数术|产品聚类方法初探(基于Google Analytics中的数据)
Posted 触脉咨询
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数术|产品聚类方法初探(基于Google Analytics中的数据)相关的知识,希望对你有一定的参考价值。
关注“触脉咨询”,关注数据前沿!
触脉导读:Google Analytics在电子商务网站上监测数据可以获得非常全面的产品销售数据,如果结合正确的聚类方法如K-means或层次聚类,能让这些数据发挥出更高的价值。本文将会完整分享从拿到数据-处理选取数据-聚类并得出结论的过程,如果你已经开始探索产品聚类的价值,不要错过这篇文章哟~
聚类分析是商业数据分析中最常用的一类分析技术了,无论是将你平台的活跃用户分层区别经营,还是已上架商品进行归类进行策略调整都非常适用。它的原理根据已有的数据样本的信息寻找相似的数据结构(距离相近),并将其归为相似组的的过程。因为该数据样本往往不具有特别明显的目标特征,所以聚类算法在机器学习领域中被称为无监督学习。
0.确定目标
本次案例是根据 Google Merchandise Store 8月产品销售业绩数据来为产品提供分析支持,对产品进行较为细致的分类,并尝试给出优化策略。
1.数据选取
网上下载数据集一般都有较好的分类特性,为了获取到真实商品销售数据的来源,我们使用Google Merchandise Store 8月的商品数据。那么问题来了,怎么获取到这些数据呢?别着急Google 名下有一款网站行为监测工具,为了让用户更好体验这款工具,Google 还非常贴心的给你一个网上商城的演示账号,里面的数据都是商城真实访问的数据。其中“转化”电子商务报告中提供了超过60类维度和指标,除了默认报告之外,你还可以根据实际业务自行提取对产品分类有用的指标和维度做成自定义报告。最后说一句,这款工具免费、支持中文。
演示账号入口:
访问演示帐号(链接:https://support.google.com/analytics/answer/6367342?hl=zh-Hans),需科学上网
在 BI 界面中它长这样:
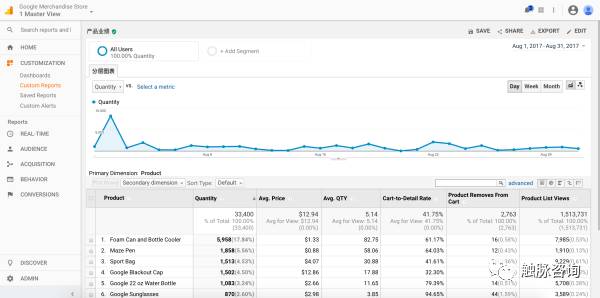
本次在 GA 中选取的字段如下:
 有人问,为什么不用GA 中默认报告的数据,我会告诉你我用过,但因为指标具有多重共线性导致分类结果不佳么?比如默认报告中“产品收入”、“销售产品数量”、“唯一购买人数”这些维度具有相当大的正相关性,如果不经过处理直接喂给模型,很容易造成过拟合。
有人问,为什么不用GA 中默认报告的数据,我会告诉你我用过,但因为指标具有多重共线性导致分类结果不佳么?比如默认报告中“产品收入”、“销售产品数量”、“唯一购买人数”这些维度具有相当大的正相关性,如果不经过处理直接喂给模型,很容易造成过拟合。
2.选取聚类方法
2.1K-means 聚类
K-means 聚类算法是最经典的无监督聚类算法了,原理算是简单,知乎上已经有很好的回答了,大家可以去找找,不过多赘述了。

算法优点:简单——只需要设置一个簇点参数 K;有效——对大型数据集有比较好的处理速度。
