信的客户端。
2)实例方法
构造的Client 实例主要有以下几种方法。
(1)set(key, value, time=0, min_compress_len=0):该方法用来设置键的值,与先前缓存中的内容无关。其中参数key表示要设置的键,key可以是字符串或(哈希值,字符串)格式的元组;参数value表示要设置的值;参数time指可选的过期时间,可以是相对当前时间的秒数(最多1个月),也可以是绝对UNIX时间戳的时间;min_compress_ len是为了兼容性而忽略的选项。
(2)get(key):该方法用来在Memcache中查找一个键。参数key指明要在Memcache中查找的键,key可以是字符串或(哈希值,字符串)格式的元组。如果在Memcache中找到键,则返回值为该键的值,否则返回None。
(3)delete(key, seconds=0):该方法用来从 Memcache 删除键。参数key指要删除的键,可以是字符串或(哈希值, 字符串)格式的元组,参数seconds指定删除的项目对添加操作锁定的可选秒数,值可以是从当前时间开始的增量,也可以是绝对UNIX时间戳时间,默认情况下值为0。
(4)add(key, value, time=0, min_compress_len=0):该方法用来设置值,但是只在项目没有处于Memcache时设置。参数key指明要设置的键,它可以是字符串或(哈希值,字符串)格式的元组;参数value是指要设置的值;参数time指明可选的过期时间,可以是相对当前时间的秒数,也可以是绝对UNIX时间戳时间;参数min_compress_len是为了兼容性而忽略的选项。
(5)replace(key, value, time=0, min_compress_len=0):该方法用来替换键的值。参数key指要设置的键,Key可以是字符串或(哈希值,字符串)格式的元组;参数value指明要设置的值;参数time是指可选的过期时间,可以是相对当前时间的秒数,也可以是绝对UNIX时间戳时间;参数min_compress_len是为了兼容性而忽略的选项。
(6)incr(key, delta=1):该方法可以自动增加键的值。在内部,值是无符号64bit整数,同时Memcache不会检查64bit溢出,如果值过大则会换行。这里的键必须已存在于缓存中才能增加值。初始化计数器时可以使用set()进行初始值的设置。参数key是指要增加的键,key可以是字符串或(哈希值,字符串)格式的元组;参数delta值作为键的增加量的非负整数值(int型或long型),默认值为1。
(7)decr(key, delta=1):该方法可以自动减少键的值。内部而言,值是无符号的64bit数,并且Memcache不检查64bit溢出,若值过大则会换行。初始化计数器时可以使用set()进行初始值设置。参数key指要减少的键,key可以是字符串或(哈希值,字符串)格式的元组;参数delta是键的减少量的非负整数值(int型或long型),默认值为1。
(8)flush_all():该方法用来删除Memcache中的所有内容。若成功则返回True,若是RPC或服务器错误,则返回False。
(9)get_stats():该方法可获取该应用程序的Memcache统计信息。函数的返回值是将统计信息名称映射到相关值的参照表。
4.用户API
Google App Engine的功能和账号是集成的,因此应用程序可以让用户使用他们自身的Google账户登录。
1)User对象
2)登录网址
用户API提供了函数来构建到Google账户的网址,这样Google账户允许用户登录或退出,并重新定向到用户的应用程序。登录或退出目标网址可以使用users.create_login_url()和users.create_logout_url()。
3)User类
User类的一个对象代表具有Google账户的一个用户,User类是由google.appengine. api. users模块提供的。
(2)实例方法。User实例主要提供以下方法。
① nickname():用来返回用户的“昵称”。
(3)函数。google.appengine.api.users 包主要提供以下函数。
① create_login_url(dest_url):用于返回一个网址。当用户访问这个网址时,它将提示用户使用自己的Google账户登录,并将用户重新定向到指定的dest_url网址。其中dest_url 可以是完整的网址,也可以是相对于应用程序的域的路径。
② create_logout_url(dest_url):用来返回一个网址。当用户访问这个网址时会注销这个用户,然后将用户重新定位到指定的dest_url网址。其中参数dest_url 可以是完整的网址,或者是相对于应用程序的域的路径。
③ get_current_user():若用户已登录,则该函数返回当前用户的User对象;若用户未登录,返回None。
(4)异常。google.appengine.api.users 包主要提供以下exception类。
① exception Error():这个包中所有异常的基类。
③ exception RedirectTooLongError():表示create_login_url() 或create_logout_url()函数的重定向网址的长度超过了所允许的最大长度。
5.数据库API
Google App Engine提供了一个强大的分布式数据存储服务。该服务包含查询引擎、事务功能等功能,并且该数据库规模可以随着访问量的上升而扩大。Google App Engine数据库和传统的关系数据库不同,该数据库中的数据对象有一个类和一组属性。数据库中的查询可以检索按照属性值过滤的实体,也可以检索按照分类指定种类的实体,其中属性值可以是任何一种受系统数据库支持的属性值类型。
