全文检索之Lucene框架
Posted 因博而起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全文检索之Lucene框架相关的知识,希望对你有一定的参考价值。
呆嘎吼,又到每天该晨博的时间了!
“
今日小姐姐...
阅读博客是一件痛苦却需要坚持的事情,能够让自己不断前进不掉队。而写博客则是将看过的知识点消化复现的过程,同样需要坚持。
I. 引言
全文检索
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档。先创建索引,然后根据索引来进行搜索。比如查字典,字典的偏旁部首就类似于索引,字典的具体内容则类似于文档内容。
应用场景:
搜索引擎
站内搜索
文件系统的搜索
Lucence
Lucene是Apache的一个全文检索引擎工具包,通过Lucene可以让程序员快速开发一个全文检索功能。Lucene不是搜索引擎,仅仅是一个工具包。它不能独立运行,不能单独对外提供服务(Solr、ElasticSearch)。
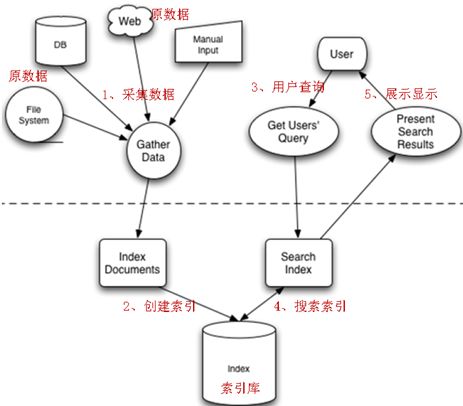
II. Lucence实现全文检索流程
全文检索流程
索引流程:采集数据——文档处理——存储到索引库中
搜索流程:输入查询条件——通过Lucene查询器查询索引——从索引库中取出结果——视图渲染
注:Lucene本身不能进行视图渲染。
Lucene的索引与搜索
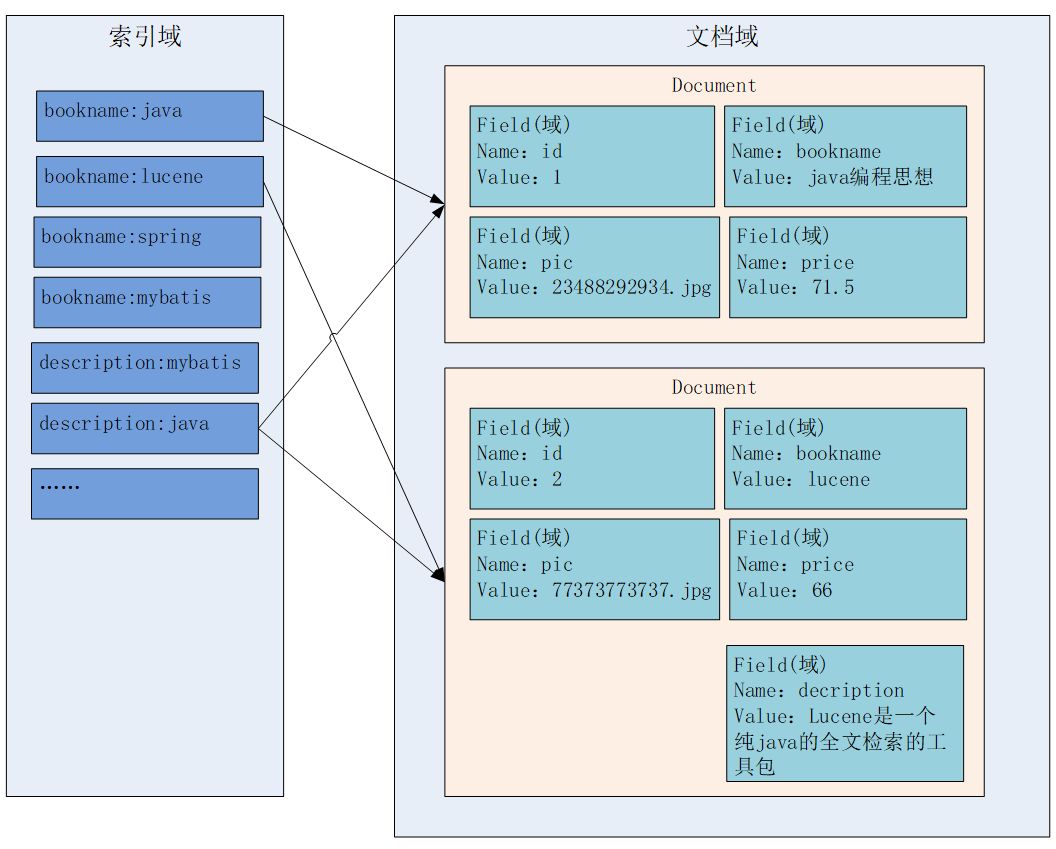
文档域:文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中Field域来存储数据。比如:数据库中一条记录会存储一个一个Document对象,数据库中一列会存储成Document中一个Field域。Field域的name为字段名,value则为具体值。文档域中,Document对象之间是没有关系的,而且每个Document中的Field域也不一定一样。
索引域:主要是为了搜索使用的,索引域的内容是经过Lucene分词之后存储的。
倒排索引表:传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。 倒排索引结构是根据内容(词语)找文档,包括索引和文档两部分。索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,先找到索引中的词汇,词汇又与文档关联,从而最终找到了文档。
III. 入门案例
环境准备
Jdk1.8(Lucene4.8版本以后,必须使用jdk1.7及以上)
Lucence7.4.0:http://archive.apache.org/dist/lucene/java/
案例需求
使用Lucene完成对数据库中商品信息的索引和搜索功能。
工程搭建
需要导入如下依赖jar包:
MySQL驱动包
Analysis包
Core包
QueryParse包
其中,Analysis包、Core包和QueryParse包分别在lucene-7.4.0\analysis\common、lucene-7.4.0\core和lucene-7.4.0\queryparser文件夹下,最终工程结构如下:
准备数据
这里的数据主要来源于数据库商品表,需要通过Jdbc查询数据库准备数据。
Product实体类:
public class Product {
private Long id;
private String title;
private String sellPoint;
private Long price;
private int num;
private String barcode;
private String image;
private Long cid;
private int status;
private Date created;
private Date updated;
/** getter and setter **/
}
ProductDao数据库查询:
public class ProductDao {
