精选好文一个程序员:快速排序的优化和递归的问题
Posted Java我最强
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精选好文一个程序员:快速排序的优化和递归的问题相关的知识,希望对你有一定的参考价值。
作者 | 锅与盆
编辑 | Sandra
原文 | http://www.jianshu.com/p/6777a3297e36
最新独家视频教程资源《大型分布式项目实战:单点登录、分布式缓存、负载均衡》,后台回复“ 架构师03 ”即可获取。还有《高级架构师四十八个阶段高端课》、《Java高级互联网架构师课程》等更多独家视频教程资源等你下载哦!
写在前面的话
春招都讲究“金三银四”,三月份各种内推蜂拥而至,我的求职第一步却还迟迟没有迈出。我不想毫无准备就草草上阵,但由于复习的晚,时间上又特别紧张。最近感觉自己越来越焦虑了。面对向往的公司,就像面对喜欢的女生一样,渴望能在一起却又迟迟不敢迈出相遇的第一步。
最近忙着准备找工作,想赶在三月份结束前投一波内推。所以其实有挺多想分享的东西,却一直没时间更新博客。最近应该也不会写太多,毕竟这个还是挺花时间的。我想着这段时间憋个大招,等到过几个月如果拿到了满意的offer,就也像大神们一样写个面经,像什么《如果拿到XX公司offer》《我的面试经历》之类的文章供学弟学妹们膜拜一下,哈哈。当然这是求职成功的情况,我也不能保证你们肯定能看到我的这个大招。
写这篇文章的原因是今天对递归问题产生了一个疑惑,问了很多人,一直也没得到满意的答案。感觉这个问题挺有意思,就写出来和大家分享一下,也说说我的想法。因为是了解快排优化时候想到的问题,就连着快排优化也一起写了。
晚上写的,有点困,思路不太清晰。而且我也只是参考其他人的文章,分享下个人观点,可能有很多错误的想法或者没有说清楚的地方。如果有不同的观点欢迎讨论指正。下面进入正题。
快排深入探索
快排是一个经典并且被广泛应用的排序算法,是很重要的知识点。之前简单介绍过快排,相信大家随手写一个快排已经没有问题了。但是光知道怎么写是远远不够的,所以今天我们先继续探索下快排。
快排为什么快
之前分析过快排复杂度,当划分均衡时,平均时间复杂度O(nlogn),空间O(logn);当划分完全不均衡时,最坏时间O(n²),空间O(n)。而堆排序平均最坏时间复杂度都为O(nlogn),但为什么实际应用中快排效果好于堆排?
原因主要有三个:
1、虽然都是O(nlogn)级别,但是我们知道时间复杂度是近似得到的,快排前面的系数更小,所以性能更好些。
2、堆排比较交换次数更多。因为快排是枢轴(pivot)左边的元素都比pivot小,右边的元素都更大,比较交换次数会比堆排更少些。
具体可以参考下这篇文章。
http://mindhacks.cn/2008/06/13/why-is-quicksort-so-quick/
3、第三个原因也是最主要的原因,和cpu缓存(cache)有关。学计算机组成原理时候我们了解过,cpu有一块高速缓存区(cache)。堆排序要经常处理距离很远的数,不符合局部性原理,会导致cache命中率降低,频繁读写内存。不了解cache的同学可以看一下下面这篇文章。
http://blog.csdn.net/kobesdu/article/details/39081189
快排如何优化
快排就一定快吗?当然不是的。考虑如下情况:
A.划分不均匀
对于分治算法,当每次划分时,算法若都能分成两个等长的子序列时,那么分治算法效率会达到最大。如果输入序列有序(当然正常情况算法应该判断当序列有序时直接返回),我们选最左边元素做枢轴点,即划分极度不均匀时,不仅时间复杂度变成O(n²),递归深度也变成了n,这样很容易令栈内存溢出。所以要尽量避免这种情况。
B.当有大量重复元素时
每趟排序对每个子序列只产生一个有序位置, 所以对数组中相等元素的处理效率不是很高。如果有大量重复元素,实际上快排做了很多无用工作。由于划分函数的特点,对于一个每个元素都完全相同的一个序列来讲,快速排序也会退化到 O(n^2)。
针对上面两种情况,提出对应的优化方式a、b。
a. 优化枢轴点选取方式
1、三数取中,选三个数(也可以更多)作为样本,取其中位数作为枢轴点,这样划分更均衡。
2、直接找到中位数作枢轴点。选取中位数的可以在 O(n)时间内完成。证明见《算法导论(第二版) 》 第九章中位数。
b. 三分序列
经典快排分成大于枢轴和小于枢轴两堆,而遇到等于枢轴的元素时根据具体实现不同全部在枢轴左边或右边。所以才会导致元素全部一样时退化到O(n^2)的问题。所以改进方法是在分区的时候,将序列分为 3 堆,一堆小于中轴元素,一堆等于中轴元素,一堆大于中轴元。次递归调用快速排序的时候,只需对小于和大于中轴元素的两堆数据进行排序。
实现方法和荷兰国旗问题完全一样(关于荷兰国旗问题可以参考经典排序相关面试题)。
