sql 怎么取不重复的数据的所有数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql 怎么取不重复的数据的所有数据相关的知识,希望对你有一定的参考价值。
SQL数据重复分几种情况,一种是原数据重复,第二种是粒度重复,第三种是分布重复。原数据重复的情况,你直接可以distinct掉,例如,学生表当中有两个重复的学号,你想取出不重复的,直接可以写:select
distinct
学号
from
学生表
第二种是查询粒度重复,比如你有一张表是存储区域的,分别为省、市、县三列。而你需要的是只查找不同的省市,则也可以使用distinct:select
distinct
省,市
from
区域
第三种则是分布重复,比如在join
的时候,左右两个表格存在一对多的关系,造成的重复,或者在聚合之后出现了维度重复,则这种相对来说比较麻烦,你需要在子查询中统计或查找出唯一值,然后再去关联,或者是按照一定的数据需求的取数规则,在查询结果后再进行聚合,取到唯一值。
不过不管怎么样,都是要看实际需求是什么样子的。大多可以用子查询和关联联合解决。 参考技术A 表table1(a,
b),a列是主键,b是你说的关键字段。
假设你要插入一条新记录(a1,
b1):
/*
判断数据库中是否有b=b1的记录
*/
//
此sql语句取出数据库中所有b=b1的记录
string
sql
=
"select
*
from
table1
where
b=b1";
sqlcommand
cmd
=
new
sqlcommand(cmd,
sqlconnection);
//
运行sql语句,并获得结果集
resultset
rs
=
cmd.exec();
if
(rs.next())
//
rs存在记录,不要插入
else
//
rs不存在记录,即数据库中没有b=b1的项,可以插入。
不记得c#的类名了,以上代码希望能达意
如何删除sql中某个字段出现重复的数据,且只保留id最小的
如图所示表a的各种数据,字段tel重复的数据,然后只保留id最小的数据,出现表b的结果~我自己写的代码直接把所有重复不重复的数据都删除了只保留了id最小的数据,只剩下id为1的数据了,连id=8的数据都被删除了

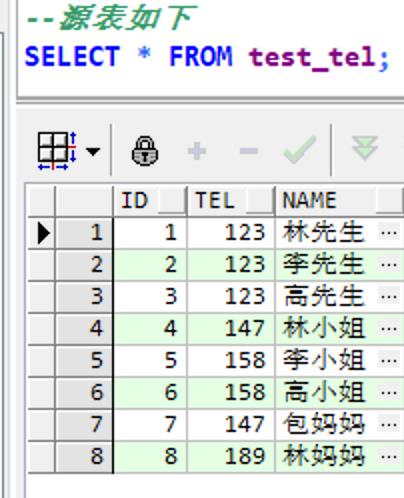
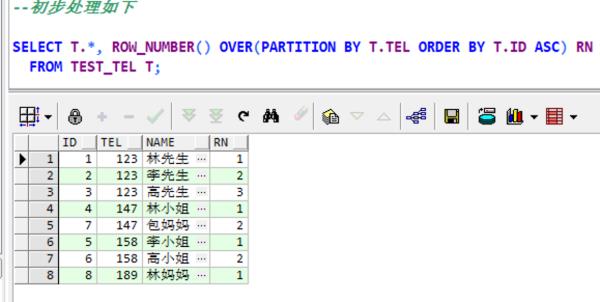
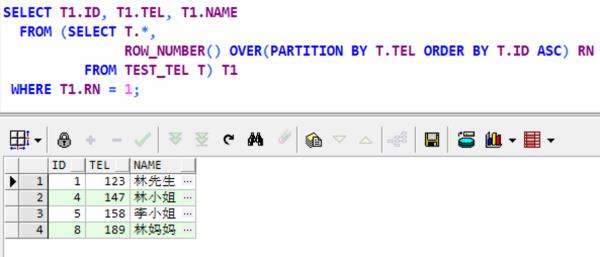
分解 显示 第1步:
你好如果考虑到需要name跟tel都相同的情况下,只保留id最小的呢?这个怎么实现呢?另外要排除name、tel是null的情况
参考技术A 建议做一个临时表,将id最小的保存下来了然后删除所有数据,在将最小的记录导回来。create tabke aa as (select id,tel,name,min(id) as minid from a group by id,tel,name,minid)
手头没有具体环境,记得这样写应该可以,思路就是将数据分组,只保留id最小的。记得做之前,先备份好原表,数据是最重要的。
以上是关于sql 怎么取不重复的数据的所有数据的主要内容,如果未能解决你的问题,请参考以下文章