基于深度学习的黑钨矿图像识别选矿方法
Posted 中国有色金属学报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度学习的黑钨矿图像识别选矿方法相关的知识,希望对你有一定的参考价值。
2020 “中、英文版高下载论文” 专题系列
作者
王李管,陈斯佳,贾明滔,涂思羽
(中南大学 资源与安全工程学院,长沙 410083)
摘要
黑钨矿图像识别是代替黑钨选矿手选抛废的一条高效途径,但存在无法识别黑钨矿石与围岩废石的问题。本文利用深度学习中卷积神经网络进行迁移学习来解决,该方法具有收敛快速、所需数据集小和分类准确的优点。首先,对黑钨原矿彩色图像采用旋转、平移等方法进行数据增广降低样本不平衡性。其次,基于 Keras 框架使用本文优化的神经网络进行全新训练。结果表明:黑钨矿石与围岩两类识别中 Wu-VGG19 迁移网络矿石识别率最高,为 97.51%。此外,本文加入石英脉石类别继续实验,得出修改的 Wu-v3 迁移网络矿石识别率最高,为 99.6%。
引言
黑钨矿选矿普遍采用重选为主的联合选矿工艺, 如图 1 所示。黑钨矿粗选方法日益完善,已由过去单一的手选方法变成了多方法联合的工艺,主要有光电、重介质选矿和动筛跳汰机等粗选方法。但由于其经济技术效果未强于手选,国内 60%以上钨矿仍采用手选丢废这一工艺。
图 1 黑钨矿选矿一般流程
Fig. 1 General flow of wolframite beneficiation
从 20 世纪 90 年代开始机器学习在矿业中开始应用。在选矿方面,PATEL 等使用基于机器视觉的支持向量机(SVM)算法对不同品位的铁矿石进行分类,分类错误率计算仅为 0.27%,但该模型的效果非常依赖于人工提供的特征,但需要人工设计特征提取策略,预处理过程工作量大;SINGH 等基于图像使用径向基神经网络对锰铁冶炼厂进料矿石分类,识别准确率不为88.71%;EBRAHIMI 等提出了一种基于层次分析法和特征映射的计算机视觉方法,识别 16 种常见矿石。魏立新等提出了一种基于深度学习方法的多层感知器轧制力预报模型,模型使网络预测与实测数据的相对误差降低到 3%以内,实现了轧制力的高精度预测。田庆华等利用人工神经网络模型对浸锑过程进行模拟,实验值与预测值的相关系数可达 99%。郑伟达等用对钙钛矿材料数据集中的密度、形成能、 带隙、晶体体积等 4 种性能参数分别用不同的机器学习算法进行预测。综上所述,传统钨矿石粗选工艺成本高,难以普及,而现有的基于图像自动识别技术预处理繁琐,识别准确率低,难以兼顾效率与成本。近年来深度学习在图像识别领域屡创佳绩,AlexNet、GoogleNet和 ResNet等深层卷积神经网络在 ImageNet 大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)中某些识别任务上准确率已超过人类。其核心是使用一种通用的学习过程从原始数据中学到特征用于后续分类,无需前期的特征工程,譬如通过人工提前设计好特征的内容或特征的数量。ImageNet 包含 2 万多个类别,挑战赛选取了 1000 个非重叠类作为识别任务。2012 年在解决 ImageNet 挑战方面取得了巨大的突破, 被广泛认为是 2010 年的深度学习革命的开始。卷积神经网络(Convolutional Neural Network, CNN)是深度学习中的重要算法之一,理论上网络层数越深越能够抓取图像中的抽象特征,学习能力越强。但针对小样本数据,CNN 易陷入过学习(过拟合),而迁移学习是解决这一问题的有效途径之一。