除了上面的两种优化方式,当序列很小时改用插排也是常用的优化方式。
C.小数组变插入排序
为什么当数据很少时要用插排呢?其实有时候当规模较小时分治算法效率是不如普通算法的。插入排序中包含的常数因子较小,使得当 n 较小时,算法运行得更快。因此,当数组递归子序列的规模在一个固定阀值(阀值指数组的最大长度)以下时,采用插入排序对子序列进行排序,能够缩短排序时间。一般阀值选取在 7到10 个元素,我记得Java里的Arrays.sort()方法好像是用的7个元素(当元素是基本类型时sort用的是优化版快排,当元素是对象时用的是归并排序,因为对于对象需要稳定性)。
D.多线程快排
首先要特别说明,多线程是个很重要的知识,无论在操作系统还是java语言里。面试中也是必问的东西,一定要好好掌握。
我们之前的优化都局限在单线程程序。快速排序对每个子序列的排序都是独立的,因此快排是比较适合用多线程实现的。那为什么要用多线程实现呢?
对于多核处理器,单线程只会映射到一个CPU上,而多线程会映射到多个CPU上,这样多线程实现的快排可以利用计算机的并行处理能力来提高排序的性能。这也是写多线程排序的实际应用场景。
对于单核处理器,多线程技术在一些情况如涉及大量IO,也可以起到最大限度地利用CPU资源的这个目的。不过对于快排这种情况,仅仅是做一种简单的计算,其间不涉及任何可能是使线程挂起的操作,如I/O读写,等待某种事件等等。多个线程与单个线程相比,增加了切换的开销,理论上应该更慢,所以在这种情况下,并没有必要使用什么多线程、并行的技术来优化快排,没什么实际意义,还不如多从别的角度想想有没有优化空间。
而我在网上看到的一些文章,他们写的多线程排序其实并不是考虑多核并行这个特性,各线程只是并发的(注意并行和并发区别)。这些代码可能双核的机器生成了有上千个线程,但是他们的测试结果却非常快,如果和单线程程序比较发现快了几个数量级。
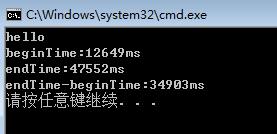
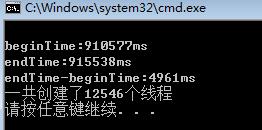
图片来自该文章
http://blog.sina.com.cn/s/blog_c33b15000102x3ls.html
(注意这篇博客里写的利用计算机并行处理能力是不准确的,如果仅仅希望利用计算机的并行能力,双核的电脑写两个线程处理就可以达到)
这样做能大大提高运行时间的真正原因是,多个线程可以让操作系统分给程序更多的时间片来执行代码。这和操作系统的调度策略有关。对同样一个进程来讲,多一个线程就可以多分到CPU时间。举例说明,假如在你的程序启动前,系统中已经有50个线程在运行,那么当你的程序启动后,假如他只有一个线程,那么平均来讲,它将获得1/51的CPU时间,而如果他有两个线程,那么就会获得2/52的CPU时间(这里仅仅是举例,真实情况当然更复杂),就是说这样做只是提高了快排程序抢夺资源的能力,相应的,其他程序运行时间就要更久一点。
多线程版的快速排序,还没来得及亲自实现。正好最近在看《Thinking in Java》,等看到并发的时候一定要自己写一个多线程的快排。我也强烈推荐你这么做。因为我觉得如果面试时候聊到了快排,能把常用的优化方式说出来只能令面试官觉得你基础不错。但是如果能随手写出来一个多线程版的快排,聊一聊这么做的利弊,那一定能让人眼前一亮。
另外Java7里提供了一个用于并行执行任务的框架,Fork/Join框架。如果你能继续“不经意间”提起Java7的这个新框架,再用Fork/Join再写一个,然后聊聊Java7\8的新特性,那面试官的表情一定是下面这样的。

友情提示:装逼有风险,实践需谨慎
下面是我看的几篇文章,详细介绍了多线程快速排序的内容,大家可以好好看看。因为还没亲自实现,我就先不贴代码了。不过需要注意搞清楚到底是因为什么原因他们的代码提升了效率。就像我上面分析的一样,其实有些代码并不完全依靠多核并行的优势,更大程度是靠多线程获得更多CPU时间。这也可以解释为什么有的文章里分别实现了普通多线程版和Fork Join版,测试后却发现用Fork/Join的程序并没有提高效率。
参考文章:
http://xueshu.baidu.com/s?wd=paperuri%3A%2849940c24be6eb4d18b7f2ef4791caee2%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fd.g.wanfangdata.com.cn%2FPeriodical_wxjyyy201616007.aspx&ie=utf-8&sc_us=1579342160275162004
http://www.tuicool.com/articles/nQfMRb
http://www.oschina.net/code/snippet_145230_44938
