毛剑:Bilibili 的 Go 服务实践(上篇)
Posted GoCN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了毛剑:Bilibili 的 Go 服务实践(上篇)相关的知识,希望对你有一定的参考价值。
前言
在微服务流行的当下,bilibili(B站)也在业务快速增长的压力下,对历史系统进行了不断的优化,在所谓“大系统小做”的背后付出了挺多的努力,尤其是 Go 作为开发语言的整体运维的支撑相对比较薄弱,例如开发、部署、测试、集成、监控,调试等。在 GopherChina 2017大会上,B 站技术总监毛剑分享了微服务化道路上踩的“坑”以及最终演进后对整个微服务框架的思考。
本次演讲的内容会包含以下几块:1.B站微服务的演进过程;2.高可用;3.中间件;4.持续集成和交付;5.运维体系。
作者介绍
2015年起,在 bilibili(B站)负责 UGC平台和基础架构,开发了直播弹幕开源推送服务 goim ,B站分布式存储 BFS ,引导开发了B站 cache proxy,bili twemproxy 等,对历史主站架构进行迭代和重构,之前六年在猎豹移动工作,当过mysql DBA,做过C开发,其中开发了gopush-cluster用于猎豹移动的推送体系。喜欢应用服务性能诊断,内核研究,稳定的服务端架构演变。
微服务的演进
原始框架
在刚进入 B站时,面临着技术架构上的一些挑战:首先是部署非常不方便,我们要在没有任何东西依赖的情况下把整套主站搭起来;然后代码方面有两个仓库,要部署的时候全部打包一块往上面扔,结果经常起不来;另外测试的成本也非常高。这样导致的后果是整个开发效率也比较低,因为职责不清晰,整个代码是一坨,不知道哪一个模块是谁负责,甚至有一些是公共的部分是很多人在负责。如图1所示。
