Lucene的全文检索学习
Posted 推荐师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene的全文检索学习相关的知识,希望对你有一定的参考价值。
亲,欢迎关注哦!↑↑↑
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/
1、什么是Lucene?
Lucene 是 apache 软件基金会的一个子项目,由 Doug Cutting 开发,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的库,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene 是一套用于全文检索和搜寻的开源程式库,由 Apache 软件基金会支持和提供。
Lucene 提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
ElasticSearch存在自己的生态系统,ELK,E是指ElasticSearch即全文检索,L是指Logstash即数据采集,K是指Kibana即报表。
ElasticSearch是基于Lucene的分布式全文检索系统,可以认为是一个分布式的NoSql数据库,而且支持全文检索。
Lucene是一个单机版程序,Es是一个集群版,底层使用的是Lucene,提供更方便的操作API。
注意:数据库和全文检索的区别。
b、全文检索可以快速,准确找到你想要的数据,快是指先从索引库中查找,准是指对查询条件进行分词,然后对查询的结果进行相关度排序,得分越高,排的越靠前。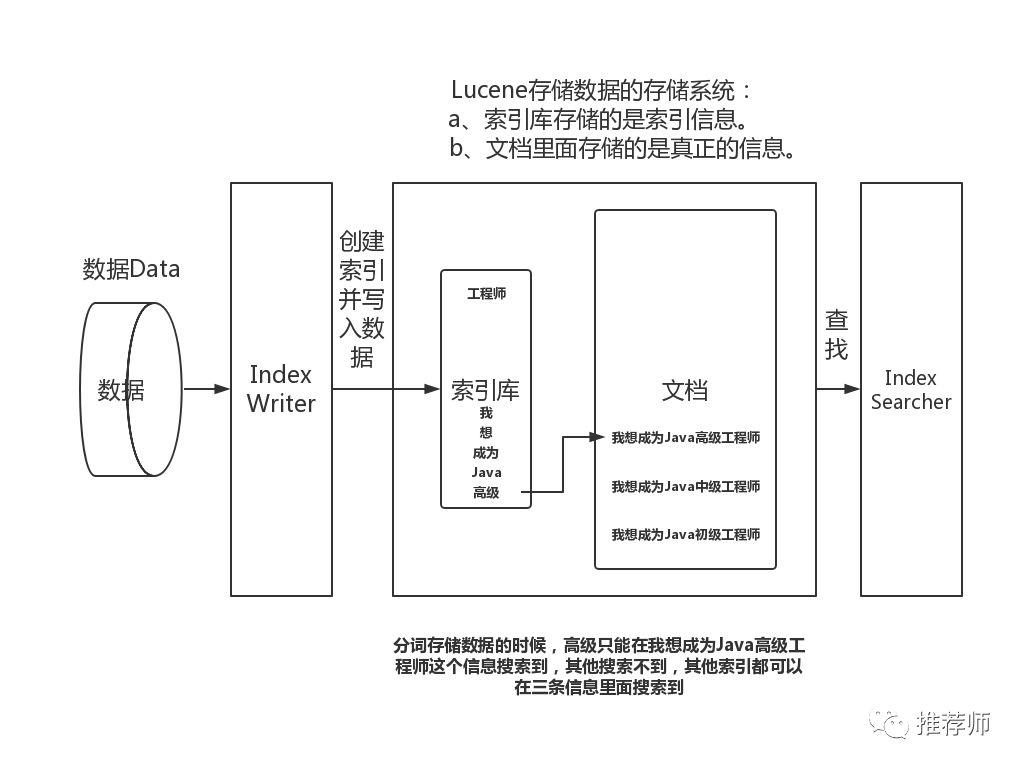
2、建立索引的过程,是先进行分词,建立索引,将文档存储的信息与索引进行关联。查询的过程,就是先到索引库中查找,然后查找出对应的文档ID,然后根据文档ID去文档库中查询出真正的文档。
项目使用maven创建,所以引入所需的依赖包。pom.xml配置如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.bie</groupId><artifactId>luceneDemo</artifactId><version>0.0.1-SNAPSHOT</version><!-- 定义一下常量 --><properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><encoding>UTF-8</encoding></properties><dependencies><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.3</version></dependency><dependency><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.2</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><scope>test</scope></dependency><!-- lucene的核心 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>6.6.0</version></dependency><!-- lucene的分词器,有标准的英文相关的分词器,没有中文的 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>6.6.0</version></dependency><!-- 查询解析器 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>6.6.0</version></dependency><!-- 各种查询方式 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queries</artifactId><version>6.6.0</version></dependency><!-- 关键字高亮 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>6.6.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-demo</artifactId><version>6.6.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.22</version></dependency></dependencies></project>
创建一个实体类,如下所示:
package com.bie.pojo;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field.Store;import org.apache.lucene.document.LongPoint;import org.apache.lucene.document.StoredField;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;/**** @author biehl**/public class Article {private Long id;private String title;private String content;private String author;private String url;public Article() {}public Article(Long id, String title, String content, String author, String url) {super();this.id = id;this.title = title;this.content = content;this.author = author;this.url = url;}public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}public String getAuthor() {return author;}public void setAuthor(String author) {this.author = author;}public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public Document toDocument() {// Lucene存储的格式(Map装的k,v)。Document doc = new Document();// 向文档中添加一个long类型的属性,建立索引。LongPoint不分词,建立索引。doc.add(new LongPoint("id", id));// 在文档中存储。doc.add(new StoredField("id", id));// 设置一个文本类型,会对内容进行分词,建立索引,并将内容在文档中存储。doc.add(new TextField("title", title, Store.YES));// 设置一个文本类型,会对内容进行分词,建立索引,存在文档中存储 / No代表不存储。doc.add(new TextField("content", content, Store.YES));// StringField,不分词,建立索引,Store.YES文档中存储。doc.add(new StringField("author", author, Store.YES));// StoredField不分词,不建立索引,在文档中存储。doc.add(new StoredField("url", url));return doc;}public static Article parseArticle(Document doc) {Long id = Long.parseLong(doc.get("id"));String title = doc.get("title");String content = doc.get("content");String author = doc.get("author");String url = doc.get("url");Article article = new Article(id, title, content, author, url);return article;}public String toString() {return "id : " + id + " , title : " + title + " , content : " + content + " , author : " + author + " , url : "+ url;}}
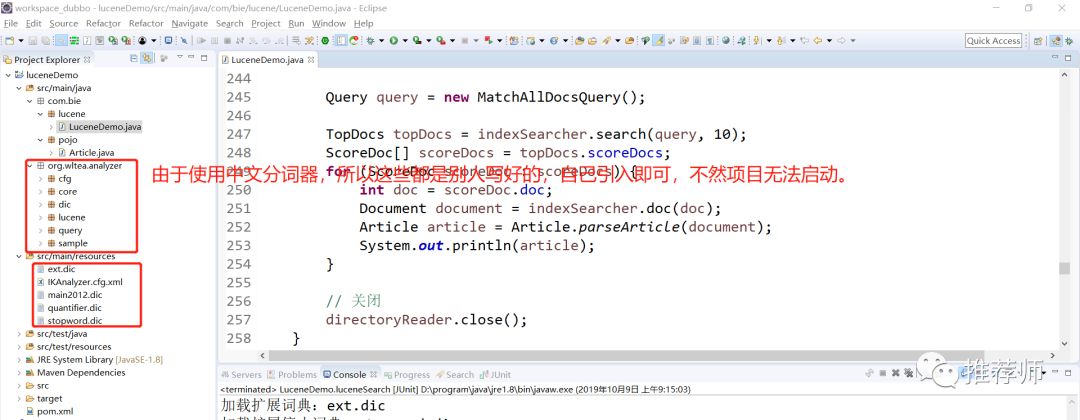
搭建的项目结构如下所示,由于使用了中文分词器,所以需要引入别人写好的依赖(原始作者很久不更新了,这个是github上面下载使用的),你可以打成jar包依赖进去也可以的,和配置文件,引入即可,不然项目无法正常启动。
IKAnalyzer.cfg.xml配置文件引入ext.dic、stopword.dic配置文件。
ext.dic配置文件是扩展词库,可以写入自己的词条。
stopword.dic配置文件是停用词库(不和谐的词条可以被停用掉的),可以写入停用的词条。
main2012.dic配置文件是标准的词典。里面是默认配置好的,不可以进行更改的。
然后就是你的主类了,主要包含,添加索引和文档,查询索引和文档,删除索引和文档,更新索引和文档(即先删除后插入),多字段查询索引和文档,全字段内查询索引和文档,组合查询,布尔查询索引和文档,非连续范围查找索引(相当于in or),连续范围查找(相当于<,>)。
package com.bie.lucene;import java.io.IOException;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.LongPoint;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;import org.apache.lucene.queryparser.classic.ParseException;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.BooleanClause;import org.apache.lucene.search.BooleanQuery;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.MatchAllDocsQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;import