如何为技术博客设计一个推荐系统(中):基于 Google 搜索的半自动推荐
Posted phodal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何为技术博客设计一个推荐系统(中):基于 Google 搜索的半自动推荐相关的知识,希望对你有一定的参考价值。
与统计学相比,基于内容来向用户推荐相似的内容,往往更容易获得。对于推荐来说,则有两种方式:
手动推荐
自动推荐
(PS:我承认,这句话说了等于没说。)
如下图所示:
手动推荐。在技术领域,作者通常比大多数读者更专业,他们往往知道什么是读者需要的。如,你看了一个 React 相关的文章,你可能会需要 Redux 相关的内容。
自动推荐。需要一些前提条件:融合现有系统的数据信息,获取一些用户的信息。随后,再计算出相关的内容,最后返回给读者。
而在这篇文章里,我们将介绍 :
标签生成的方式
基于手动标签推荐
半自动的标签推荐
全自动的基于内容推荐
标签生成
文章与我们平时使用的物品,有很大的不同之处。如手机,拥有固定的规格参数,价格、屏幕尺寸、运行内存(RAM)、机身内存、CPU、后置摄像头像素、前置摄像头像素等等,我们可以轻易地通过这些特征,了解用户大概需要什么东西。如果用户浏览的是 2880 的 某 pro 7 手机,那么某米 6 的手机可能更适合该用户。
而文章是一种非结构化的数据,除了作者、写作日期这一类的信息,我们很难直接描述其特性,也就难以判定文章之间是否是相似的。因此,我们就需要从文章中抽取出关键词,或称为标签,从而判断出用户喜欢的是某一种类别。
对于使用标签来向用户推荐产品的应用来说,标签生成方式有四种方式:
手动标签
机器生成推荐
用户手动标记(UGC)
混合学习式
手动标签
即,用作者、发布者手动添加相关标签,这种方式往往是最靠谱的。毕竟作者会比较专业,如文章《在 Raspberry Pi 上使用 AVS Device SDK 制作 Alexa 智能音箱》,对于读者来说,他们可能除了 Raspberry Pi,就不懂上面的其它东西,而作者标注了它的关键词(标签)是 avs device sdk、amazon alexa、amazon voice services、raspberry pi。从某种意义上来说,它相当于这篇文件的特征,从这几个关键词我们就可以推断出文章的大致内容了。
对于商品来说,也是相似的,在上架的时候,就拥有了相应的产品数据,如价格、类型、时间等等。
机器生成推荐
这种方式,会根据文章的内容、标题等信息,提取出相应的标签。再按一定的权重来计算相关性,比如标签中所含有的关键词,其相关性会比较强,那么其权重也应该比较大。那么,如果两篇文章里的标签含有的内容关键词相似,那么对于用户来说,他们也可能是相似的。这也就是,我们后面会讲到的『基于内容的推荐』。
用户手动标记(UGC)
对于那些没有内容的产品来说,他们依赖于用户手动标记的标签和评论。诸如豆瓣上的电影、图书等等,都只能由用户手动标记,才能找到相似的内容,并推荐给用户。
于是,这个时候如果一本新书没有用户评价,那么它可能就没有办法推荐给相应的用户。因此这些内容需要进行标签『冷启动』方面的探索,诸如生成一些标签等等。因此,对于那些不能由内容来判定用户喜欢的,则会在用户注册完后,让用户手机选择感兴趣的标签。
混合学习式
在手动标签的情况下,如果是 UGC 的内容,那么为了更多的访问量,用户可能会有意、无意地加上一些无关的标签。如 A 标签的关注用户比较多,相关的它的流量也会比较大,那么贴上 A 标签的文章,也会获得更多的关注。但是由于文章本身与 A 标签无关时,必然会导致用户的不满。而这个时候,如果普通的用户能判定该文章,是否是相关文章时,必然能某种程度上降低这种影响。
相似的,如上我们提到机器在生成标签的时候,也会出现一定的问题。因此,最好的方式就是结合上述的几种不同的标记方式。
基于手动标签推荐:标签数量相关