升级理念
首先要梳理业务的边界。因为整个B站的业务非常繁杂,我们先从全貌去看到底应该怎么拆分。所以我做了一个图,如图2所示。

图2
最顶层从我的视角看,一个是用户纬度,还有一个帐号,你从中间的服务看,它有会员、投稿、用户财产信息,还有关系链、动态推荐等。从底层的一些辅助服务看,有验证码、IP的查找、推送、配置中心,包括protobuffer的一些服务管理。
为什么要强调这个事情呢?就是起步做微服务的时候,一定要搞清楚整个业务的责权或者叫边界。我们一开始的打法就是农村包围城市,跟所有核心有关的业务逐步拆了。比如用户的播放历史、收藏夹、评论等,这些是跟我们主线没有直接关系的周边业务。先把这些做了。在升级的过程中一定要考虑一个兼容,不能做了一个api跟所有的不兼容。直到现在,我们涉及到最底层的帐号重构的时候,都是非常痛苦的,因为牵扯的部门非常多。
第二个就是资源隔离。怎么隔离呢?就是先买服务器,尽量不要跟不可靠的程序员写代码放在一块,先隔离出来。因为旧代码肯定有很多黑科技的,你先买一个新机器放在那里,你新重构的往这里面塞,老的就不要折腾了。而且在没有文档、什么都没有的时候,旧代码是很难复用的,最好买一个干净的新机器重新部署。
第三个是内外网服务隔离。之前B站在15年的时候也遇到一些安全事故,我们的APP KEY从客户端逆向被泄露,有人去请求了内网的一些接口。这是一个安全事故,也是一个安全风险。为什么出现这个问题呢?因为我们之前没有做内网的隔离,导致内网API就暴露在公网。因为我们当时就决定要把整个服务的职责梳理清楚。
