Hack Day全文检索引擎Lucene原理
Posted 一起哔哔哔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hack Day全文检索引擎Lucene原理相关的知识,希望对你有一定的参考价值。
全文检索引擎Lucene原理
前 言
preface
结构化数据:具有固定格式,有限长度,查询速度快
非结构化数据:无固定格式,不定长,扫描慢,又名全文数据
全文检索:提取出非结构化数据信息,重新整理成结构化数据,以达到快速检索的目的 , 这里整理出来的数据就是索引。
Lucene是一个开放源代码的全文检索引擎工具包
提供了完整的创建和查询索引功能
下面顺着几个模块依次看它是如何实现这些功能的

正向索引:索引(Index)–>段(segment)–>文档(Document)–>域(Field)–>词(Term)
倒排索引:词(Term)–>文档(Document)
1:准备需要索引的文档(Document)
2:把文档传给分词组件(Tokenizer),分词、去除标点和停用词
3:将得到的词元(Token)传给语言处理组件,对于英语需要转换为小写、转换为词根
4:将得到的词(Term)传给索引组件(Indexer),用得到词生成字典,并合并相同的词生成文档倒排链表
1. 输入查询语句
2. 词法分析检查语句、语法分析生成语法树
3. 根据语法结果检索出文档,合并
检索出来的结果谁排第一?
引入概念:相关性排序,越“像”的文档排的越靠前,
反映到程序里面就是个打分的过程,文本相关性越大的分数越高
打分算法
判断权重的因子是什么?
tf :词在某个文档中出现的次数越多,该文档分数越高
tf=sqrt(freq)
idf:词在所有文档中出现的次数越多,该词分数越低
idf=log(numDocs/(docFreq+1)) + 1.0
词的权重=tf*idf
如何根据词的权重判断一个文档的权重?
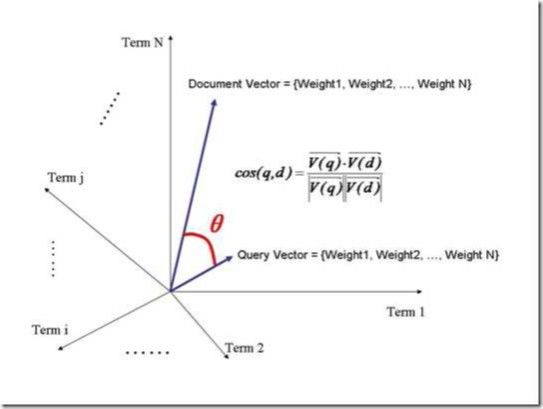
把这个文档放到N维空间中:
夹角越小,余弦越大,相关性越大,打分也越高
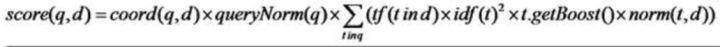
t: Term 、词
coord(q,d):一次搜索可能包含多个搜索词,文档命中的词越多打分越高
queryNorm(q):查询归一化,使得不同的query之间的分数可以比较
tf(t in d): t 在文档d中出现的词频
idf(t): 逆文档频率, 即t在几篇文档中出现过
norm(t, d):标准化因子,它包括三个参数:
Document boost:此值越大,说明此文档越重要
Field boost:此域越大,说明此域越重要
lengthNorm(field):一个域中包Term 总数越多,也即文档越长,此值越小,反之则反
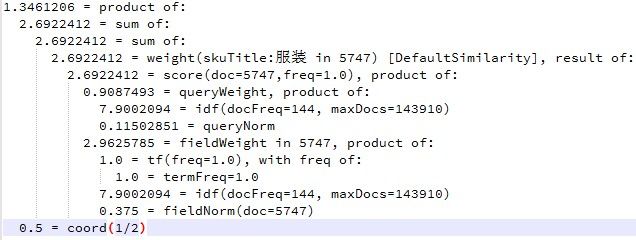
默认Document boost和Field boost是1,fieldNorm(lengthNorm)=1.0/sqrt(numTerms)
索引阶段就确定了,是从索引文件里读出来的,就是该字段分词后的词越少那就评分越高
所以这种情况下norm=fieldNorm
queryWeight * fieldWeight = queryNorm*idf*tf*idf*fieldNorm
这里只命中一个搜索词:
score = queryNorm*tf*idf^2*fieldNorm*coord

扫描二维码
关注更多精彩
以上是关于Hack Day全文检索引擎Lucene原理的主要内容,如果未能解决你的问题,请参考以下文章