public List<Product> queryProducts() {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
List<Product> products = new ArrayList<>();
try {
Class.forName("com.mysql.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/taotao", "root", "1234");
String sql = "SELECT * FROM tb_item";
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
// 结果集解析
while (resultSet.next()) {
Product product = new Product();
product.setId(resultSet.getLong("id"));
product.setTitle(resultSet.getString("title"));
product.setSellPoint(resultSet.getString("sell_point"));
product.setBarcode(resultSet.getString("barcode"));
product.setImage(resultSet.getString("image"));
product.setPrice(resultSet.getLong("price"));
product.setCid(resultSet.getLong("cid"));
product.setNum(resultSet.getInt("num"));
product.setStatus(resultSet.getInt("status"));
product.setCreated(resultSet.getDate("created"));
product.setUpdated(resultSet.getDate("updated"));
products.add(product);
}
} catch (Exception e) {
e.printStackTrace();
}
return products;
}
}
创建索引
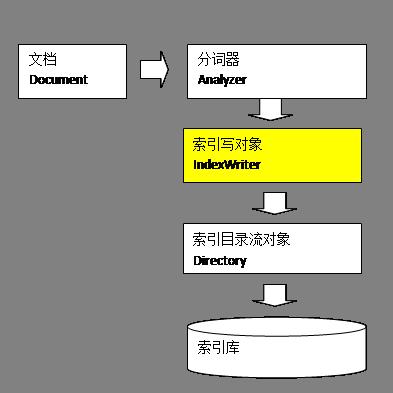
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
@Test
public void createIndex() throws IOException {
// 采集数据
ProductDao productDao = new ProductDao();
List<Product> products = productDao.queryProducts();
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
for (Product product : products) {
Document document = new Document();
// store:如果是yes,则说明存储到文档域中
Field id = new TextField("id", product.getId().toString(), Field.Store.YES);
Field title = new TextField("title", product.getTitle(), Field.Store.YES);
Field sellPoint = new TextField("sellPoint", product.getSellPoint(), Field.Store.YES);
Field barcode = new TextField("barcode", product.getBarcode(), Field.Store.YES);