迁移学习(Transfer Learning)是将某个领域或任务上学习到的知识或模式应用到不同的但相关的领域或任务中。该方法试图实现人通过类比进行学习的能力,例如学习骑自行车的技能可以用来学习骑摩托车等。迁移学习应用广泛,如 WANG 等基于迁移学习使用 AlexNet 等网络识别 20 种车辆类型;DAI等通过文本格式数据来帮助图像进行分类,提出一种翻译迁移学习的方法。在工程应用上,由于每个应用领域收集充分的标注数据代价十分昂贵,甚至不可能,因此从相似领域或任务中迁移现有的知识从而完成或改进目标任务十分必要。故可认为迁移学习是在最小人工监督成本下进行机器学习的一种高效方法。在上述研究基础之上,针对黑钨矿图像识别方法无法有效识别黑钨矿石与围岩废石的问题,本文利用预训练后的 CNN 进行迁移学习完成识别任务。首先,为了降低样本的不平衡性,对黑钨原矿数据集 RGB图像采用旋转、平移、添加噪声等方法进行数据增广;其次,在 Keras 框架下,使用优化的 VGG19、Inception-V3、InceptionResnet-V2和InceptionResnet-50这四个 CNN 对数据集分别进行迁移学习实验;最后,为了进一步识别品位差异较大的两类矿石,本文在数据集中加入石英脉石类别继续实验;以期上述实验对改进黑钨矿选矿工艺具有重要实践意义。
实验数据
(一) 数据集收集
图片样本采集于国内三个钨矿,黑钨矿原矿石主要可分为围岩、钨矿石和石英三类。拍摄样本为选矿厂手选皮带运出的不同粒级原矿(经过水洗工序),将随机挑选出的原矿石置于皮带地面(室内光线充足),然后使用 1200 万像素的智能手机从不同方向拍摄原始样本,拍摄距离约 10cm。拍摄样本共计 2500 张左右,将其手动分为三类:黑色围岩 900 张,钨矿石 210 张,石英 1400 张。由于拍摄条件的限制,样本数据集过小具有不平衡性,大大影响了识别准确率。
(二) 图像数据增广
为降低样本的不平衡性和解决数据集过小容易造成模型的过拟合的问题,对训练样本进行数据增强(Data Augmentation)操作,以提高迁移网络分类准确率。数据增强常用方法有:图像亮度、饱和度、对比度调整,PCA 抖动,尺度变换,图像裁剪、缩放,水平/垂直翻转,平移/旋转/仿射变换,添加高斯噪声、模糊处理等,针对不同样本集可选择不同的增强方法。本文中样本经过裁剪预处理后,将样本旋转(45°、 135°)、平移,缩放(1.5 倍和 0.5 倍及 0.25 倍),水平/垂直翻转变换和随机添加噪声,通过这些数据增强方法使数据集每个类别达到 1500 张。考虑到实际识别时可提供稳定光源,故没采用图像亮度、饱和度、对比度调整等增强方法。
实验原理与方法
(一)实验原理