http://blog.csdn.net/wobenfengya/article/details/12318851
http://blog.csdn.net/wobenfengya/article/details/12422415
E. 按位拆分快速排序并行算法
关于这个算法我也不了解。是我在网上搜索资料的时候偶然看到一篇论文提到的。摘要如下:
针对大数据量排序算法优化问题,提出一种基于Java的按位拆分的排序新算法。该排序算法按照位拆分数据,并结合Java的多线程对拆分的数据进行并行处理。数据实验结果表明,对于大数据量排序,该算法性能明显优于快速排序算法,而且算法具有很好的并行效率。
我也没有仔细看。这里把链接附上,有兴趣的同学可以看看,弄明白了记得给我讲一下是怎么回事哦。
基于Java的按位拆分快速排序并行算法
http://xueshu.baidu.com/s?wd=paperuri:(e0f8751aacb0668b646665375d614a4d)&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http://www.cnki.com.cn/Article/CJFDTotal-JSJY201209021.htm&ie=utf-8&sc_us=1039127488433506999
F. 在知乎上看到的一个思路(存疑)
知乎上看到的一个答案里最后提了这么一句:
最后一个来自《算法导论》的丧心病狂的思路:选定一个 k,当序列长度小于 k 时,sort 函数直接不作处理返回原序列。整个序列经过这样一次 sort 之后当然不是有序的,此时对这个序列做一次插入排序(因为插入排序在处理 “几乎” 有序的序列时,运行非常快)。根据算导的结论,这样的复杂度是 O(nk + n log(n/k)) 的。
因为答主说了是来自《算法导论》里提供的思路,所以我就把它也算上了。但是我个人认为这个方法并没什么卵用。。。
我是这样分析它的复杂度的。按照这个思路,第一次快排的时间复杂度是O((n/k)log(n/k))≈O(nlogn-nlogk)(常系数k比较小忽略了)。针对这个几乎有序的序列,插排的复杂度是O(nk),两次加起来就是O(nlogn-nlogk+nk),和答主给的复杂度是一样的,但问题是O(nlogn-nlogk+nk)>O(nlogn)啊。。。这样做的目的是什么。。
其实看过我之前文章的同学应该知道,处理几乎有序序列最快的原地排序方式并不是插排,而是堆排方式。这种方式能把几乎有序序列的排序优化到O(n*logk),但即使这样,加起来总的复杂度还是
O(nlogn-nlogk+nlogk)=O(nlogn),这不是一样的吗?
也可能是我困了没想明白。。如果有不同意我想法的同学欢迎在评论区纠正。
递 归
快排就是一个递归算法,我们知道递归的问题是如果递归太深容易栈溢出。而针对快排的优化,还有一个角度是对递归的优化。网上很多文章都提到一个叫做尾递归优化的东西,比如下面这篇文章。
http://blog.csdn.net/gtzh110/article/details/48730131
尾递归
尾递归是尾调用(Tail Call)的一种。尾调用(Tail Call)是函数式编程的一个重要概念,就是指某个函数的最后一步是调用另一个函数(注意这里是最后一步,不是最后一行)。
具体概念看这两篇文章吧,我就不复述了。
尾调用优化 - 阮一峰的网络日志
http://www.ruanyifeng.com/blog/2015/04/tail-call.html
递归与尾递归总结
http://www.cnblogs.com/Anker/archive/2013/03/04/2943498.html
还有这个漫谈递归系列,写的也非常好,介绍了关于递归的各种知识,有兴趣的同学可以看一下。我觉得主要是函数式语言的程序员用得到尾递归,对于我们java程序员了解即可(我们一般直接写迭代了)。
漫谈递归:从斐波那契开始了解尾递归
http://www.nowamagic.net/librarys/veda/detail/2325
漫谈递归:尾递归与
CPShttp://www.nowamagic.net/librarys/veda/detail/2331
漫谈递归:补充一些Continuation的知识
http://www.nowamagic.net/librarys/veda/detail/2332
漫谈递归:PHP里的尾递归及其优化
http://www.nowamagic.net/librarys/veda/detail/2334
漫谈递归:从汇编看尾递归的优化
http://www.nowamagic.net/librarys/veda/detail/2336
所谓的“快排尾递归优化”
真的是尾递归优化吗?