Field image = new TextField("image", product.getImage(), Field.Store.YES);
Field price = new TextField("price", product.getPrice().toString(), Field.Store.YES);
Field cid = new TextField("cid", product.getCid().toString(), Field.Store.YES);
Field num = new TextField("num", product.getNum()+"", Field.Store.YES);
Field status = new TextField("status", product.getStatus()+"", Field.Store.YES);
Field created = new TextField("created", product.getCreated().toString(), Field.Store.YES);
Field updated = new TextField("updated", product.getUpdated().toString(), Field.Store.YES);
// 将field域设置到Document对象中
document.add(id);
document.add(title);
document.add(sellPoint);
document.add(barcode);
document.add(image);
document.add(price);
document.add(cid);
document.add(num);
document.add(status);
document.add(created);
document.add(updated);
docList.add(document);
}
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建IndexWriter
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 指定索引库的地址
Path indexFile = Paths.get("E:\\search-learn\\data");
Directory directory = FSDirectory.open(indexFile);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 通过IndexWriter对象将Document写入到索引库中
for (Document document : docList) {
indexWriter.addDocument(document);
}
// 关闭indexWriter
indexWriter.close();
}
内容分词
上面的代码,使用了标准分词器:StandardAnalyzer。主要有分词和过滤两个步骤。
分词:将field域中的内容一个个的分词。
过滤:将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原(复数转单数、过去式转成现在式)、停用词过滤。
使用Luck工具
下载:luke-javafx-7.4.0-luke-release.zip
Luke搜索
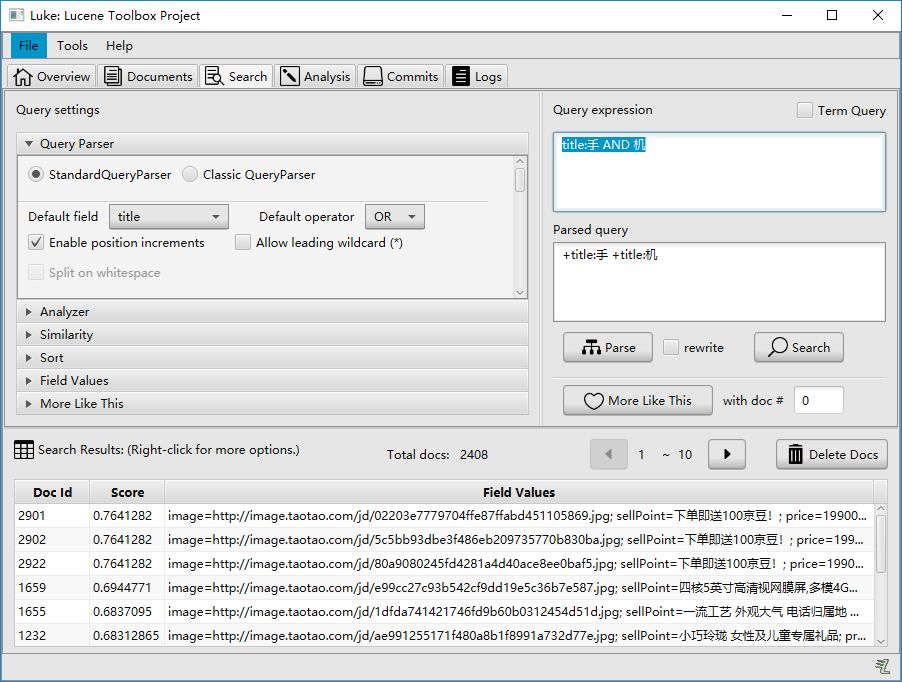
同数据库的sql一样,Lucene全文检索也有固定的语法。最基本的有比如:AND, OR, NOT 等。
举个例子,用户想找一个title中包括手和机(手机)关键字的文档。查询语句为:
title:手 AND 机
Luke中的查询结果为:
API搜索
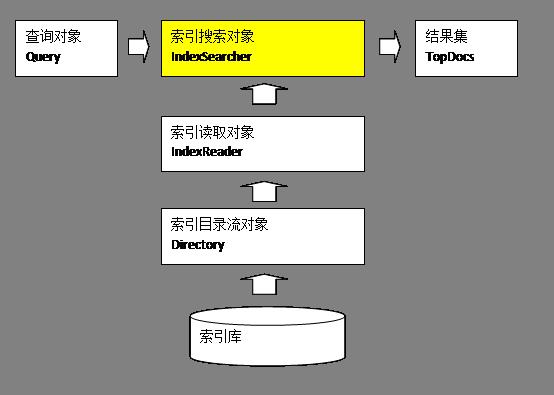
通过创建索引搜索对象,执行封装了查询语句的查询对象Query,得到结果集TopDocs。创建索引搜索对象IndexSearch时,需要索引读取对象IndexReader和索引目录流对象Directory。