如图3所示,我们从最顶层开始看,首先是SLB入口,进来以后回到 Gateway。举个例子,像我们的移动端对外的一些API,因为有些业务要在一个页面有很多聚合,所以我们封装成一个API。还有就是用户评论,是平台属性的可以直接对外提供API。但是有一些服务是不能对外的,比如像我们内部的服务和面向运营平台的运营审核操作。例如我们的运营平台要给某个帐号进行操作,这个时候一定不能对外的,不然如果有人发现这个接口,无论你用什么手段,他一定有办法来搞你。所以一定要做内外网的隔离,这几个角色定义完以后,Service这一层,其实我们看到微服务的最核心的一块,就是直接面对面的,就是业务的一个模块单元。
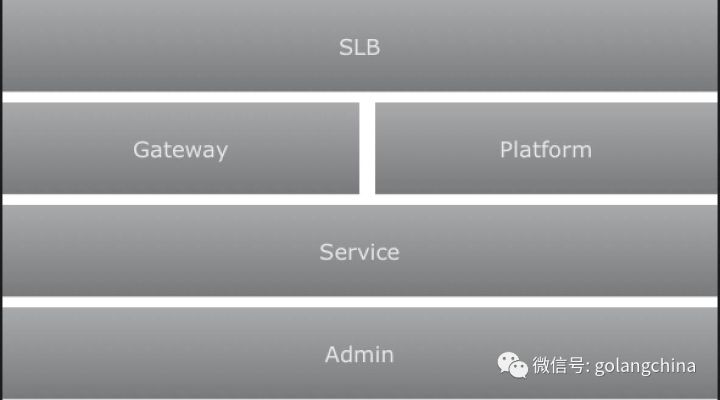
图3
接下来讲一个RPC框架。那RPC需要哪些特性呢?首先需要序列化,第一就是使用GOB,我第一个想法就是语言统一,尽可能多的是用Go来写。因为当你出现一个业务短版或者瓶颈的时候,发现这个人不会写Go,会很困难。Go统一之后,我们想用GOB是最方便,因为它什么内置类型都支持。第二个就是超时控制。因为一堵就挂了。假设你有一个提供者,他后面堵了,你越积越多,就挂了。所以要有一个超时控制,包括一些上下文的东西传递。像刚才说的APM的问题就可以通过上下文来控制。第三是要做一些拦截器,所以内网也要做一定的健全机制,包括权限控制、统计、限流等。第四是服务注册,我们当时对比了很多,最终选择的是 zookeeper,这块也在逐步改进去ZK,做一个AP系统。最后是负载均衡,这个地方也考虑了很久,像早期我其实使用像 LVS ,或者 DNS 来做这种调度的,但是这样从性能来说它并不是最好,因为假设你要用LVS,你要经过你的网络多传输几次,其实直点效果是最好的。但是因为当时成本的问题,所以我们用客户端负载直接实现的。