com.bie.pojo.Article;/**** @author biehl**/public class LuceneDemo {/*** 往用lucene写入数据** @throws IOException*/public void luceneCreate() throws IOException {// 创建几个文章对象Article article = new Article();article.setId(1008611L);article.setAuthor("别先生");article.setTitle("学习Lucene");article.setContent("好好学习,争取早日成为Java高级工程师,加油!别先生");article.setUrl("https://www.cnblogs.com/biehongli/p/11637267.html");Article article2 = new Article();article2.setId(1008612L);article2.setAuthor("别先生");article2.setTitle("学习Lucene");article2.setContent("好好学习,争取早日成为Java初级工程师,加油!别先生");article2.setUrl("https://www.cnblogs.com/biehongli/p/11637267.html");Article article3 = new Article();article3.setId(1008615L);article3.setAuthor("别先生");article3.setTitle("学习Lucene");article3.setContent("好好学习,争取早日成为Java中级工程师,加油!别先生");article3.setUrl("https://www.cnblogs.com/biehongli/p/11637267.html");// 指定数据写入到文件夹String indexPath = "F:\\lucene\\index";// 打开指定的文件夹FSDirectory fsDirectory = FSDirectory.open(Paths.get(indexPath));// 创建一个标准分词器StandardAnalyzer,一个字分一次// Analyzer analyzer = new StandardAnalyzer();// IKAnalyzer中文分词器Analyzer analyzer = new IKAnalyzer(true);// 写入索引的配置,设置了分词器IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// 指定了写入数据目录和配置IndexWriter indexWriter = new IndexWriter(fsDirectory, indexWriterConfig);// 创建一个文档对象。Lucene只识别文档格式。Document document = article.toDocument();Document document2 = article2.toDocument();Document document3 = article3.toDocument();// 通过IndexWriter写入indexWriter.addDocument(document);indexWriter.addDocument(document2);indexWriter.addDocument(document3);// 关闭IndexWriterindexWriter.close();}public void luceneSearch() throws IOException, ParseException {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// 中文分词器Analyzer analyzer = new IKAnalyzer(true);// Analyzer analyzer = new IKAnalyzer(true);DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);String queryStr = "工程师";// String queryStr = "高级";// 创建一个查询条件解析器QueryParserQueryParser parser = new QueryParser("content", analyzer);// 对查询条件进行解析Query query = parser.parse(queryStr);// TermQuery将查询条件当成是一个固定的词// Query query = new TermQuery(new Term("url",// "https://www.cnblogs.com/biehongli/p/11637267.html"));// 在【索引】中进行查找。10代表查询出前10条数据。TopDocs topDocs = indexSearcher.search(query, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {// 从索引中查询到文档的ID。