@Test
public void searchIndex() throws Exception {
// 创建query对象
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("title", new StandardAnalyzer());
// 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("手 AND 机");
// 创建IndexSearcher
// 指定索引库的地址
Path indexFile = Paths.get("E:\\search-learn\\data");
Directory directory = FSDirectory.open(indexFile);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = indexSearcher.search(query, 2);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc;
// 通过ID获取文档
Document doc = indexSearcher.doc(docId);
System.out.println(doc.get("id"));
System.out.println(doc.get("title"));
System.out.println(doc.get("sellPoint"));
System.out.println(doc.get("barcode"));
System.out.println(doc.get("image"));
System.out.println(doc.get("price"));
System.out.println(doc.get("cid"));
System.out.println(doc.get("num"));
System.out.println(doc.get("status"));
System.out.println(doc.get("created"));
System.out.println(doc.get("updated"));
System.out.println("=================");
}
// 关闭资源
reader.close();
}
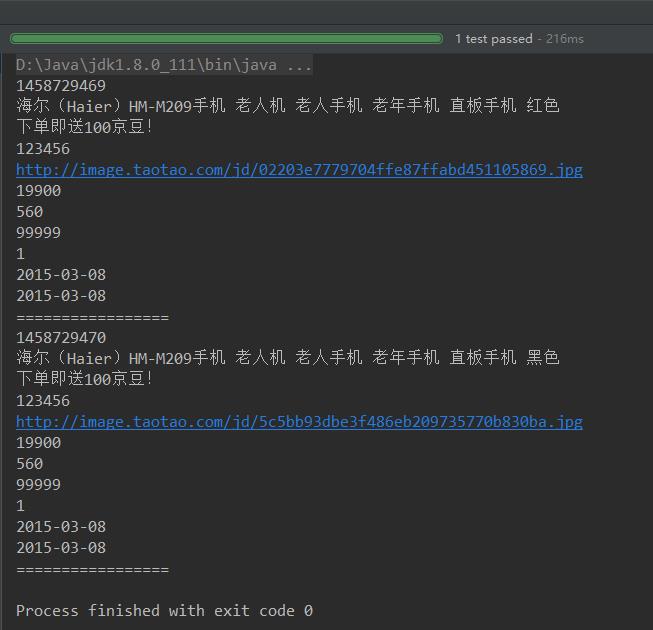
查询结果:
IV. Field域
Field属性
点击TextField类,我们可以看到如下三行源码:
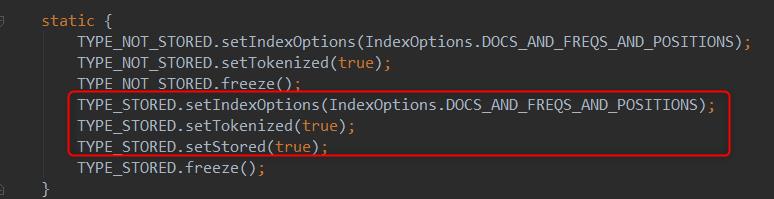
分别对应下面三个属性:
是否分词(Tokenized)
决定是否对该field存储的内容进行分词,分词的目的,就是为了索引。如果不分词,不代表不索引,而是将整个内容进行索引。比如商品id可以选择不分词整个索引。
是否索引 (Indexed)
将分好的词进行索引,索引的目的,就是为了搜索。 如果设置不索引,也就是不对该field域进行搜索。比如商品图片,不需要进行索引。甚至也不需要分词。
是否存储 (Stored)
将Field域中的内容存储到文档域中。存储的目的,就是为了搜索页面显示取值用的。设置否则不将内容存储到文档域中,搜索页面中没法获取该Field域的值。比如商品详情,商品详情往往需要分词检索,但是不需要取值供页面显示。一般通过商品id,点击进入商品详情展示页。
Field常用类型
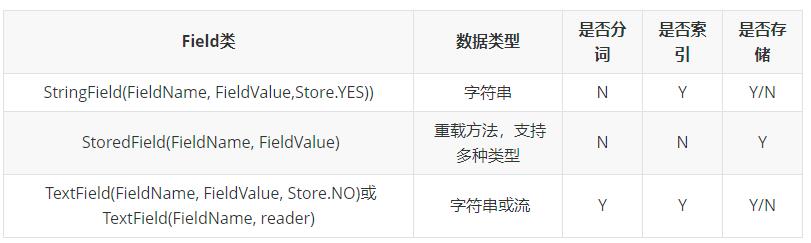
重构入门代码StringField:用来构建一个字符串Field,但是不会进行分词,会将整个串存储在索引中。比如:订单号,身份证号等。是否存储在文档中用Store.YES或Store.NO决定。
StoredField:用来构建不同类型Field,不分析,不索引,但要Field存储在文档中。
TextField:如果是一个Reader,Lucene猜测内容比较多,会采用Unstored的策略。