Google App Engine的数据库使用了简单的API来为用户提供查询引擎和事务存储服务,并且这些服务都运行在Google的可扩展结构上。在Google App Engine中,Python接口包含了数据建模API和类似于SQL的一种查询语言(称为GQL)。通过这些API和GQL查询语言,可以极大地方便用户开发可扩展数据库的应用程序。
Google App Engine的数据库API拥有一个用于定义数据模型的机制。这里Model用来描述实体的类型(包括其属性的类型和配置)。数据库 API 提供两种查询接口:查询对象接口和GQL查询语言。查询的结果以Model类的实例形式返回实体,这些Model类可以被修改并放到数据库中。
1)Model类
Model类是数据模型定义的超类,由google.appengine.ext.db包提供。
Model 类的构造函数定义如下。
class Model(parent=None, key_name=None, **kw)。其中参数parent用来作为新实体的父实体的Mode 实例或key实例;参数key_name是新实体的名称,并且key_name 的值不得以数字开头,也不能采用“__*__”的形式,存储为Unicode字符串,str值转换为ASCII文本;参数“**kw”表示实例的属性的初始值,作为关键字参数。
(1)类方法。Model类主要提供以下类方法。
① Model.get(keys):用来获取指定Key对象的Model实例,键值必须代表Model类的实例。若程序提供的键类型不符合,则系统抛出KindError。参数keys是指Key对象或Key对象的列表,还可以是Key对象的字符串版本或字符串列表。
② Model.all():返回代表与该Model对应类型的所有实体的Query对象。在执行Query对象上的方法之前,可以对查询进行过滤和排序。
③ Model.gql(query_string, *args, **kwds):用来对该Model的实例执行GQL查询。其中参数query_string指明GQL查询中“SELECT * FROM model”后的部分;参数“*args”用于位置参数绑定,类似于GqlQuery构造函数;参数“**kwds”表示关键字参数绑定,类似于GqlQuery构造函数。
(2)实例方法。Model实例主要有以下方法。
① key():返回该 Model 实例的数据库Key。在put()入数据库之前,Model实例没有键。在实例拥有键之前调用key()会抛出NotSavedError错误。
② put():将Model实例存储在数据库中。如果Model实例是新创建的并且之前从未存储过,则该方法会在数据库中创建新的数据实体,否则,该方法会用当前属性值更新数据实体。该方法会返回存储的实体的Key。
③ delete():用来从数据库中删除Model实例。如果实例从未被put()到数据库,则删除不会起任何作用。
2)Property类
Property类也是一个超类,用来对数据模型的属性进行定义。它可以定义属性值的类型、值的验证方式以及在数据库中的存储方式等,Property由google.appengine.ext.db包提供。
(1)类构造函数。Property 基类的构造函数定义如下。
class Property(verbose_name=None, name=None, default=None, required=False, validator= None, choices=None)。这是Model属性定义的超类。其中参数verbose_name表示用户友好的属性名称,属性构造函数的第一个参数必须始终是这个参数。参数name表示的是属性的存储名称,默认情况下,该名称表示属性的属性名称。参数default是指属性的默认值,若属性值从未被指定或值是None,则该属性值被视为默认值。参数required若是True,则属性值不能为None,Model实例必须要利用构造函数来初始化所有必需的属性,这样创建实例时才不会缺少值。参数validator表示分配属性值的时候应该调用以便用来验证值的函数,函数使用该属性值为唯一的参数。参数choices表示可接受的属性值的列表,如果设置了该参数,则不能给属性分配该列表以外的其他值。
(2)类属性。Property类下面的子类可以定义下面的属性。
data_type属性用来接受作为Python自有值的Python数据类型或类。
(3)实例方法。Property类实例主要具有以下方法。
① default_value():返回属性的默认值。其中基础的实施方案使用的是传递到构造函数default参数的值。
② validate(value):表示属性的完整验证程序。若value值有效,则函数返回该值。程序的基础实施方案将会检查以下的内容:value值是否为None;若已经根据选择的内容对属性进行了设置,那么该值是否是一个有效的选择(choices参数);若这个值存在,那么该值是否已经通过自定义的程序的验证(validator参数)。
③ empty(value):若这个属性类型的value使用的是空值,那么该应用程序将返回True。
3)Query类
Query类是一个数据库查询的接口,程序可以使用对象和方法来准备这个查询。Query类由google.appengine.ext.db包提供。
(1)构造函数。Query类的构造函数的定义如下。