代码级实现
刚才说到用GOB,用GOB以后我们最合适的RPC是用标准库的net rpc,并对它做了一些改造。
首先是支持context,再一个是做了一个超时控制,这是两个测试的demo。如图4-1。
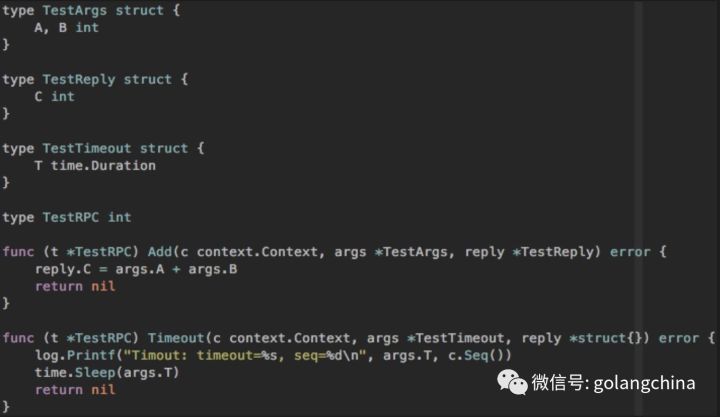
图4-1
有人问我这个东西改造是不是很困难,其实我们看了 net rpc的源码,整个实现非常简单,所以我们只要改极少的代码,风险比较小。
首先加了一个 context 对象,第一个参数必须具体实现一个 context 接口,就做了一步这样的改造就搞定了。我们所有的rpc方法首参数都是 context 。如图4-2所示。
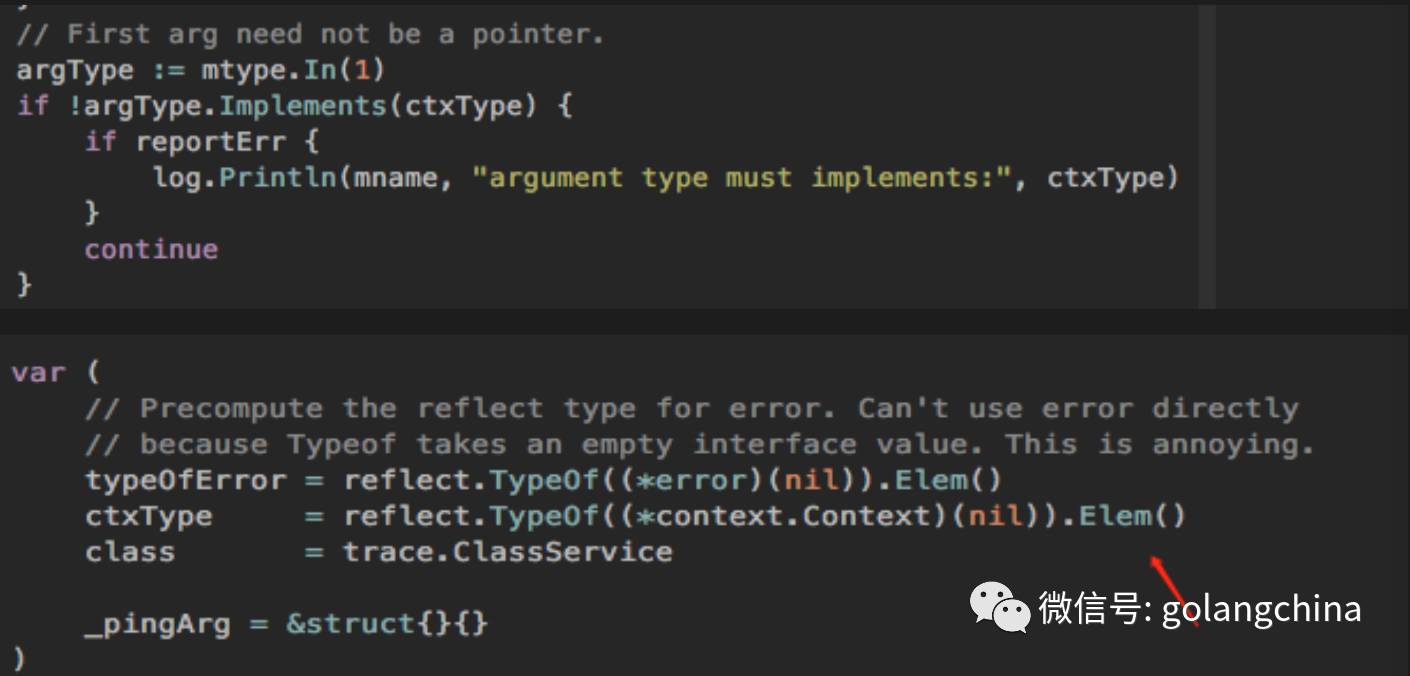
图4-2
图 4-3 一开始也是一个 context 的注入,我们在里面放了比较多的东西,像方法、名字等等。我们对外的 context 其实内部有一个 rpc 的小的 context,放了我们可能会用到的一些东西。拦截器其实也比较简单,首先我定义一个抽象,有限流、有统计、有健全,然后我们在 rpc 库里面 server 端加入几行简单代码。
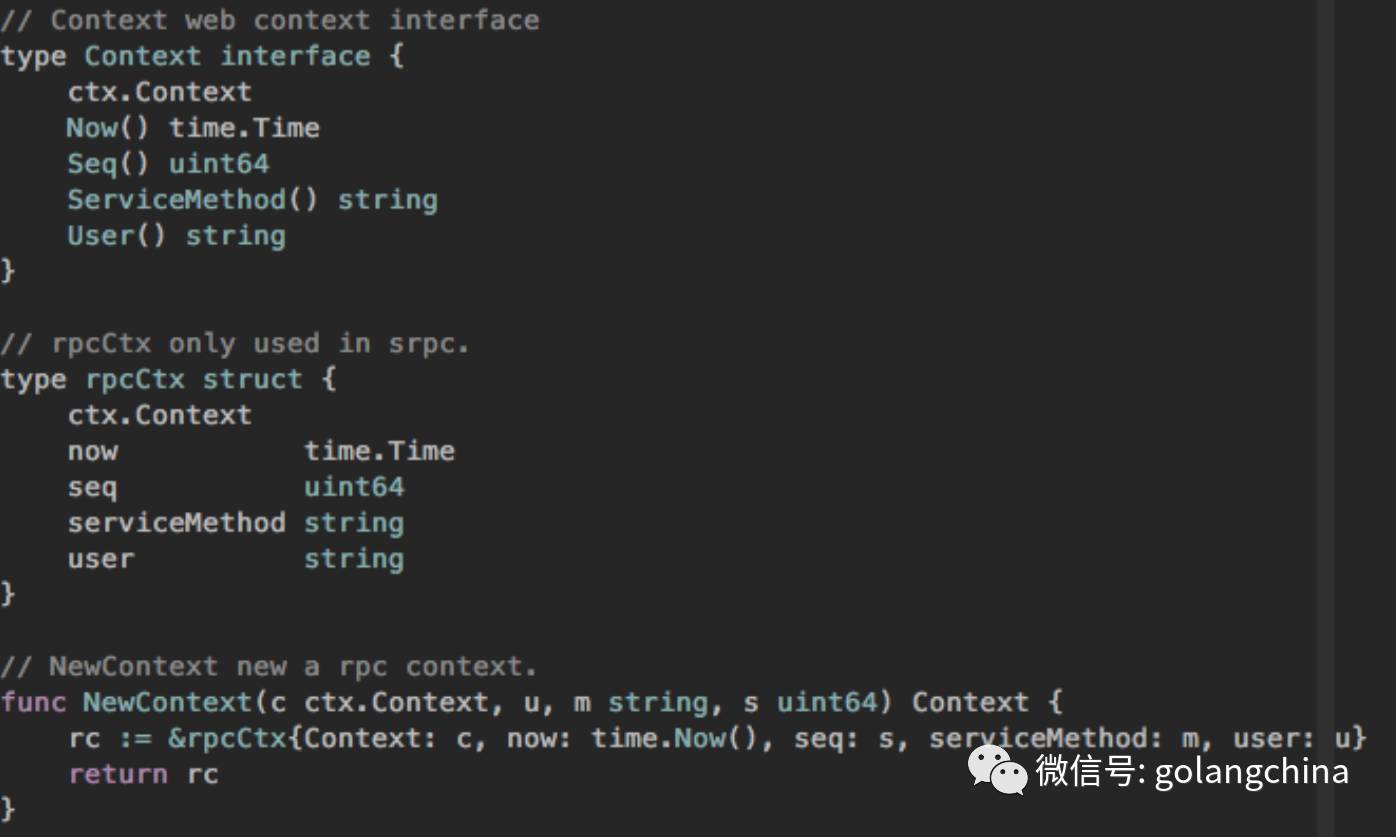
图4-3
然后我们还做了一些改进。首先如果大家压测过 net rpc,就会发现 get request 和 free request 是有全局锁征用的,所以我们把它改成一个 request scope 级别的一个优化。如图4-4右边,我们在 codec 里面把 response 和 request 放进去了。而且我们为了减少对象,不是用的指针,而是直接用的 struct 包含来做的,这样压力也会小一些。