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
for (Product product : products) {
Document document = new Document();
// store:如果是yes,则说明存储到文档域中
// 商品id 不分词直接索引存储
Field id = new StringField("id", product.getId().toString(), Field.Store.YES);
// 商品名称 分词索引存储
Field title = new TextField("title", product.getTitle(), Field.Store.YES);
// 商品卖点 分词索引存储
Field sellPoint = new TextField("sellPoint", product.getSellPoint(), Field.Store.YES);
// 商品条形码 不分词直接索引存储
Field barcode = new StringField("barcode", product.getBarcode(), Field.Store.YES);
// 商品图片地址 不分词不索引存储
Field image = new StoredField("image", product.getImage());
// 商品价格 不分词不索引存储
Field price = new StoredField("price", product.getPrice());
// 商品类别id 不分词不索引存储
Field cid = new StoredField("cid", product.getCid());
// 商品数量 不分词不索引存储
Field num = new StoredField("num", product.getNum());
// 商品状态 不分词不索引存储
Field status = new StoredField("status", product.getStatus());
// 商品创建日期 不分词不索引存储
Field created = new StoredField("created", product.getCreated().toString());
// 商品更新日期 不分词不索引存储
Field updated = new StoredField("updated", product.getUpdated().toString());
// 将field域设置到Document对象中
document.add(id);
document.add(title);
document.add(sellPoint);
document.add(barcode);
document.add(image);
document.add(price);
document.add(cid);
document.add(num);
document.add(status);
document.add(created);
document.add(updated);
docList.add(document);
}
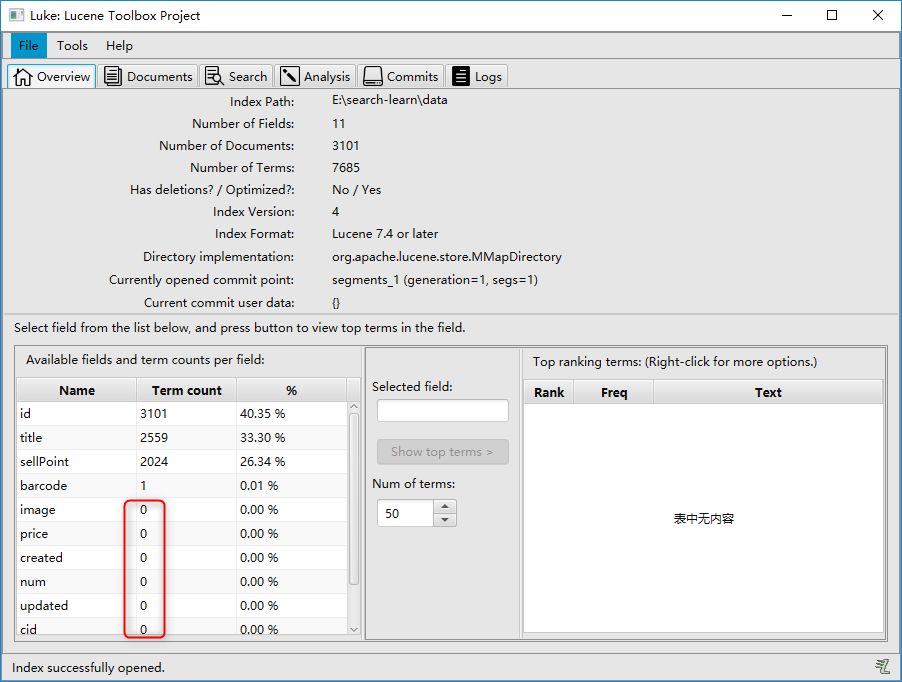
Luke查看分词结果:
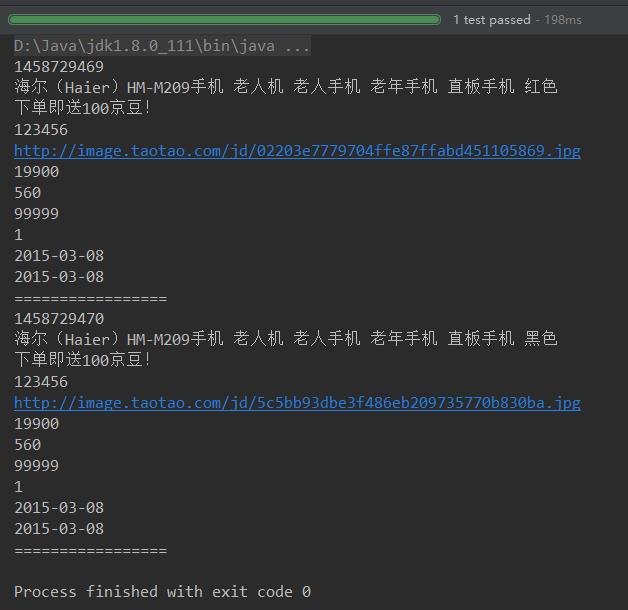
从存储中取出结果:
V. 索引维护
一旦商品信息发生变化,对应索引库相对应也需要进行改变。
添加索引
IndexWriter.addDocument(Document document);
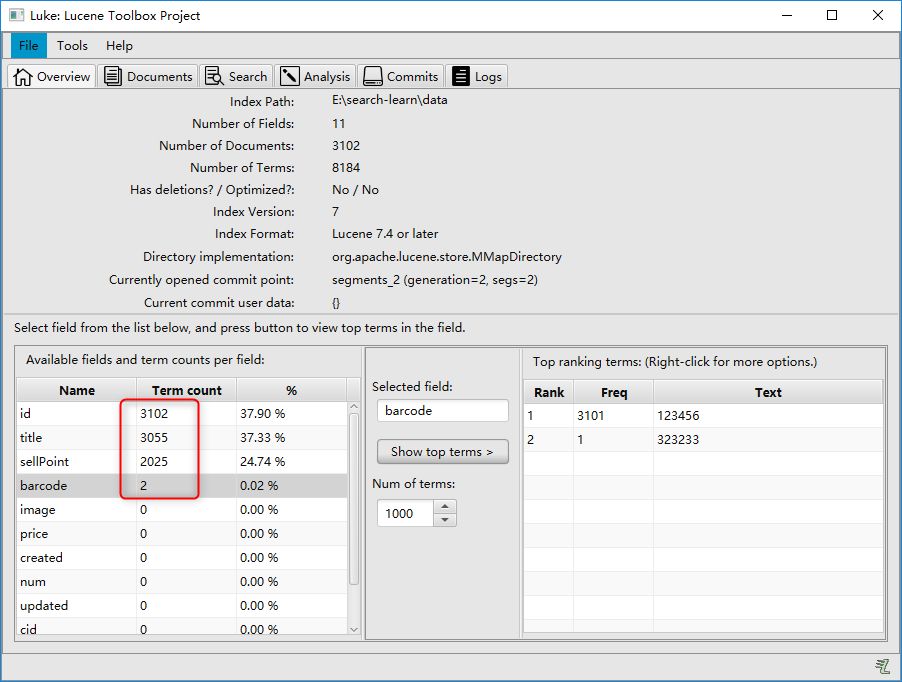
新增数据库一条商品记录:

继续利用入门案列创建索引即可,Luke查看结果可以看出新增索引成功:
修改索引
IndexWriter.updateDocument(Term term,Document document);
@Test
public void updateIndex() throws Exception {