class Query(model_class)。函数主要表示使用对象和方法来准备数据查询的接口,由构造函数返回的Query实例表示的是对该类型的所有实体的查询。函数中参数model_class代表了查询的数据库实体类型的Model(或者Expando)类。
(2)实例方法。Query类主要有以下几种实例方法。
① filter(property_operator, value):对属性的条件进行过滤,并加到该查询中,因而该查询只会返回满足所有条件的属性的实体。参数property_operator包含了属性名称和比较运算符的字符串,并且支持下列的比较运算符:<、<=、=、>=、>。参数value用来代表比较过程中所用的置于表达式右侧的值。
② order(property):用来给结果添加排序,并且结果将根据首先添加的顺序进行排列。参数property表示的是一个字符串,是要为其排序的属性的名称,若要将排列顺序改为降序,可以在名称前加上一个连字符(-),若不加表示进行升序排列。
③ ancestor(ancestor):对祖先条件进行过滤,并且将它加入查询,该查询只会返回以这个祖先条件为过滤器的那些实体。参数ancestor代表的是该祖先的Model实例或Key实例。
④ get():执行查询,然后返回第一个结果。若这个查询没有返回任何结果,则会返回None。
⑤ fetch(limit, offset=0):执行查询,然后返回结果。参数limit是必须有的一个参数,表示要返回的结果的数量。若满足条件的结果数量不够,则返回的结果或许会少于limit个。参数offset表示要跳过的结果的数量,返回值是一个Model实例列表,也可能是一个空的列表。
⑥ count(limit):返回这个查询所抓取的结果的数量。参数limit表示的是要计数的结果的最大数量。
4)GqlQuery类
GqlQuery类是一种使用了Google App Engine查询语言(即GQL)的数据库查询接口。GqlQuery类由google.appengine.ext.db包提供。
(1)构造函数。GqlQuery类的构造函数定义如下。
class GqlQuery(query_string, *args, **kwds),函数使用的是GQL的Query对象。参数query_string表示的是以“SELECT * FROM model-name”开头的完整GQL语句,参数“*args”表示位置参数绑定,参数“**kwds”表示关键字参数绑定。
(2)实例方法。GqlQuery实例主要有以下方法。
① bind(*args, **kwds):重新绑定参数进行查询。新的查询将会在重新绑定参数之后第一次访问结束时执行。参数“*args”表示新位置参数绑定,参数“**kwds”表示新关键字参数绑定。
② get():执行查询,并且返回第一个结果。若查询之后没有返回结果就返回None。
③ fetch(limit, offset=0):执行查询,然后返回结果。参数limit表达的是程序将要返回的结果的数量,是必需的参数。当结果数未知时,可以迭代地使用GqlQuery对象而不是使用fetch()方法来从查询结果中获取每个结果。参数offset是指要跳过的结果的数量,返回的值是一个Model 实例列表,也可能是一个空的列表。
④ count(limit):返回该查询抓取的结果的数量。count()比那些通过常量系数来进行检索的速度要快一些。参数limit表示的是要计数的结果的最大值。
5)Key类
Key类的实例代表的是数据库实体唯一键,Key类由google.appengine.ext.db包提供。
(1)构造函数。class Key(encoded=None)。函数表示的是数据库对象的唯一键。用户可以通过将 Key 对象传递到str()(或调用对象的__str__()方法),也可以把键编码成字符串。参数encoded表示的是Key实例的str形式。
(2)类方法。Key 类提供以下类方法。
Key.from_path(*args, **kwds)方法表示从一个或者多个实体键的祖先路径来构建新的Key对象。这里的路径代表的是实体中父子之间关系的层次结构,每一个实体都由实体的类型以及其数字ID或键名来代表。参数“*args”是从根实体到主题的路径,参数“**kwds”是关键字参数。
(3)实例方法。Key实例主要有以下方法。
① app():返回存储数据实体的应用程序的名称。
② kind():以字符串形式返回数据实体的类型。
③ id():以整数形式返回数据实体的数字ID,若实体没有数字ID,则函数返回None。
④ name():返回数据实体的名称,若实体没有名称则返回None。
(4)函数。google.appengine.ext.db包主要提供以下函数。
① get(keys):用于获取任何 Model 的指定键的实体。其中参数keys表示的是Key对象或Key对象的列表。
② put(models):将一个或多个Model实例放置到数据库中。参数models表示的是要存储的Model实例或Model实例的列表。
③ delete(models):从数据库中删除一个或多个Model实例。参数models表示要删除的Model实例、实体的Key,或Model实例列表,也可以是实体的Key列表。
④ run_in_transaction(function, *args, **kwargs):用于在一个事务中运行包含数据库更新的函数。若代码在事务处理过程之中抛出异常,则事务中进行的所有数据库更新都将回滚。参数function指的是要在数据库事务中运行的函数,参数“*args”是指传递到函数的位置参数,参数“**kwargs”是指传递到函数的关键字参数。
精彩回顾:
以上是关于《云计算(第三版)》精华连载14:Google应用程序引擎的主要内容,如果未能解决你的问题,请参考以下文章