由于我使用的基于 Django 的 CMS 里,已经包含了后台手动推荐相关文章的功能。因此,我的想法是,先基于某几个特定的标签的数量,来筛选中相关的文章。
在我的第一个原型里,采用的方式比较原始:
获取文章的所有标签
对所有文章的标签进行统计,计数
获取文章标签中计数最多的 tag,查找相同标签的博客
在剩余的博客中,选择第二多 tag,再过滤剩余的博客
keywords_name = model.get_keywordsfield_name()
assigned = getattr(model, keywords_name).all()
all_keywords = Keyword.objects.filter(assignments__in=assigned)
keywords = all_keywords.annotate(item_count=Count("assignments")).order_by('-item_count')
# TODO: filter most popular tag
first_keyword = keywords.first()
if first_keyword:
first_filtered_blogposts = BlogPost.objects.published().filter(keywords__keyword__title__contains=first_keyword.title)
first_filtered_blogposts = first_filtered_blogposts.filter(~Q(id=post_id))
second_keyword = keywords[1]
if second_keyword:
blog_posts = first_filtered_blogposts.filter(keywords__keyword__title__contains=second_keyword.title)
return blog_posts[:3]
else:
return []
可这样的推荐算法会出现一些问题:如果同一系列的文章太多,如网上各类的 Vue 高仿站点,那么用户可能已经掌握了,文章的价值就没有那么高,或者可能如鸡汤一样没有价值。如在『玩点什么』的文章中,出现一系列的 home assistant、raspberry pi 相关的文章,它也不能体现出一些差异。
缺点
在站点内,该算法有其特定的意义:标签数量多。但是它并不能真正地解决用户的问题?能体现地体现出网站的价值,但是不一定是对于用户是有价值的。
假如用户搜索了一篇 raspberry pi + homebridge 的文章,那么它确实可以阅读一些相关的文章,而诸如 raspberry pi alexa gpio 从上图来看似乎是一个用户更加喜欢的选择。
而,在这种时候由编辑推荐出来的,反而比较准确。与商品不同的是,文章的手动推荐,往往会是读者可能感举的内容。那么,我们就能留得住用户,同时获得更可观的用户行为流。
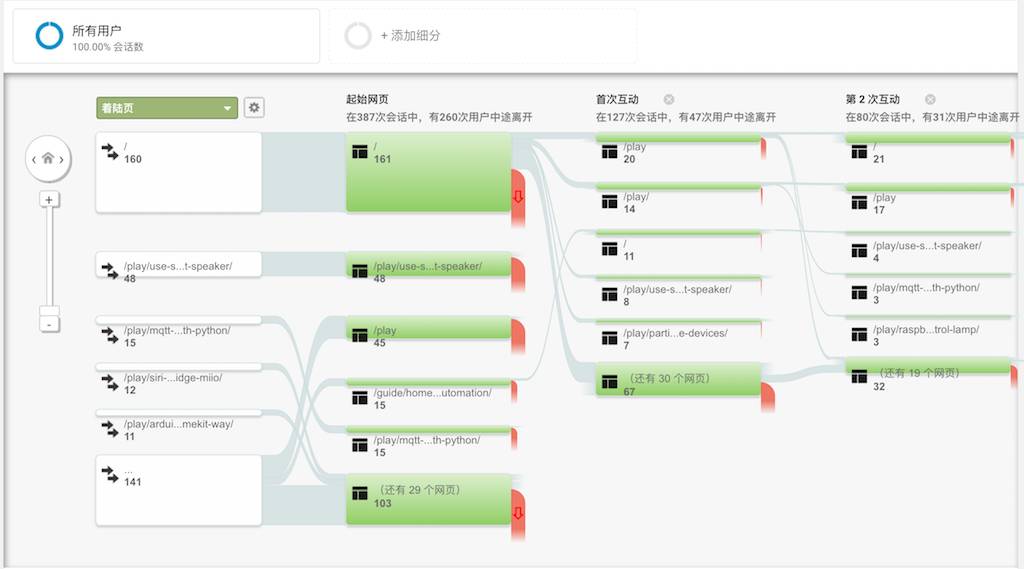
上图是『玩点什么的』用户行为流:
起始页面,在 387 次会话中,有 260 次用户中途离开
首次互动,在 127 次会话中,有 47 次用户中途离开
第 2 次互动,在 80 次会话中,有 31 次用户中途离开
这意味着,有 32% 的用户在访问了某个页面后,又访问了其它页面;而有 20% 的用户在上面的基础上,又访问了某个页面。如果能在这之上,完善推荐系统将首次互动提高至 50%,那么就会有相当可观的流量了。
为了改进我们的算法的准确性,这个时候我们可能需要一些额外的东西: 权重,于是就需要一个加权计算法。对于文章来说,有一种简单的加权方式,就是计算标题中的关键词。可是我强烈的怀疑这种方式,是不能真正地起到作用的。单一的关键词,只对于网站本身是有价值的,对于用户来说,则不是如此。