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建IndexWriter
IndexWriterConfig config = new IndexWriterConfig(analyzer);
Path indexFile = Paths.get("E:\\search-learn\\data");
Directory directory = FSDirectory.open(indexFile);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 第一个参数:指定查询条件
// 第二个参数:修改之后的对象
// 修改时如果根据查询条件可以查出结果,则将其删掉,并进行覆盖新的doc;否则直接新增一个doc
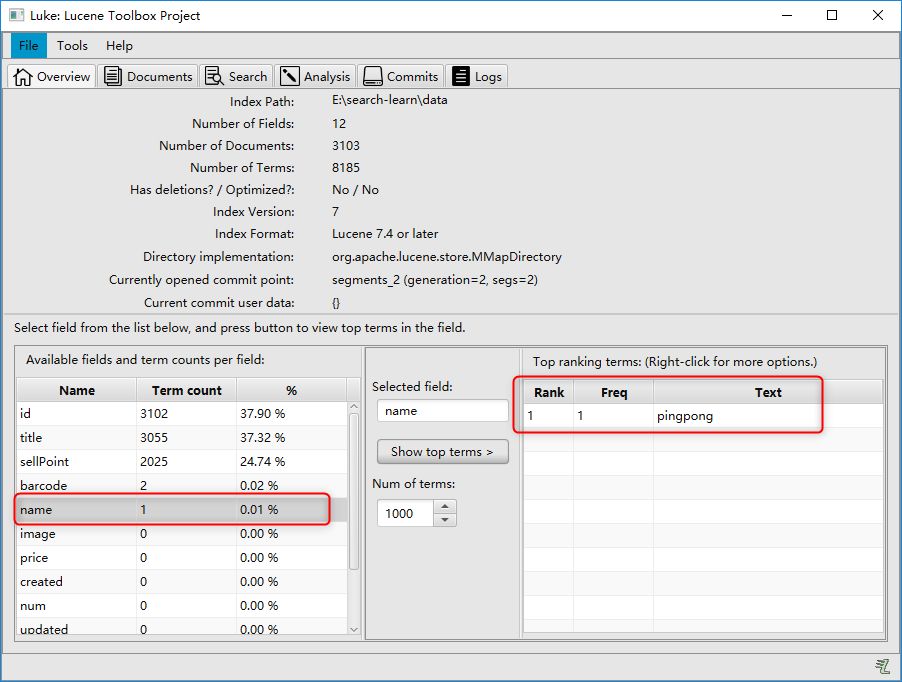
Document doc = new Document();
doc.add(new TextField("name","pingpong", Field.Store.YES));
indexWriter.updateDocument(new Term("name", "xiaoming"), doc);
indexWriter.close();
}
原本没有name的Field,所以会直接新增“pingpong”:
将代码的pingpong和xiaoming互换,再次更新,此时即会更新name的域索引:
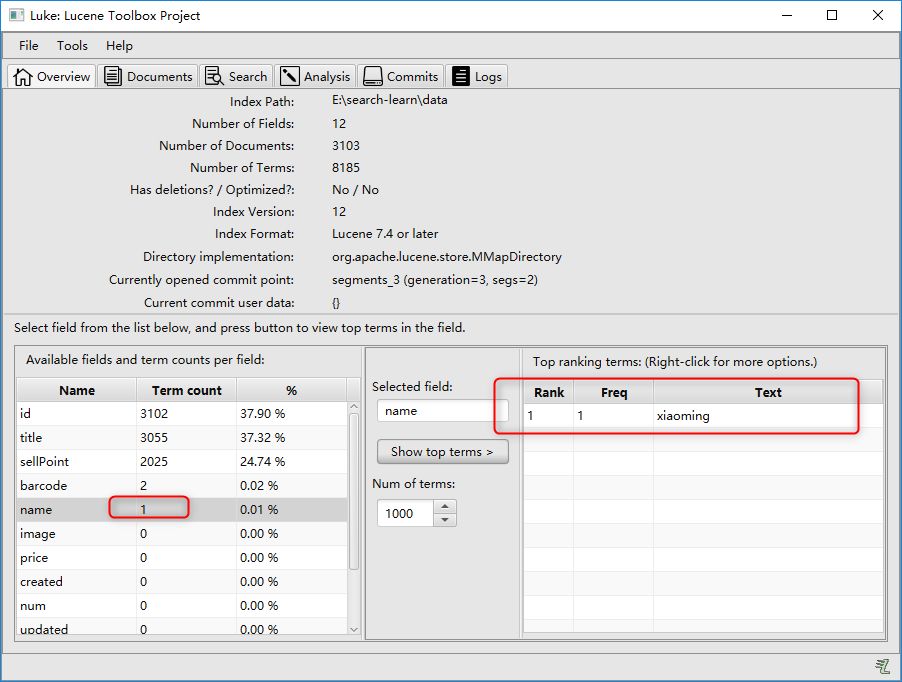
删除索引
删除全部:IndexWriter.deleteAll();
条件删除:
Term是索引域中最小的单位。根据条件删除时,建议根据唯一键来进行删除。在solr中就是根据ID来进行删除和修改操作的。
@Test
public void deleteByCondition() throws Exception {
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建IndexWriter
IndexWriterConfig config = new IndexWriterConfig(analyzer);
Path indexFile = Paths.get("E:\\search-learn\\data");
Directory directory = FSDirectory.open(indexFile);
IndexWriter indexWriter = new IndexWriter(directory, config);
// Terms
indexWriter.deleteDocuments(new Term("barcode", "323233"));
indexWriter.close();
}
VI. 搜索
查询对象创建方式
通过Query子类来创建查询对象
通过QueryParser来创建查询对象(常用)
通过Query子类创建
Query子类常用的有:TermQuery、TermRangeQuery、BooleanQuery等。这种方式不能输入lucene的查询语法,不需要指定分词器。
精确的词项查询 TermQuery
@Test
public void termQuery() throws IOException {
Query query = new TermQuery(new Term("id", "998692"));
doSearch(query);
}
private void doSearch(Query query) throws IOException {
// 创建IndexSearcher
// 指定索引库的地址
Path indexFile = Paths.get("E:\\search-learn\\data");
Directory directory = FSDirectory.open(indexFile);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = indexSearcher.search(query, 2);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc;