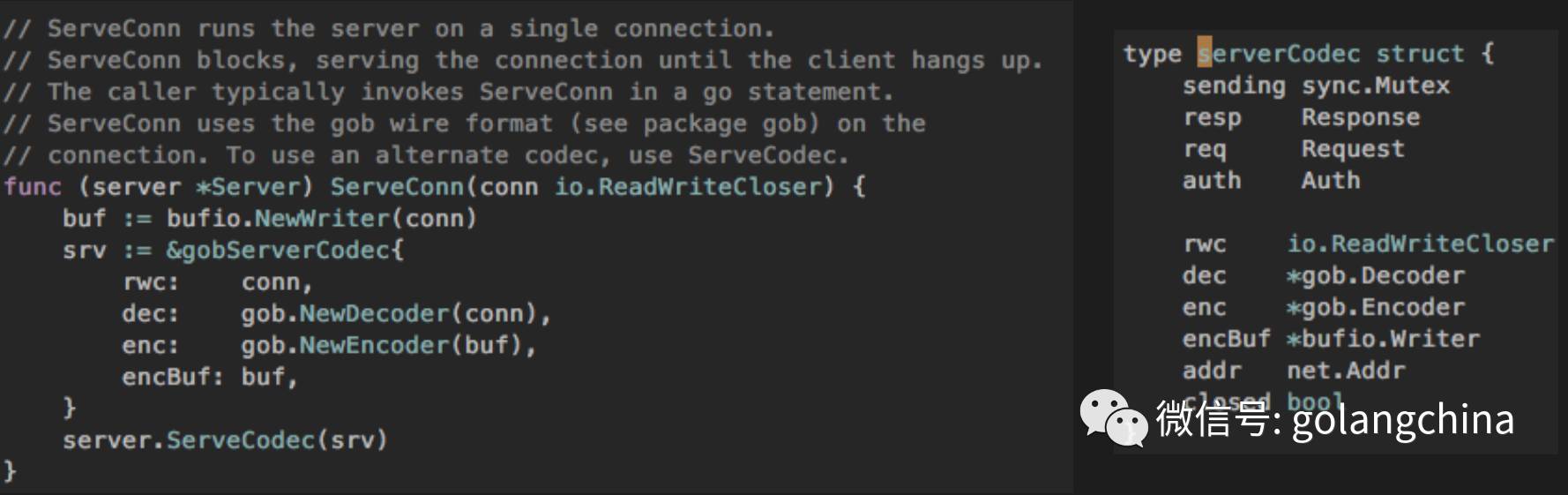
图4-4
然后看一下握手。如图4-5所示。
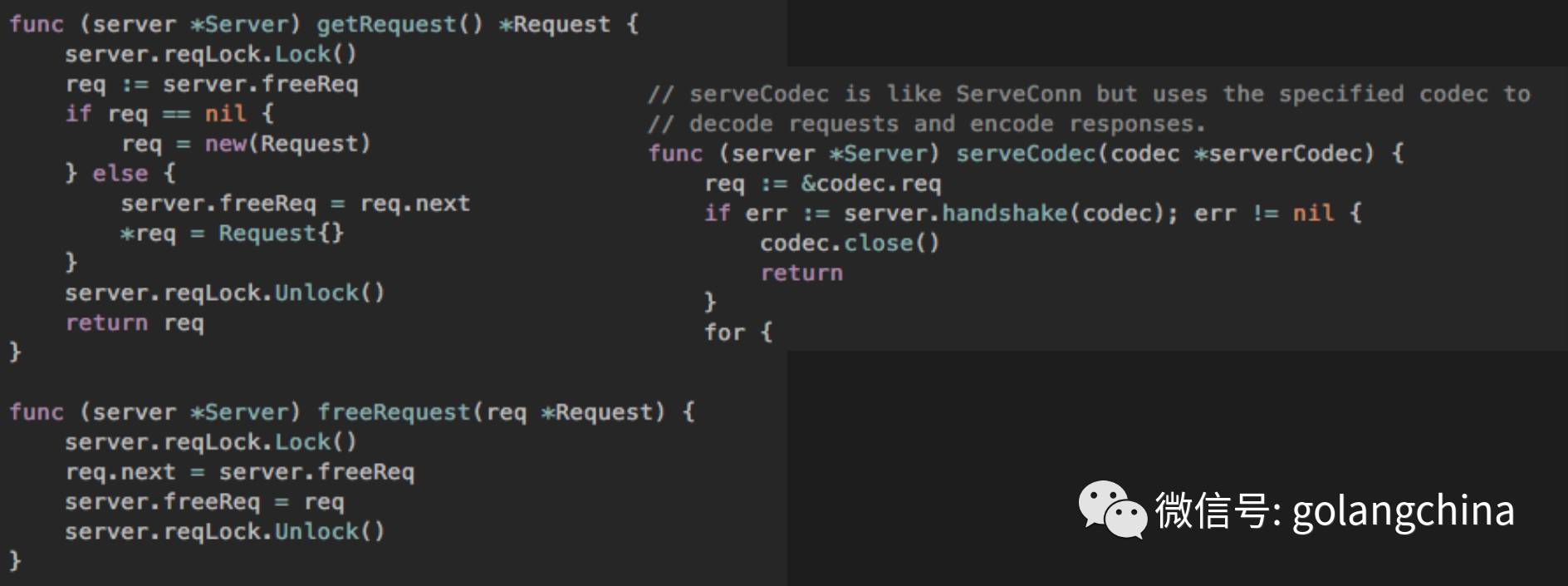
图4-5
Group其实是后面一版加入的,等下我讲高可用的时候会重点来介绍。
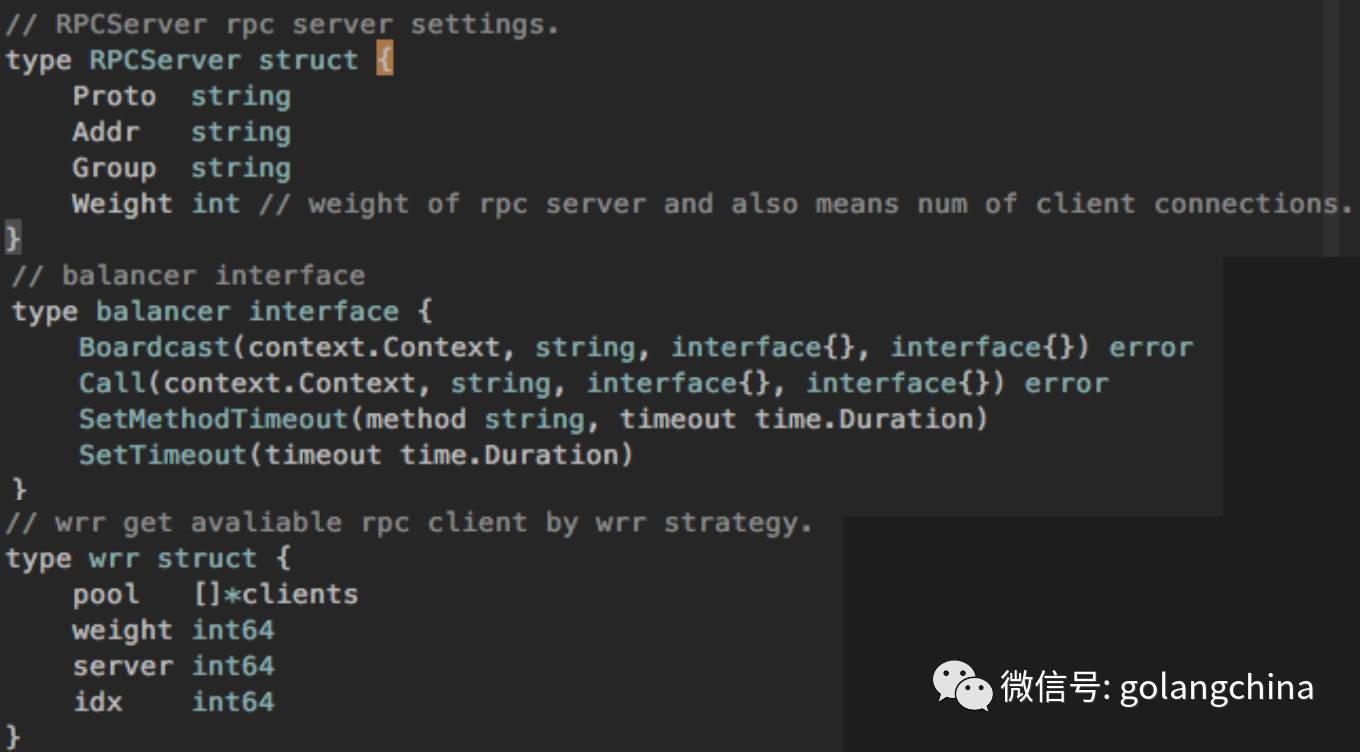
图4-6
刚才我们是服务层搞定了,现在看一下网关层。网关要做聚合,回到刚才的场景,移动端的某个页面调了4、5个业务方,这不可能让移动端的同学直接对接。我们会从 Gateway 层统一做一个 API 给它,这样成本会非常低。协议的统一也在 gateway 层做的。
第二步我们做了并行优化,因为我们依赖的业务方非常多,有4-6个,所以要用 errgroup 做一个并行调用。Gateway 的话有两种做法,我们早期所有出口只有一个Gateway,后来发现不行,一个不小心的 bug 可能导致这个进程崩溃,然后它不断崩溃,其实非常危险。所以我们根据一些业务形态重要或非重要等做了一些隔离。它可能叫 APP Gateway,会员 Gateway,我们还是做了一些隔离的。最后的话就是我们在 Gateway上做的一些熔断、降级、限流、高可用等等。接下来就重点讲一下高可用的做法。
高可用
第一个是做隔离。我们看图5,首先是按业务的压力情况,有一些服务压力特别大,有一些服务压力特别小,它是不是可以隔离出来,这样不要因为压力大的服务影响应该小的,然后稳定性高的影响稳定性。
