AlphaGo Zero 没有告诉你的秘密
Posted 待字闺中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlphaGo Zero 没有告诉你的秘密相关的知识,希望对你有一定的参考价值。
AlphaGo 确实很厉害,尤其是最新发表的 AlphaGo Zero(点击阅读原文),完全不用人类棋手的棋谱,从零开始学起,大概学习21天就能完胜柯洁,学习40天就能完胜之前的任何AlphaGo版本。
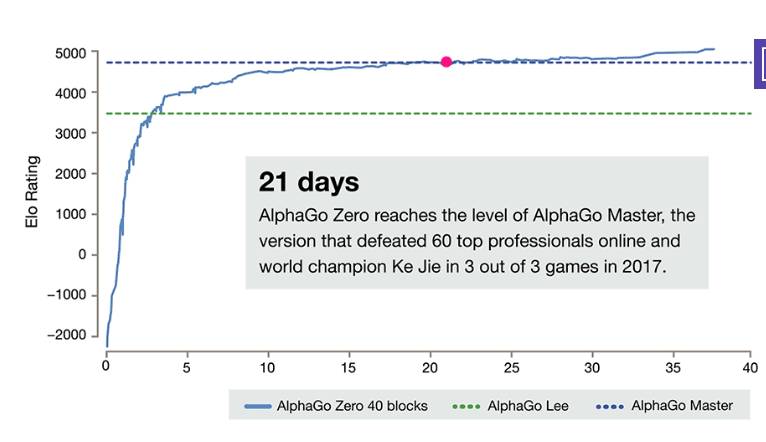
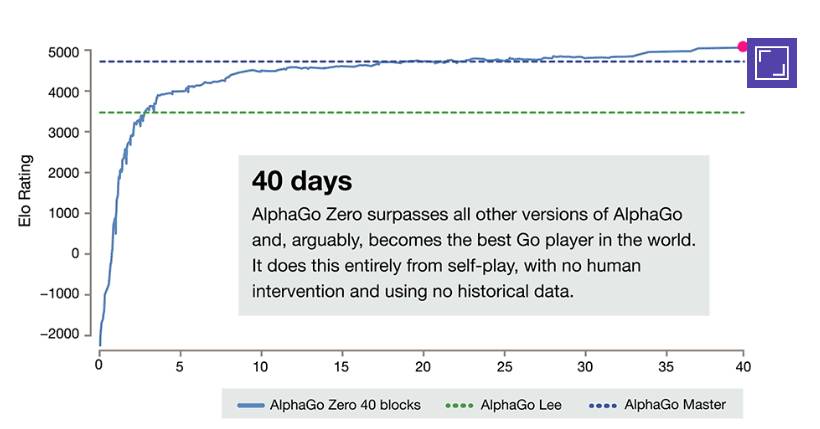
AlphaGo Zero除了使用围棋规则,完全摈弃了人类棋手的知识和棋谱,利用强化学习和深度学习模型,左右手互搏的自学习,获得功力。它高强度的使用了搜索(模拟),蒙特卡罗树搜索(MCTS),但它没有告诉你,这个树搜索实际上是在产生标注数据。
为什么?
因为围棋下到一定程度,最极端的情况是,大家都无子可下的时候,是能通过规则计算胜负的,也就是说,模拟(搜索)到一定程度,就能产生一个输或赢的棋局数据。正是由于这一点,围棋是能够在没有人类棋手的知识(用来减少搜索空间和加速搜索进程)的情况下,使用非监督学习来学习的。机器的计算速度很快,能够在极短的时间内模拟大量的有胜负的棋局,并且从中学习。
很多的游戏也具有类似的能够模拟(搜索)产生最后能用规则判别胜负的样本,所以它们无需人类的知识,确实能从零学习。
但是,像语音识别,图像识别,自然语音理解,等等,领域,就缺乏用简单规则就能判别的样本,它们需要大量的人工标注,然后才能监督或是半监督学习。
就像给你一段不知地球上哪个角落的一句方言说的语音,鬼知道讲的是什么,除了有很多之前专家标注的样本。或是给你一块甲骨文,你能知道写的是什么吗,如果没有很多专家考证研究了多年的结果。
有人可能会质疑,机器翻译,自动问答,不是可以吗?别忘了,这些系统是充分利用了人类有史以来积累的大量的人类翻译的双语语料,或是人类的问答句对。没有它们,这是不可能的任务。
明白了这个可用简单规则判别结果的先决条件,知道AlphaGo Zero 确实算法和工程很牛逼,但是不要被误导了,任何东西(人工智能)都可以无需人类知识或是领域数据就可以从零学习的。然后就觉得人工智能是万能的。
从AlphaGo Zero的论文中,描述的Self-Play和Neural Network Training,我们看到最终状态St是需要根据围棋规则来计算胜者z的,实际上,用模拟(搜索)产生了一个(或是几个)训练样本(棋局)。
AlphaGo Zero中的模特卡罗树搜索(MTCS)。
具体的算法和技术细节,请点击阅读原文。
以上是关于AlphaGo Zero 没有告诉你的秘密的主要内容,如果未能解决你的问题,请参考以下文章