卷积神经网络长期以来是图像识别领域的核心算法之一,并在大量学习数据时有稳定的表现。它可在分类识别中用于提取图像的判别特征以供其他分类器进行学习,特征提取可以人为地将图像的不同部分分别输入网络,也可以由网络通过非监督学习自行提取。
卷积神经网络利用深层网络结构提取图像高维抽象特征,完成图像的识别和分类工作。其隐藏层的卷积核具有参数共享和层间连接的稀疏性,网络能以较小的计算量对格点(像素和音频)数据进行学习,效果稳定且不需额外特征工程。卷积神经网络结构一般由输入层、隐藏层(卷积层、池化层、全连接层)、输出层组成,结构如图 2 所示。
1) 输入层:由于 CNN 使用梯度下降法进行学习,需要对输入特征进行标准化处理。如输入像素数据,可将原始像素值[0,255]归一化至[0,1]区间。输入特征的标准化有利于提升算法的运行效率和学习表现。
2) 卷积层:卷积层具有对输入数据进行特征提取的功能。其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数(W)和一个偏差量(b)。层内每个神经元与前一层中邻近的多个神经元相连,连接数目取决于卷积核的大小,该区域被称为感受野,其概念类似于视觉皮层细胞的感受野。卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量。
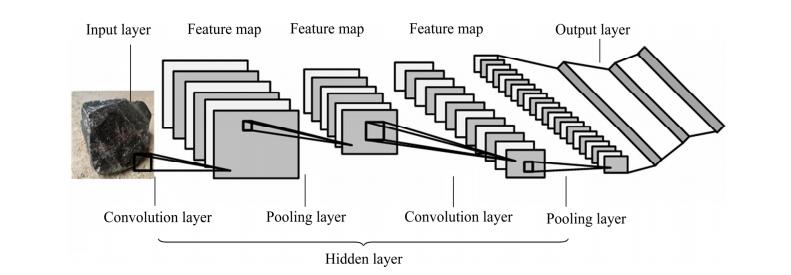
图 2 卷积神经网络一般结构
Fig. 2 General structure of convolutional neural networks
3) 激活层:其作用是将前一层的线性输出,通过非线性激活函数处理增强网络的表征能力。激励函数有 Sigmoid、Tanh、ReLU 等。
4) 池化层:卷积层提取出特征图后,特征图被传至池化层进行信息过滤和特征选择。池化层包中的池化函数计算特征图中单个点相邻区域的特征图统计量。池化层选取池化区域与卷积核扫描特征图步骤相同,由池化大小、步长和填充控制。根据局部相关性,“池化”在较少数据规模的同时保留了有用信息;池化还具备局部线性转换不变性,增强了卷积神经网络的泛化能力。
5) 全连接层:全连接层通常位于卷积神经网络隐藏层的最后,只向其他全连接层传递信号。三维特征图在全连接层中被展开为一维向量并通过激励函数传递至下一层。
6) 输出层:卷积神经网络中输出层的上游通常是全连接层,因此其结构和工作原理与传统前馈神经网络中的输出层相同。对于图像分类问题,输出层使用逻辑函数或归一化指数函数(Softmax function)输出分类标签。
(二)实验方法
本文采用一种基于迁移学习的图像识别方法来识别矿石,方法如图 3(a)所示,预训练网络神经元连接结构非常复杂,图 3(a)中为简化的预训练网络结构。图3(b)所示为本文设计的全连接层结构。第二层和第三层每个神经元的连接形式与每层第一个神经元相同,最后一层为神经元个数为 3,对应三类矿石标签,例如当输出结果为[0,1,0]时,则表示判别类别为钨矿石。首先加载权重文件到相应 CNN 初始化网络参数,然后冻结网络前面部分卷积层避免训练过程中前面网络层参数被修改,最后在网络后面添加全连接层与优化训练参数来重新训练整个网络,完成识别钨矿石的任务。具体训练步骤如下:
1) 将三个矿山的样本图片经过预处理的数据集按 6:2:2 分成训练、验证和测试集。训练集用于网络训练,验证集被用于交叉验证训练结果以避免过拟合,测试集未被标注标签,不参与网络训练相当于网络未学习的新数据,用于检验训练后网络的实际识别准确率。测试集中还包括了网络上爬取的钨矿石图片。网络输入图片大小为 299×299 pixel,训练样本图片如图 4 所示;
2) 下载权重文件并加载到相应的网络上,来初始化迁移网络参数,主要目的是节省训练时间,加快收敛速度;
3) 在网络后面添加三层全连接层结构,优化训练参数,然后重新训练整个网络,得到识别模型;
4) 训练过程中从训练集中随机不重复抽取小批次图片训练,抽完所有训练图片为一个训练周期,迭代到一定周期完成训练,得到识别模型;
5) 用测试集测试模型效果。将原矿石数据集划分为以下三类(见图 4):围岩(a)、钨矿石(b)、石英(c)。
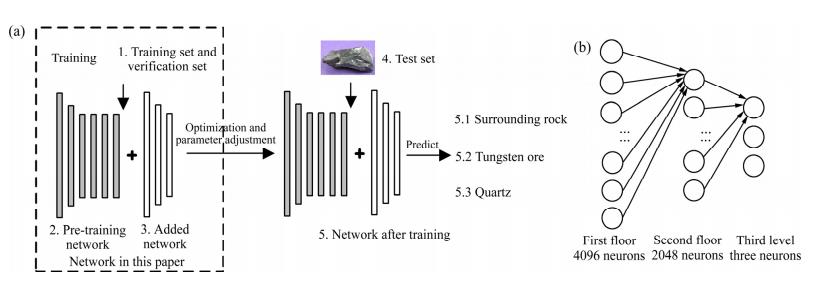
图 3 迁移学习方法流程
Fig. 3 Transfer learning method flow: (a) Training flow; (b) Full connect layer neurons number

图 4 矿石数据集类别
Fig. 4 Ore data set categories: (a) Surrounding rock; (b) Tungsten ore; (c) Quartz
(三) 迁移网络结构
本文使用改进的四个卷积神经网络进行迁移学习应用于钨矿石分类问题,将修改优化后的网络重命名为 Wu-VGG19、Wu-V3、Wu-ResnetV2 和 Wu-Resnet- 50。表 1 中列出了各个网络未修改之前具体信息。ImageNet 是一个人工标注类别标签的图片数据库(用于机器视觉研究),目前有 22000 个类别。自 2010年以来,基于该数据集每年举办一次 ILSVRC 软件比赛,软件程序竞相正确分类检测物体和场景。在图像分类领域,该比赛准确率已经作为计算机视觉分类算法的基准。自 2012 年以来,CNN 和深度学习在这一比赛的排行榜中遥遥领先,目前分类 Test Top-5 已降至 2.25%。
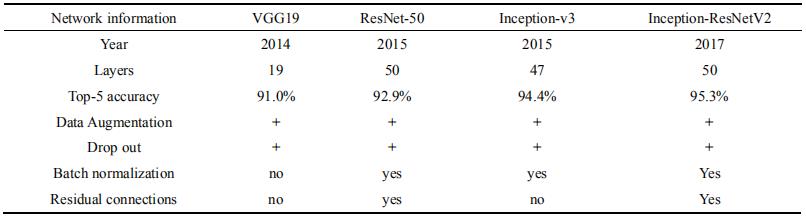
表 1 迁移网络结构信息
Table 1 Transfer network information
(四) 网络优化与环境配置
1) 网络优化
网络优化的实质是最小化损失函数。本文四个网络均采用 Mini-batch 梯度下降法加速模型,兼顾了训练速度与准确率。学习率更新策略采用指数衰减法,经过测试,Wu-ResNetV2 学习率 lr 设置为 0.001, Wu-VGG19、Wu-V3 和 Wu-Resnet-50 设置为 0.005 迁移网络收敛效果较好。添加的全连接层的权值参数(W) 与偏置参数(b)按一定方式随机初始化,其他各层的 W 与 b 则从权重文件中加载。训练周期 Epochs 设置为200,采用交叉熵计算损失,并使用正则化的损失函数减轻过拟合现象。
2) 环境配置