【要注意的坑】算法简单带来的就是聚类的不严谨性——K-means得到的聚类分组往往是局部最优解,最终聚类结果很大程度取决于初始随机点的选取;不仅如此,K-means 是计算每个特征之间的举例,所以如果特征为无序分类数据,那么这个聚类结果就不会很准确了。如为流量来源数字化,baidu=1,google=2,sogou=3,问题在于你无法证明以上三个渠道来源谁优谁劣,数字的度量对他们没有实际的意义。其他诸如对凸型数据处理较好,容易忽视小类别的点,对噪声数据敏感等缺点
解决方案:局部最优解——多尝试 K 参数的选择,多次测试看分类效果是否稳定;特征中存在无序分类变量——去除该字段或者尝试用其他有序变量去描述它(如从跳出率、访问时长、转化率来描述渠道的质量高低)
2.2层次聚类
层次也是我们最常用的一个聚类算法,分凝聚式层次聚类和分裂式层次聚类2种,这里我们使用凝聚式层次聚类,用来处理和验证 K-means 聚类后关系的紧密性。

算法优点:非常容易解释,把图放出来跟老总讲讲就明白了。
【要注意的坑】因为算法的计算复杂度,所以不适宜用来处理大型数据。比如用来对大量用户进行分类,会耗费很多时间,而且结果会异常繁复难以总结,故在此我们使用层次聚类验证 K-means 聚类后效果。
3.数据预处理
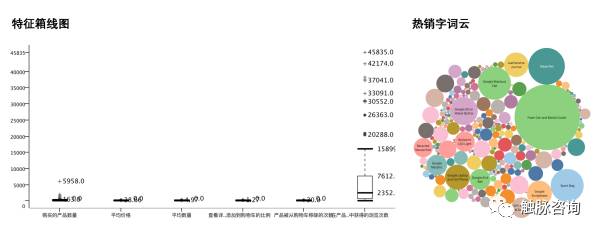
在数据开始处理之前,我们必须事先熟悉样本数据集的特性,从上图我们发现至少2个问题:
· 各个维度数据范围不一致,必须事先对数据标准化:
由于 K-means 是依靠样本点之间的距离来进行分类的,所以必须进行数据标准化。如果不做标准化处理,那么算法会倾向判断数值较大的特征(比如列表页浏览次数),而对范围变化较小的特征视而不见(比如平均价格),这对数据聚类结果有较大影响。
· 筛选离群点:
热销字词云的图中,我们可以看到Foam Can and Bottle Cooler这款产品销量很多,聚类分析对离群点比较敏感,因为如果不做任何处理按照普通样本去聚合的话,会影响类别中心点的位置,所以在处理数据之前必须将离群点的数据剔除。
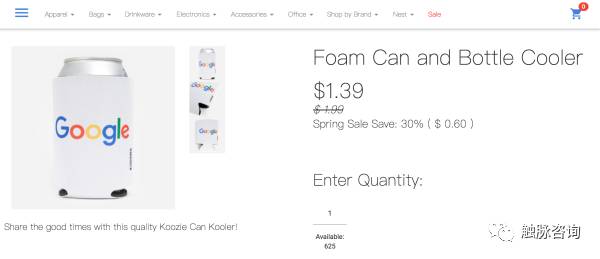
4.模型处理
比如上面这货:当 K=3时,该产品就被单独区分为一种,下图红色的点:
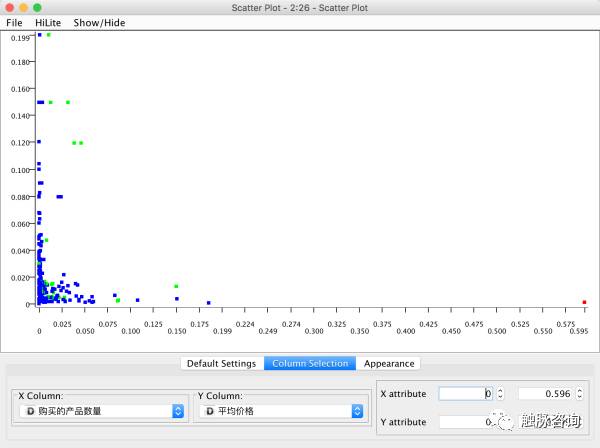
我们将这个商品剔除后,对剩余产品做聚类分析,我们另 K=7,得出维度-分类分类结果如下图(纵坐标为类别组,横坐标为维度):
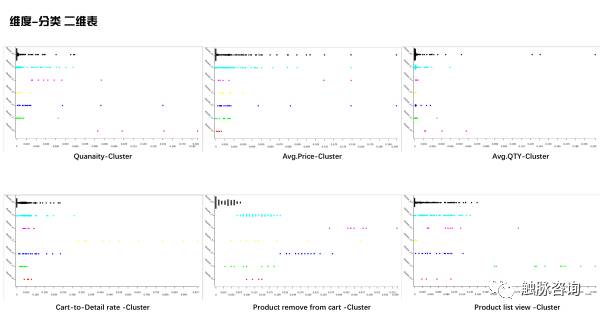
分析结论——K-means
上图可以看出每类样本点在不同维度分布状态,举例来说,黑色类与青色类,在除 product remove from cart之外所有维度均是相同分布,其中黑色类铲平从购物车移除的次数明显小于青色类。为了更详细的区分各类的区别,我们可以查看7个分类的中心点(以下数据经过了逆标准化进行还原):
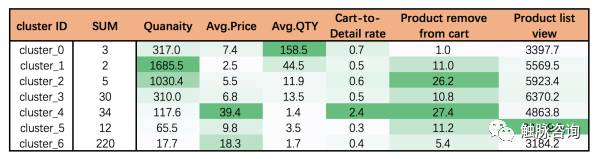
从上表中7个分类的中心点我们可以看出一些端倪:
1. 分类cluster0-2、cluster5都是小样本聚类,之所以能够形成一类,是因为某类指标特别大:比如cluster_1和cluster_2的 Quanaity(销售数量)就比较大,cluster_5的Product list view(产品在列表页被浏览的次数)就非常大。
2. 因为是最初级的聚类算法,我们仍然可以看到不同类别存在一定的相似:比如 cluster_1和cluster_2的区别在于cluster_2比Product remove from cart(产品被移出购物车的次数)几乎是cluster_1的2.5倍。
3. 分类后的样本数量悬殊巨大,这固然反映了真实的销售场景,同样也可能受制于样本的数量,本次只选取了时间窗口为8月的销售数据,如果某些商品因为数据量太小,也可能导致该分类被并入了相邻的大类当中。比如本季度畅销T恤和即将来临的秋季外套,算法会更偏向于 T恤的分类。
5.一些改进
最后我们尝试着将这些分类好的结果喂给层次分类算法,因为我们看看这分出的7个品类中,哪些特征接近,又有什么特点:
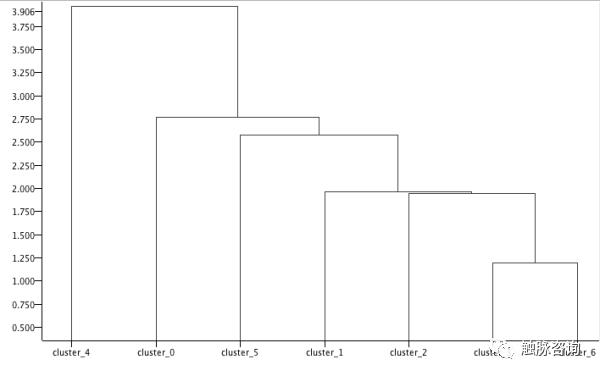
从上图中我们又可以发现:
1. 你看 cluster_4是最后合并的一类,那么说明它离其他的点都非常远。为什么啊?其实我们回头看看cluster_4的中心点,这类商品平均价格昂贵,看过详情的人加入了购物车比其他类别高2~3倍,但是从购物车中删除的比例也不低,这样问题一分析是不是很清晰明了了?
2. 也许有人会疑惑,cluster_3和cluster_6从中心点上来看,并非完全一致,为何会最先被聚合,这与距离算法有关系,因为相比其他分类来看,他俩的确是最接近的。
3. 从层次聚类的纵坐标高度来看(两分类结合的高度越高,差异度越高),其实cluster_3和cluster_6相似度也并非很高,也能佐证上一条观点。从差异度来看cluster_0和cluster_1两个分类与新结合的分类差异度较小,说明该分类可能位于先前N分类的中心位置。
6.优化策略
最后是优化策略,给两条最明显的:
1. 优化cluster_4和cluster_2的商品的购物流程,因为用户不会无缘无故的添加购物车之后删除它,除非购物流程出现问题或者网站引诱用户误点,亦或是关键信息没有一开始展示(比如,下单时才提示我所在的地区无货)
2. 对于 cluster_5类的商品,它在列表页获得了远多于其他类别商品的浏览(高7~8倍),但是带来的销售数量却并非很高,考虑到该类商品平均价格也不是非常出众,是否可以适当调整该商品的展示位置,把机会留给更会盈利的产品呢?
欢迎各位小伙伴们留言讨论~
数势|数据领域的宏观趋势解读
数道|数据行业的理念与价值观探讨
数法|数据分析的思维框架与方法论
数术|数据分析的方案与技术
数器|数据分析的工具应用心得
数八|数据视角的理性八卦
大家阅读完上述的文章,咱们来点轻松的话题吧~
触脉和谷歌将一起合办的关于出口电商、海外购物数据分析线下沙龙活动!千载难逢的机会,还犹豫什么,赶紧报名吧!
10月12日,出口电商备战海外购物季主题干货分享,一起来谷歌上海办公室现场体验如何用数据延续你的成功之道!
席位有限,点此“”,或者直接拨打“400-080-5098”,免费参加哟!
以上是关于数术|产品聚类方法初探(基于Google Analytics中的数据)的主要内容,如果未能解决你的问题,请参考以下文章