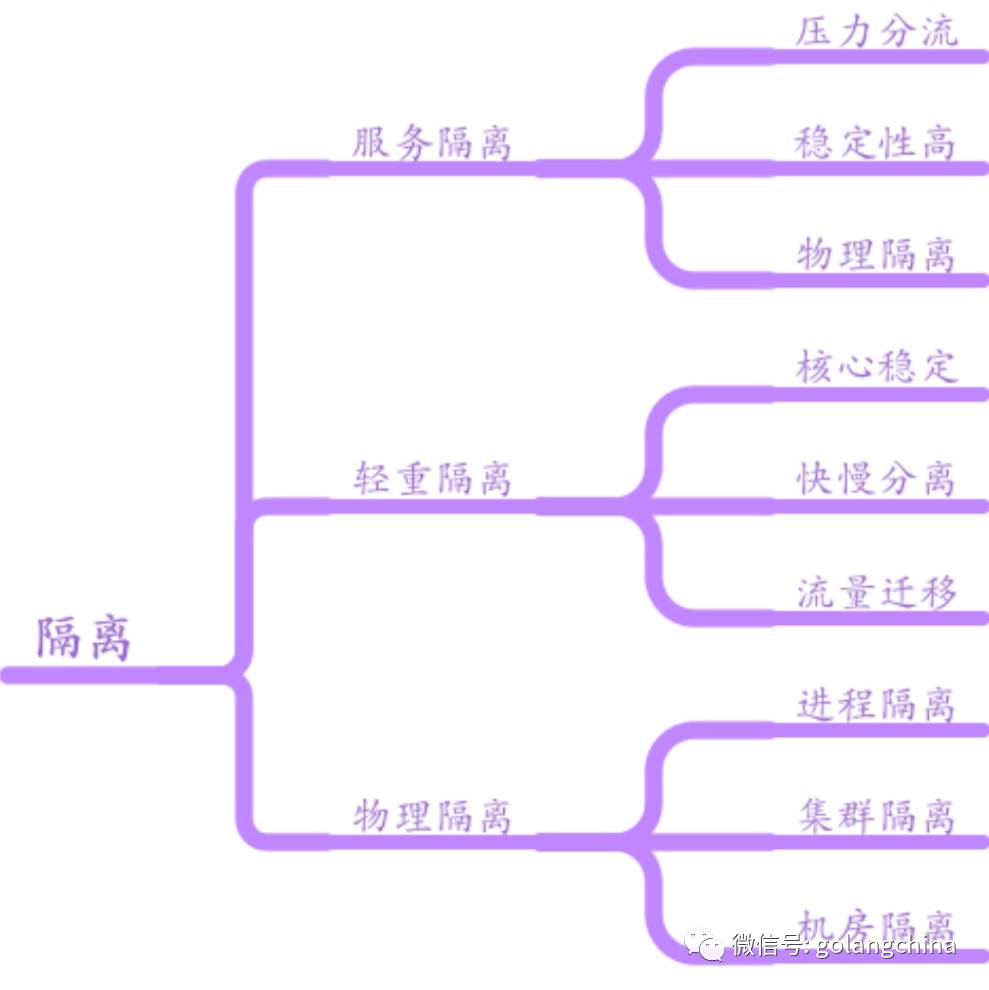
早期没有服务器时,其实都是统一布在一台机器上,有可能AB两个服务,A出问题了,B跟着遭殃。其实经历过一段时间没有容器,就是用物理机的阶段是非常糟糕的,真的要用手动 cgroup ,然后限定每一个资源。那么物理隔离就是买机器。轻重隔离的话,像我们有一些队列可能东西非常多,有一些队列可能东西非常少,如果你都放在一个里面 Topic ,还是有影响的。举个例子,像我们视频转码的时候,它会有分超长和超短的文件。如果超短和超长的放在一种队列里面,它其实就是一种轻重隔离。像我们的集群,甚至有不同的部署,也是腾讯经常提的按集群部署。
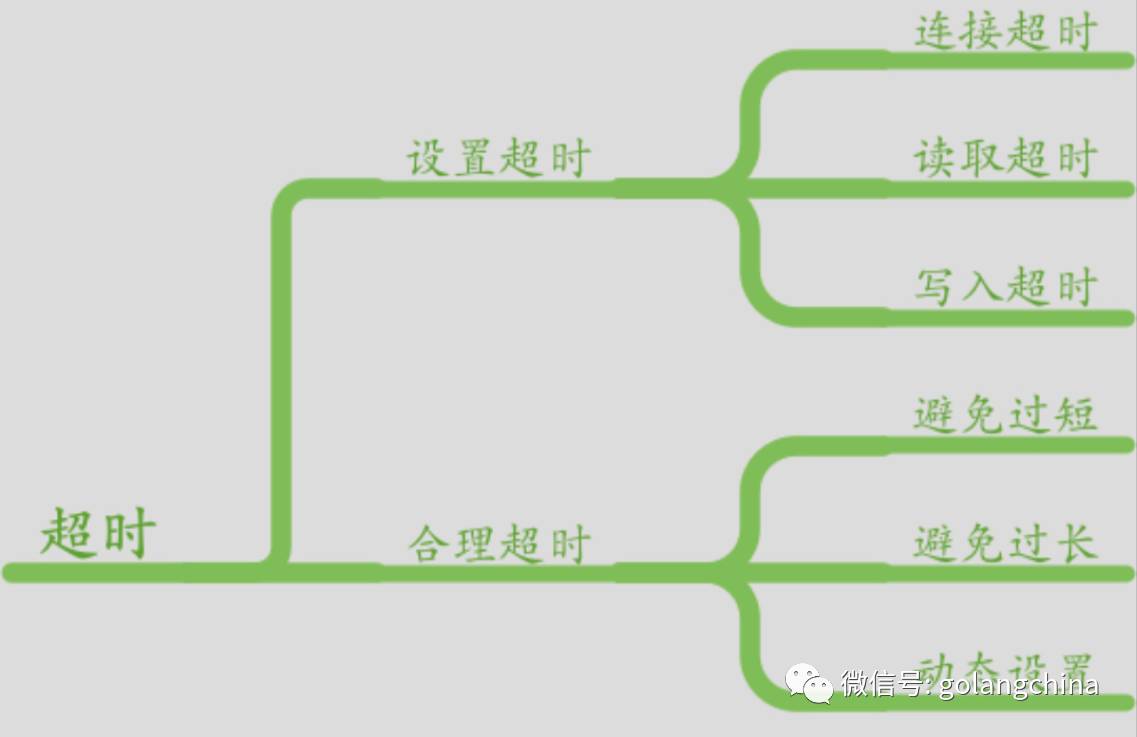
第二个要提的就是超时。因为RPCE里面,最重要的就是超时,超时有很多种,如连接超时、读取超时、写入超时等,如图6所示。我当时用 Go 1.3 开始用 Go 写代码,当时发现很多地方是没有的,导致我们有一次出现了一个故障,就是某一个机房的业务连了一台 DB ,当时那个线断了,导致进程全部堵住了。具体是怎么排查的呢,因为我们发现CPU不高,然后数据库报了一下错,之后请求也进不来,后来还是用 GDB 去调,看它正在运行的 gorutnine 的对帐到底卡在哪里,当时还有一些其他的方法。后续的引进,我希望对我们采集到的数据,不断的对我们的服务去调整这个超时。
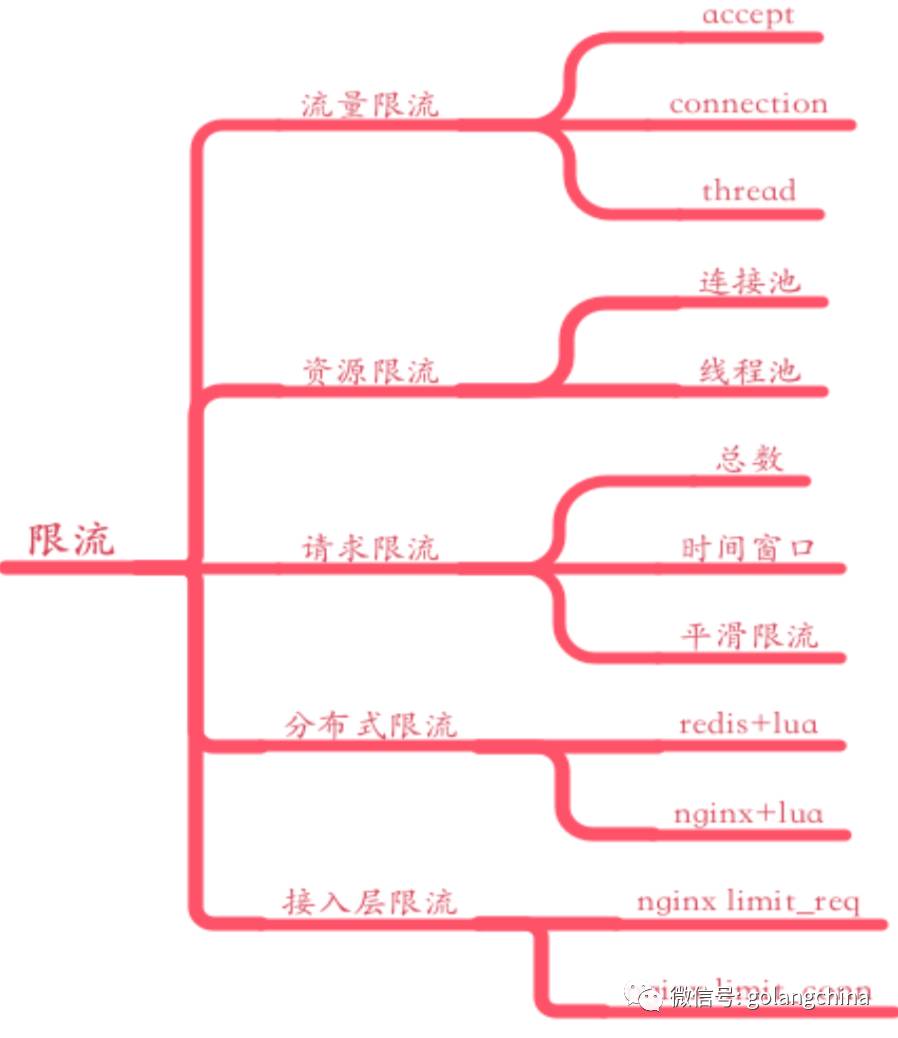