半自动标签推荐:基于 Google 搜索权重优化
于是,在我使用 Google Analtyics 的时候,我突然想到可以通过 Google Search Console 来获取用户搜索的关键词。即:
如下表所示,会在 Google Search Console 写明其相应的位置、点击率、出现次数等等的信息:
| Queries | Clicks | Impressions | CTR | Position |
|---|---|---|---|---|
| homebridge-miio | 7 | 28 | 25% | 8.2 |
| home assistant broadlink | 4 | 10 | 40% | 15 |
| amazon echo raspberry pi | 3 | 10 | 30% | 5.0 |
| raspberry pi homebridge | 2 | 6 | 33.33% | 7.7 |
| raspberry pi alexa gpio | 2 | 4 | 50% | 10 |
| nodemcu homekit | 2 | 3 | 66.67% | 13 |
| arduino homekit | 1 | 3 | 33.33% | 9.7 |
作为一个专业的程序员,我们搜索内容的时候,都会采用『关键词』这种面向机器的接口方式。而作为一个专业的 md 程序员及 SEO 专家,在编写文章标题的时候,我们也应该在标题上写上关键词。
如对应于上面的第一个搜索结果 homebridge-miio,它的标题是《Homekit + Siri 控制小米插座 :基于 HomeBridge 与 homebridge-miio》;相似的,用户在 Google 上搜索 home assistant broadlink 的时候,它对应的文章标题便是《Raspberry Pi + Home Assistant 智能家居(二):万能摇控 Broadlink RM Pro 红外控制所有家电》,以此类推。
因此,这才是真正有『价值』的权重。
更新权重
于是便下载 CSV,创建新的 model,导入到数据库中。然后,做了一个简单的权重算法:
第一个关键词 = 关键词次数 * 0.25 + 关键词查询次数 * 0.75
代码如下所示:
for keyword in keywords:
related_queries = Query.objects.filter(queries__contains=keyword.title)
keywords[index].item_count *= 0.75
if related_queries:
for query in related_queries:
keywords[index].item_count += query.clicks * 0.25
if index > 1 and keywords[index].item_count > keywords[index - 1].item_count:
top_rank_keyword = keywords[index].title
index += 1
代码中的,第二个关键词则仍然是『按频率取词』,如果出现与第一关键词重复,则选用第二频率的关键词~~、
考虑了 Google Search Console 的搜索结果相当有意义。便顺手也做了一个相关性搜索,当用户搜索 Raspberry Pi,那么它可能还会结合 Arduino ?? 那么,它可以在网站的右侧,为用户显示出可感兴趣的搜索内容。
相关搜索
不过,这个关键词表的最大意义在于,找出用户最需要的关键词;同时,也能帮我们找到,那些能在 Google 排到个好位置的词语。
上一篇《》
更多推荐系统相关的精彩内容,请期待下一篇『基于内容的推荐与协同过滤』。
以上是关于如何为技术博客设计一个推荐系统(中):基于 Google 搜索的半自动推荐的主要内容,如果未能解决你的问题,请参考以下文章