int doc = scoreDoc.doc;// 在根据ID到文档中查找文档内容。Document document = indexSearcher.doc(doc);// 将文档转换成对应的实体类。Article article = Article.parseArticle(document);// 打印输出System.out.println(article);}// 关闭DirectoryReaderdirectoryReader.close();}public void luceneDelete() throws IOException, ParseException {// 指定要去删除的文件夹String indexPath = "F:\\lucene\\index";// 指定中文分词器Analyzer analyzer = new IKAnalyzer(true);// 打开指定的文件夹FSDirectory fsDirectory = FSDirectory.open(Paths.get(indexPath));// 写入索引的配置,设置了分词器IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// 指定了写入数据目录和配置IndexWriter indexWriter = new IndexWriter(fsDirectory, indexWriterConfig);// 几种查询删除的使用。// Term词条查找,内容必须完全匹配,不分词。// indexWriter.deleteDocuments(new Term("content", "学好"));// 指定查询条件,查询到的进行删除。// QueryParser parser = new QueryParser("title", analyzer);// Query query = parser.parse("高级");// LongPoint是建立索引的。在newRangeQuery某个范围内的都进行删除。// Query query = LongPoint.newRangeQuery("id", 1008611L, 1008612L);// LongPoint是建立索引的。支持等值查询。Query query = LongPoint.newExactQuery("id", 1008611L);// 删除指定的文档indexWriter.deleteDocuments(query);// 提交indexWriter.commit();System.out.println("==================================删除完毕!");// 关闭indexWriter.close();}/*** lucene的update比较特殊,update的代价太高,先删除,然后再插入。** @throws IOException* @throws ParseException*/public void luceneUpdate() throws IOException, ParseException {// 指定要去更新的文件夹String indexPath = "F:\\lucene\\index";// 指定标准的分词器// StandardAnalyzer analyzer = new StandardAnalyzer();// 指定中文分词器Analyzer analyzer = new IKAnalyzer(true);// 打开指定的文件夹FSDirectory fsDirectory = FSDirectory.open(Paths.get(indexPath));// 写入索引的配置,设置了分词器IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// 指定了写入数据目录和配置IndexWriter indexWriter = new IndexWriter(fsDirectory, indexWriterConfig);// 指定更新的实体类信息Article article = new Article();article.setId(1008611L);article.setAuthor("别先生");article.setTitle("学习Lucene");article.setContent("好好学习哦,争取早日成为Java高级工程师,加油啦啦!别先生");article.setUrl("https://www.cnblogs.com/biehongli/p/11637267.html");Document document = article.toDocument();// 更新文档indexWriter.updateDocument(new Term("author", "别先生"), document);// 提交indexWriter.commit();// 关闭indexWriter.close();}/*** 可以从多个字段中查找** @throws IOException* @throws ParseException*/public void luceneMultiField() throws IOException, ParseException {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// IKAnalyzer中文分词器Analyzer analyzer = new IKAnalyzer(true);// 打开指定的文件夹读取信息DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);// 指定多字段。