基于 Keras 框架进行迁移网络的训练与测试,该框架是一个高层神经网络 API,由纯 Python 编写而成。硬件环境:Intel(R)Core(TM)i7-7900XCPU@3.30GHz 处理器,64GB 内存,NVIDIA GeForce GTX 1080 Ti。GPU 软件环境:Ubuntu16.04 64bit 系统,CUDA5.0, CUDNN8.0,Tensorflow-gpu-1.03,Keras2.0,Pycharm 专业版。
结果分析
(一)模型训练与测试结果
本文训练主要分为两种:一种是识别钨矿石与围岩废石两类的训练,解决黑钨矿图像识别方法无法有效识别黑钨矿石与围岩废石的问题;另一种是识别钨矿石、黑色围岩和石英三类的训练,该实验是为了继续区分品位差异较大的两类矿石,满足实际需求。石英为脉石,一般含有较小钨矿石晶粒,区分不同品位的矿石对选矿工艺的改进具有实际意义。本文从训练精度(Train Accuracy),测试精度(Test Accuracy),训练损失(Loss)等指标评估一个网络的训练效果。训练精度指模型在训练集上输出正确结果的比率,计算公式如式(1)所示:
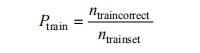
(1)
式中:ntraincorrect 表示训练集中网络识别正确的个数;ntrainset 表示训练集样本个数。训练数据集相对过大,每轮训练计算整体识别精度的话会大大延长训练,故只计算每轮训练批次的训练精度,在训练集中随机抽取每个批次,假设每个批次样本满足与测试集的相同分布。
测试精度指模型在测试集上输出正确结果的比率,测试精度定义如公式(2)所示:
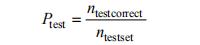
(2)
它反映了网络使用效果,是一个很重要的指标,同时训练精度与测试精度相差太大则表示网络训练过拟合,过学习导致网络泛化性能差,不具有实用性。故一个好的网络既要尽量提升测试精度,也要尽量缩小训练精度与测试精度的差距。迁移网络训练过程就是最小化损失函数的过程, Loss 就是损失函数的值。损失函数实际上计算的是模型在测试集上的均方误差(MSE,Etrain),如式(3)所示:
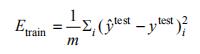
(3)
1) 训练精度对比分析
迁移网络各组试验的训练结果如图 5 和 6 所示,其中四个迁移网络训练精度曲线图,黑色表示训练精度曲线,灰色表示验证精度曲线;图 7 所示分别为四个迁移网络训练精度(TrainAcc)曲线和损失(Loss)曲线对比图。
图 5 迁移网络两分类 TrainAcc 图
Fig. 5 TrainAcc diagram of two classification transfer networks: (a) 2-Wu-VGG19-TrainAcc; (b) 2-Wu-ResNet50-TrainAcc; (c) 2-Wu-V3-TrainAcc; (d) 2-Wu-ResNetV2-TrainAcc
图 6 迁移网络三分类 TrainAcc 图