第三个就是限流。限流也非常多,如图7所示。举一个例子,我们在去年应该说有一个业务夯住了,具体什么问题呢,挂的是上层 nginx 的 upstream ,因为它没有设置 upstream 的一个 timeout,导致我们的交换机对着三四百个连接,然后交换机挂掉了。发现之前说好的交换机有在备,结果也全部挂掉了。所以我们后来总结了一下,还是要有限流保护的,限流就是避免一波CC攻击就直接把你打挂了。所以我们在这上面做了分布式的限流,类似的方案都有。我们的连接限流,这些都是重要的资源,一定要注意。像 Go 的话,有一个指标里面就有一个限流连接数的,这些都可以使用,避免一下子拖了太多的连接进来把你打死。像请求限流,当发现情况的时候立马调整它的流量,把你打的 CC 的那个流量给去掉。
然后提一下降级。也是非常多,如图8所示。我们早期的话,第一步做UI降级,我们每次发生故障时,发现如果你的移动端打不开,用户会疯狂的刷,可能刷一会就打开了,其实这时候请求数会越来越多。后来我们在客户端做降级,比如你连续刷的话,我会下达一个 TTL ,这些可以在客户端做一些调整,如果实在扛不住的时候可以发一个10秒钟,甚至30秒钟的超长的 TTL 告诉客户端这时候不要请求。我记得支付宝不是收到一个好像太忙了不让你支付还是什么,其实就是有客户端的一个限流,这个是终极手段。
还有功能降级。也比较简单,比如我们某个页面上面有一些大数据,或者人工智能的推荐的数据,这个模块可能会导致某一个实验导致数据的崩溃了,所以这时候就有一些空窗,或者整个页面都打不开,这个体验就不好。那这时候就有很多的方法,比如可以把另一块 UR 返回一个灾备的推荐池,至少避免整个页面打不开。所以你的接口吐出去的时候,如果有一个依赖的业务方挂掉,你一定要考虑你有没有一些手段可以降级,或者是返回一些默认的、甚至返回静态的数据。