// 通过ID获取文档
Document doc = indexSearcher.doc(docId);
System.out.println(doc.get("id"));
System.out.println(doc.get("title"));
System.out.println(doc.get("sellPoint"));
System.out.println(doc.get("barcode"));
System.out.println(doc.get("image"));
System.out.println(doc.get("price"));
System.out.println(doc.get("cid"));
System.out.println(doc.get("num"));
System.out.println(doc.get("status"));
System.out.println(doc.get("created"));
System.out.println(doc.get("updated"));
System.out.println("=================");
}
// 关闭资源
reader.close();
}范围查询TermRangeQuery
@Test
public void termRangeQuery() throws IOException {
Query query = new TermRangeQuery("id", new BytesRef("123455"), new BytesRef("123457"), true, true);
doSearch(query);
}组合查询BooleanQuery
@Test
public void booleanQuery() throws IOException {
Query query1 = new TermQuery(new Term("barcode", "323233"));
Query query2 = new TermQuery(new Term("sellPoint", "手"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(query1, BooleanClause.Occur.MUST);
builder.add(query2, BooleanClause.Occur.SHOULD);
BooleanQuery query = builder.build();
doSearch(query);
}组合关系代表的意思如下:
MUST和MUST表示“与”的关系,即“交集”。
MUST和MUST_NOT前者包含后者不包含。
MUST_NOT和MUST_NOT没意义。
SHOULD与MUST表示MUST,SHOULD失去意义。
SHOUlD与MUST_NOT相当于MUST与MUST_NOT。
SHOULD与SHOULD表示“或”的概念。
通过QueryParser类创建
QueryParser、MultiFieldQueryParser等,可以输入lucene的查询语法、可以指定分词器。
QueryParser
通过QueryParser来创建query对象,可以指定分词器,搜索时的分词器和创建该索引的分词器一定要一致。还可以输入查询语句。具体参考入门案例
多域查询MultiFieldQueryParser
@Test
public void multiFieldQuery() throws Exception {
// 默认搜索多个域名
String[] fields = {"title", "sellPoint"};
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer());
Query query = parser.parse("手"); // 相当于title:手 OR sellPoint:手