可以从多个字段中查找String[] fields = { "title", "content" };// 多字段的查询转换器MultiFieldQueryParserMultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, analyzer);// 对查询条件进行解析Query query = queryParser.parse("别先生");// 在【索引】中进行查找。10代表查询出前10条数据。TopDocs topDocs = indexSearcher.search(query, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 遍历查找到的文档ID和得分for (ScoreDoc scoreDoc : scoreDocs) {// 获取到索引IDint doc = scoreDoc.doc;// 根据索引ID去文档里面进行查询即可Document document = indexSearcher.doc(doc);// 将查询到的文档信息转换为实体类,进行输出和业务需求Article article = Article.parseArticle(document);System.out.println(article);}// 关闭directoryReader.close();}/*** 查找全部的数据** @throws IOException* @throws ParseException*/public void luceneMatchAll() throws IOException, ParseException {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// 打开指定的文件夹读取信息DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);// 查找全部的数据Query query = new MatchAllDocsQuery();// 在【索引】中进行查找。10代表查询出前10条数据。TopDocs topDocs = indexSearcher.search(query, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 遍历查找到的文档ID和得分for (ScoreDoc scoreDoc : scoreDocs) {// 获取到索引IDint doc = scoreDoc.doc;// 根据索引ID去文档里面进行查询即可Document document = indexSearcher.doc(doc);// 将查询到的文档信息转换为实体类,进行输出和业务需求Article article = Article.parseArticle(document);System.out.println(article);}// 关闭directoryReader.close();}/*** 布尔查询,可以组合多个查询条件** @throws Exception*/public void testBooleanQuery() throws Exception {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// 打开指定的文件夹读取信息DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);// 多个查询条件。按照title查询Query query1 = new TermQuery(new Term("author", "别先生"));// 按照content查询Query query2 = new TermQuery(new Term("content", "哈哈哈"));// BooleanClause.Occur.MUST必须满足此条件BooleanClause bc1 = new BooleanClause(query1, BooleanClause.Occur.MUST);// BooleanClause.Occur.MUST_NOT必须不包含此内容。// +author:别先生 -content:哈哈哈。+是必须满足,-是不能满足。BooleanClause bc2 = new BooleanClause(query2, BooleanClause.Occur.MUST_NOT);// 相当于and。