Fig. 6 TrainAcc diagram of three classification transfer networks: (a) 3-Wu-VGG19-TrainAcc; (b) 3-Wu-ResNet50-TrainAcc; (c) 3-Wu-V3-TrainAcc; (d) 3-Wu-ResNetV2-TrainAcc
由图 5 可知,经过 200 个周期的训练,二分类情况下四个网络最后训练准确率分别为均超过 99%,损失均低于 0.01,Wu-ResnetV2 训练数据为最优,训练精度达到 99.89%,但测试精度 Wu-VGG19 最高。由图 6 可知,三分类同样经过 200 个周期的训练,四个网络最后训练准确率分别为均超过 98%,损失均低于 0.07;Wu-V3 训练数据达到 99.20%为最优,但Wu-Resnet50 测试精度最高。从以上结论可知,本文中选取的四个迁移网络测试效果最好的网络并不是训练结果最好的,测试结果更具有实际意义。
由图 7 可知,二分类与三分类四个迁移网络训练均在 10 个周期内快速收敛。本文对比了训练 50、100 和 200 个周期的三分类 Wu-Resnet50 网络测试精度,发现随着训练周期的增加迁移网络测试精度逐步提升,考虑到时间成本与实际效果故本文将周期设定为200。
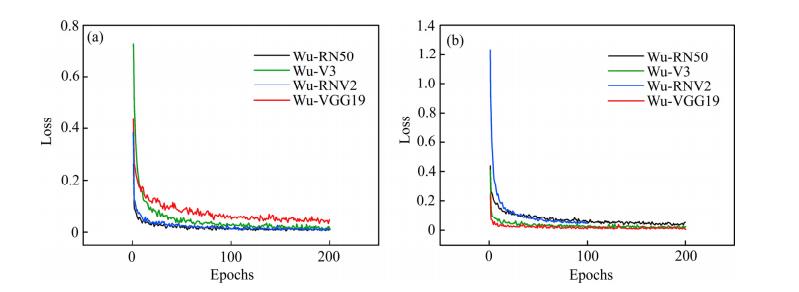
图 7 迁移网络训练损失对比图
Fig. 7 Transfer networks training loss comparison diagram: (a) Two-classification loss curve comparison; (b) Three-classification loss curve comparison
由图 8 可知,二分类的四个迁移网络训练精度与测试精度之间差异明显小于三分类的迁移网络,且训练精度整体更高,而对比同一迁移网络的二分类与三分类测试精度全都有所降低。可知加入新的识别类别影响了迁移网络的性能,原因是加入的新类别与原始类别存在较多相似特征降低了网络识别准确率。
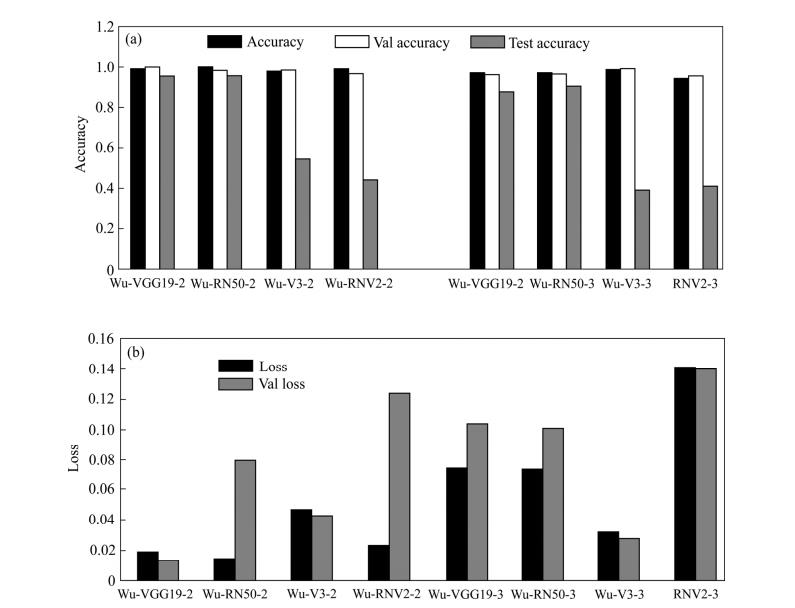
图 8 迁移网络准确率与训练损失对比图
Fig. 8 Transfer networks accuracy and loss comparison diagrams: (a) Accuracy comparison; (b) Loss contrast
2) 测试精度
测试图片由网络上爬取图片及其他钨矿山样本图片组成。测试集包括三类图片:围岩、钨矿石和石英,相当于未知样本。由表 2 可知,二分类中 Wu-VGG19测试平均精度最高为 95.85%,三分类 Wu-Resnet50 测试平均精度最高为 90.50%,加入非矿石新类别降低了钨矿石识别准确率。在二类识别与三类识别测试中Wu-VGG19 与 Wu-Resnet50 明显优于其他网络,可见不同网络对不同识别任务的性能差异较大,要合理的选择识别网络。另外,矿石二分类中识别效果最好的Wu-VGG19 网络是层数最少的,说明单纯加深识别网络深度不一定能提升识别率,还可能导致过拟合。
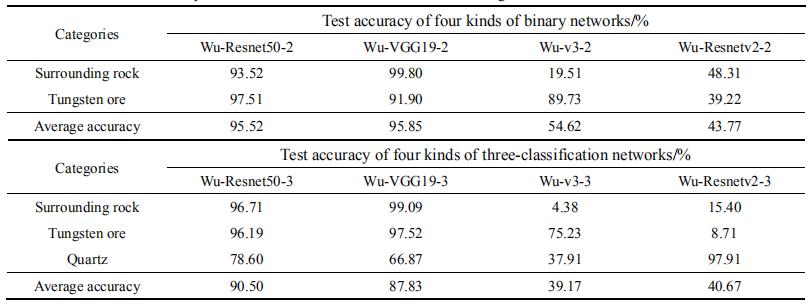
表 2 二分类与三分类识别网络测试准确率