doSearch(query);
}
TopDocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
| 属性 | 说明 |
|---|---|
| long totalHits | 匹配搜索条件的总记录数 |
| ScoreDoc[] scoreDocs | 顶部匹配记录 |
| float maxScore | 最高匹配度 |
VII. 相关度排序
相关度排序就是查询关键字与查询结果的匹配相关度。匹配越高的越靠前。Lucene是通过打分来进行相关度排序的。
打分分两步:
根据词计算词的权重
根据词的权重进行打分
词的权重:词指的就是Term。也就是说一个Term对一个文档的重要性,就叫词的权重。影响词的权重的方式有两种:
Tf (词在同一个文档中出现的频率)——Tf越高,说明词的权重越高
Df(词在多个文档中出现的频率)——Df越高,说明词的权重越低
以上是自然打分的规则,Lucene可以通过设置Boost值来进行手动调整。设置加权值可以在创建索引时设置,也可以在查询时设置。
创建索引时设置
新版索引时设置权值被废除,最新API如何使用还没有研究清楚 :(
查询时设置
BoostQuery
@Test
public void booleanQuery() throws IOException {
Query query1 = new TermQuery(new Term("title", "电"));
Query query2 = new TermQuery(new Term("sellPoint", "手"));
// 利用BoostQuery包装Query
BoostQuery query3 = new BoostQuery(query2, 100f);
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(query3, BooleanClause.Occur.MUST);
builder.add(query2, BooleanClause.Occur.MUST);
BooleanQuery query = builder.build();
doSearch(query);
}MultiFieldQueryParser
@Test
public void multiFieldQuery() throws Exception {
String[] fields = {"title", "sellPoint"};
Map<String, Float> boosts = new HashMap<>();
boosts.put("title", 100f);
// 利用MultiFieldQueryParser构造函数传参
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer(), boosts);
Query query = parser.parse("通");
doSearch(query);
}
VIII. 中文分词
Lucence自带分词器,对于中文分词支持不是很好。所以需要第三方中文分词器。
IK-analyzer
最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
下载:支持Lucence7.x版本
将jar包加入工程,修改创建索引的分词器为中文分词器:
// 创建分词器,中文分词器
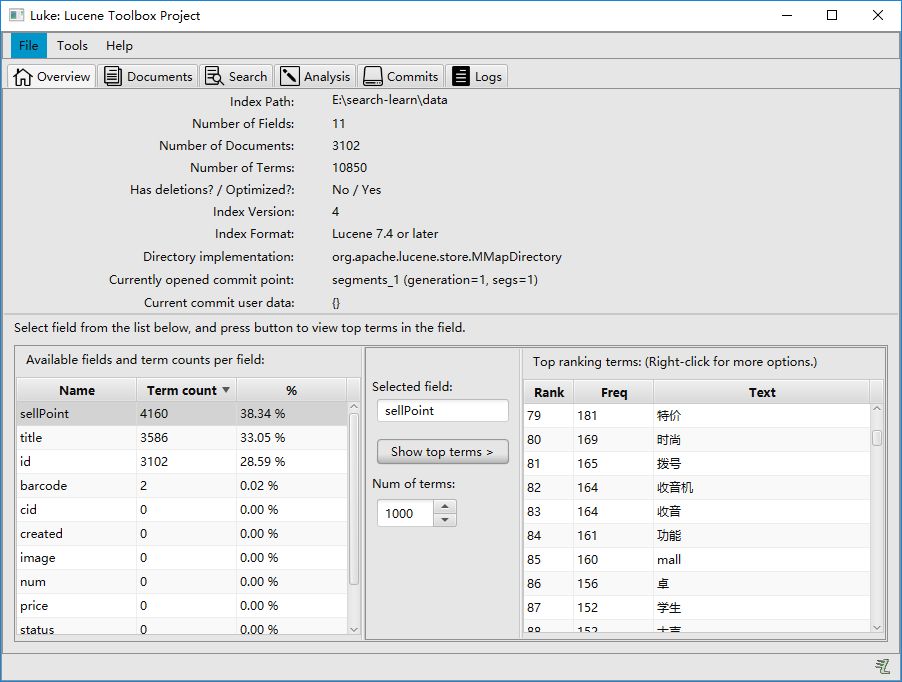
Analyzer analyzer = new IKAnalyzer();
创建索引结果:
自定义词库
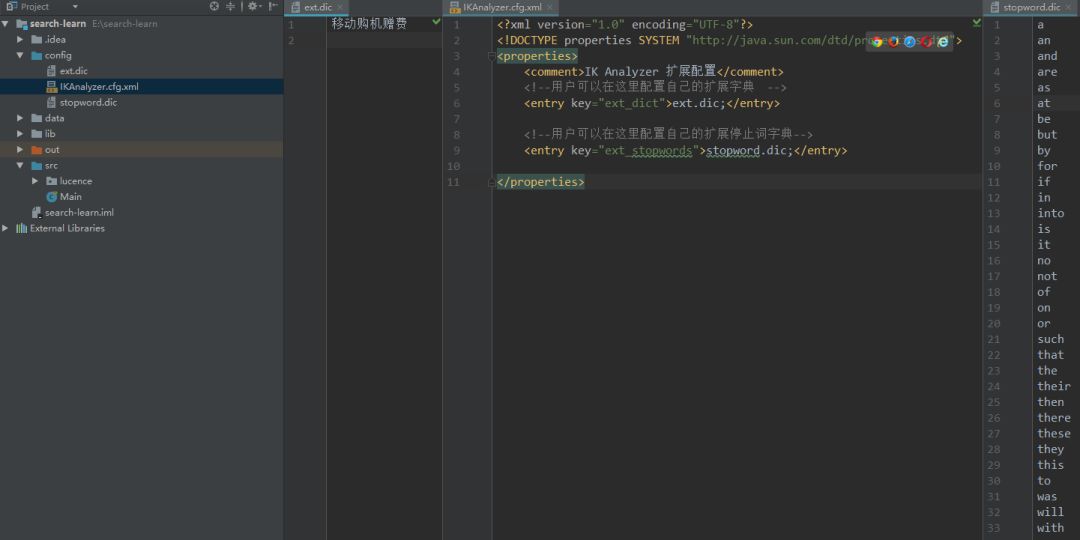
添加配置文件在工程的classpath下:
ext.dic 自定义扩展词
stopword.dic 自定义停用词
IKAnalyzer.cfg.xml 配置文件
@因博而起
晨博勿需太久 只此一篇就够
微信:wgp1234qwer
来源:个人撰写
以上是关于全文检索之Lucene框架的主要内容,如果未能解决你的问题,请参考以下文章