BooleanQuery boolQuery = new BooleanQuery.Builder().add(bc1).add(bc2).build();System.out.println(boolQuery);// 获取到查找到的文文档ID和得分TopDocs topDocs = indexSearcher.search(boolQuery, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 遍历查找到的文档ID和得分for (ScoreDoc scoreDoc : scoreDocs) {// 获取到索引IDint doc = scoreDoc.doc;// 根据索引ID去文档里面进行查询即可Document document = indexSearcher.doc(doc);// 将查询到的文档信息转换为实体类,进行输出和业务需求Article article = Article.parseArticle(document);System.out.println(article);}// 关闭directoryReader.close();}/**** @throws Exception*/public void luceneQueryParser() throws Exception {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// 打开指定的文件夹读取信息DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);// 创建一个QueryParser对象。参数1:默认搜索域 参数2:分析器对象。QueryParser queryParser = new QueryParser("title", new IKAnalyzer(true));// 条件组合// Query query = queryParser.parse("数据");// Query query = queryParser.parse("title:学习 OR title:Lucene");Query query = queryParser.parse("title:学习 AND title:Lucene");System.out.println(query);// 在【索引】中进行查找。10代表查询出前10条数据。TopDocs topDocs = indexSearcher.search(query, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 遍历查找到的文档ID和得分for (ScoreDoc scoreDoc : scoreDocs) {// 获取到索引IDint doc = scoreDoc.doc;// 根据索引ID去文档里面进行查询即可Document document = indexSearcher.doc(doc);// 将查询到的文档信息转换为实体类,进行输出和业务需求Article article = Article.parseArticle(document);System.out.println(article);}directoryReader.close();}/*** 范围查询** @throws Exception*/public void luceneRangeQuery() throws Exception {// 指定要去查询的文件夹String indexPath = "F:\\lucene\\index";// 打开指定的文件夹读取信息DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));// 索引查询器IndexSearcherIndexSearcher indexSearcher = new IndexSearcher(directoryReader);// 范围查找,相当于>、<这种范围查询。Query query = LongPoint.newRangeQuery("id", 1008611L, 1008622L);System.out.println("================================================" + query);// 在【索引】中进行查找。10代表查询出前10条数据。TopDocs topDocs = indexSearcher.search(query, 10);// 获取到查找到的文文档ID和得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 遍历查找到的文档ID和得分for (ScoreDoc scoreDoc : scoreDocs) {// 获取到索引IDint doc = scoreDoc.doc;// 根据索引ID去文档里面进行查询即可Document document = indexSearcher.doc(doc);// 将查询到的文档信息转换为实体类,进行输出和业务需求Article article = Article.parseArticle(document);System.out.println(article);}// 关闭directoryReader.close();}}
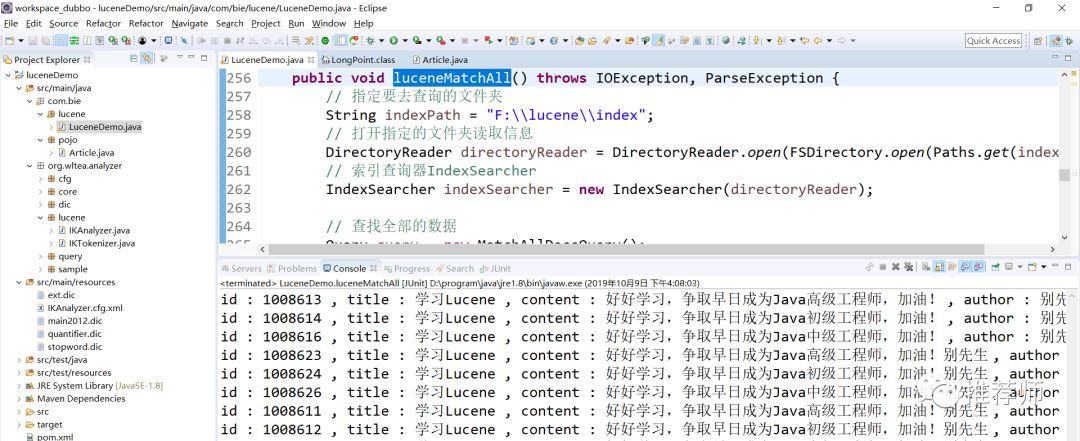
效果如下所示:
3、Luke 查看索引。
索引创建完成以后生成了如上的一批特殊格式的文件,如果直接用工具打开,会显示的都是乱码。可以使用索引查看工具 Luke 来查看。
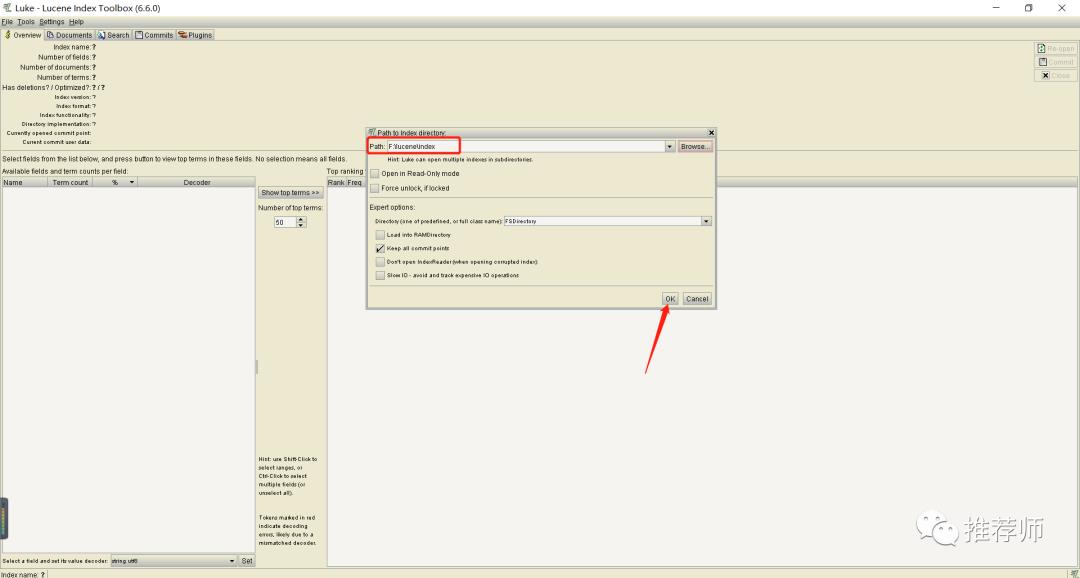
简单使用如下所示:
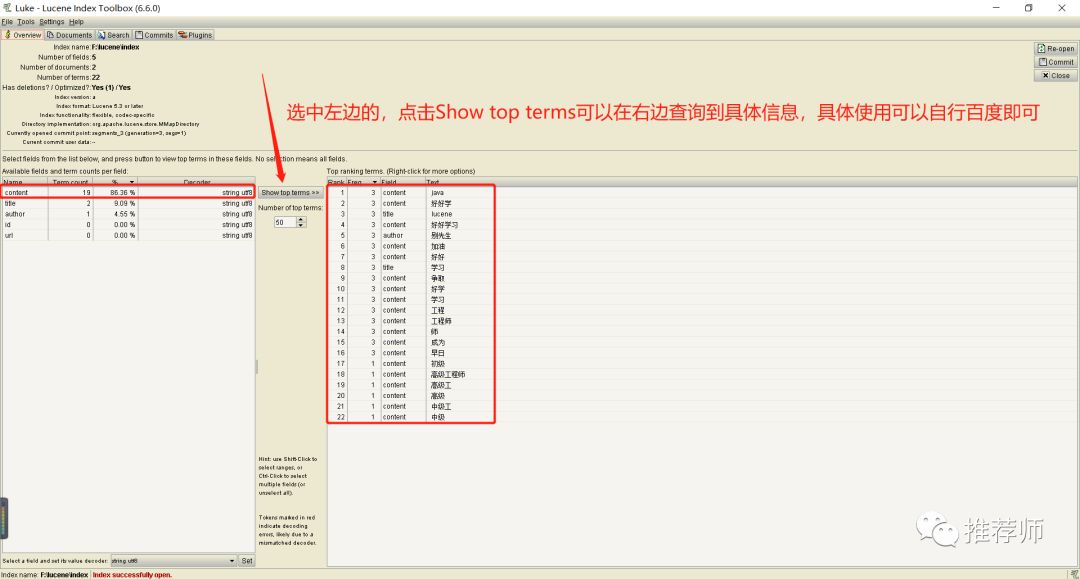
查找自己添加的信息如下所示:

End
Thank you for your reading.
合作:18513753639
~~~喜欢就点击在看哟! 以上是关于Lucene的全文检索学习的主要内容,如果未能解决你的问题,请参考以下文章