Table 2 Network test accuracy of two-classification and three-classification recognitions
(二)三分类优化
上述分析结果可知Wu-v3和Wu-ResNetv2测试集分类精度远低于前两个网络,而且存在某一类分类精度高,其他类分类精度低等情况。可能存在过拟合或者训练不充分的情况,全连接层参数和数据集不足是以上问题的重要原因。本文研究只有 2、3 类,可能并不需要这么复杂的全连接层,因为这样增加了训练难度,故调整Wu-v3和Wu-ResNetv2训练策略继续优化。
策略一:减少网络 Wu-v3 和 Wu-ResNetv2 的连接层层数(直接连接到最后一层)重新训练三分类。策略二:再增广数据集至每类 2500 张重新训练 Wu-v3 和Wu-ResNetv2 网络三分类,测试精度如表 3 所示。
对比策略一、二及原始训练结果,Wu-ResNetv2网络采取策略一,平均精度有所上升,但仍然存在某一类分类精度过高或过低的情况;采取策略二,平均测试精度提升了 55.5%,且每类测试精度较为均衡。Wu-v3 网络采取策略一,平均测试精度提升了57.77%,采取策略二平均测试精度提升了 55.63%,且每类测试精度均衡。综上可知,Wu-ResNetv2 网络可通过增广数据集提升网络识别性能,平均精度达96.17%,Wu-v3 网络可通过减少全连接层或者增广数据集方式提升识别准确率,平均精度可达 96.94%
表 3 三分类新策略优化后测试准确率
Table 3 Test accuracy of optimized three-classification network
讨论
本文认为未来可对以下两个方面继续进行研究:
1) 实际中钨矿石选矿中还存在其他类别的废石,加入新类别会大大提升识别难度,故可进一步探索加入更多类别的钨矿石识别;
2) 由于手选皮带上拍到的钨矿石图片都是多个矿石块,要实现基于 RGB 图像手选钨矿的自动化识别除硬件外,还可进一步研究识别钨矿石的目标检测网络来对多目标进行识别。
结论
1) 黑钨矿石与围岩两类识别中 Wu-VGG19 迁移网络矿石识别率最高,为 97.51%。此外,本文加入石英脉石类别继续实验,得出优化后的 Wu-v3 迁移网络矿石识别率最高,为 99.6%,加入新类别未提升钨矿石识别率,相比原始识别网络对钨矿石的识别有非常大的提升。
2) 本文改进的两个迁移网络具有较高的识别率,泛化性能好,对改进黑钨矿选矿工艺具有重要实践意义。实验过程中发现本文中选取的四个迁移网络测试效果最好的网络并不是训练结果最好的网络。
3) 二分类性能最优的 Wu-VGG19 具有最少的网络层数,故单纯的加深网络深度并不一定能提升钨矿1200 石的识别效果。三分类中过拟合或者训练不充分的问题可通过减少网络全连接层或再增广数据集的方式解决。
END
了解更多精彩内容
中国有色金属学报
-版权信息-
编辑:陈轶群
责编:王超、袁赛前、龙怀中
审核:彭超群
转载及合作事宜请联系邮箱:
wangchao0202@163.com
以上是关于基于深度学习的黑钨矿图像识别选矿方法的主要内容,如果未能解决你的问题,请参考以下文章