我记得京东有一篇分享就讲过,他们如果出现非常严重的故障,商品的详细页是可以返回一个静态的。因为我们商品的很多东西是不可能实时变更它的内容的,我觉得这也是一种方式吧。那还有一些自动的降级,我们其实做的比较多的是像统计失败的降级。比如我请求某一个接口,它如果错误率比较高,或者超时比较多,我是不是可以不调它了。虽然你依赖了很多业务方,你可以降级,但是如果它超时,其实你最终的延时也会增加,所以这时候要把它踢掉。
还有一些情况,比如我们核心业务,或者是一些关键的业务不能做自动降级的时候,这时候你拿捏不准,你一定要做一些功能开关,在适当的时候可以把它打开,不再返回那个数据,或者不请求它。
最后就是容错。如图9所示。容错我们做的比较多的就是熔断,其实也有参考一个 Java 框架,把它改成了 Go 的版本,然后做了一个熔断。其实它的核心思路非常简单,就是当我的请求数量达到多少以后,我的错误率到达多少以后,我是不是可以不调它,不调就可以快速返回,叫 fail-fast。fail-fast 这个阶段一过,我是不是要放一些流量进去试探它有没有恢复。这时候比如100毫秒放一个流量进去,如果成功了,我认为服务器稳定了,再把开关打开,把整个流量放进去,再看如果还不行,会重复这样的过程。
图9
还有一些重要业务,像我们依赖队列的一些业务,它可能会做努力送达模型。这种情况下,我们可能会无限重试,直到它成功,否则就是一直等待。一秒钟加一个随机数,不断的去重试。
由于内容篇幅较长,本文分为上下两篇,在明日发布的下篇中会介绍 B 站在中间件、持续集成和交付,以及运维体系中的实践,敬请期待~
以上是关于毛剑:Bilibili 的 Go 服务实践(上篇)的主要内容,如果未能解决你的问题,请参考以下文章