了解完什么是尾递归后,我反而对“快速排序的尾递归优化”的方法产生了疑问。比如有博客里是这么写的:
QUICKSORT中的第二次递归调用并不是必须的,可以用迭代控制结构来代替它,这种技术叫做“尾递归”,大多数的编译器也使用了这项技术。
关键代码如下:
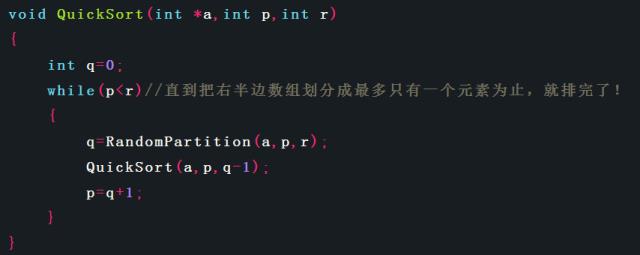
首先上面代码中递归调用并不是最后一步,甚至最后一行都不是,和我们上面看到的尾递归的定义不太一样。如果我们暂且不考虑它到底是不是尾递归,那么用这样的方式到底能不能降低递归深度呢?
Erlang学习:快速排序和尾递归
http://nxlhero.blog.51cto.com/962631/1112835
这篇文章里分析了一下为什么可以降低递归深度。但是我个人认为这样做是完全不能起到优化作用的。我们可以自己举个具体例子,画个递归树。我得出的结果是普通递归的快排和所谓的“尾递归优化”的快排的递归过程是一样的,都是先对枢轴左边的子数组递归调用,再对枢轴右边的子数组递归调用。上面代码的只是把对枢轴右边的子数组的递归调用放到了下一次循环里。所以我觉得只是换了个写法而已,实质并么有改变。而且我们也举个极端点的例子,就是划分极度不均衡,每次枢轴点右面的子数组大小都为0,递归树此时所以节点都只有左孩子,退化成一条链表,此时递归深度为n。然后用上面代码模拟一下发现递归深度还是n,没有优化。所以对于很多博客里给出的这种思路我是不赞同的。
那么快排有没有办法写成真正的尾递归的形式呢?要弄明白这个问题,就要思考什么样递归可以改成尾递归,什么样的递归不能改,是不是所有递归都可以改?
深入尾递归
先给出我的结论,快排可以写成真正的尾递归形式,而且所以的递归都可以写成尾递归的形式。因为尾递归和循环本质上是一样的(参考上面从汇编角度讲尾递归优化那篇文章,可以理解成编译器会把尾递归优化成循环),我们可以用人工模拟系统栈的方式用循环改写所有递归,那么尾递归也同样可以这样做。但是这么做究竟有没有意义,就是另一个需要讨论的话题了。
通过阮一峰的尾调用优化
(http://www.ruanyifeng.com/blog/2015/04/tail-call.html)这篇文章里的例子,我们可以发现,其实文章里给的例子可以很轻松的写成循环形式。因为尾递归实际上就是把每次变化的变量通过参数传递给递归函数了,跟我们平时写循环不断更新局部变量是一样的。而事实上java程序员们也是这么做的,因为java编译器不提供尾递归优化,所以遇到这样的能写成尾递归的问题大家一般都直接用循环写了。就像下面求阶乘的代码所示。
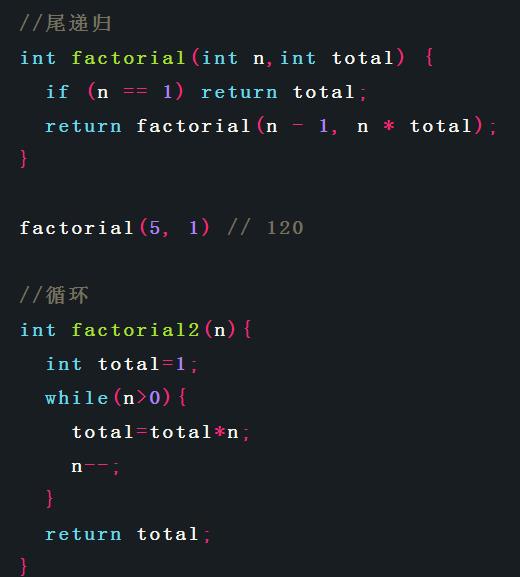
们可以发现,其实上面尾递归函数和循环函数是一样的,都是通过变量total保存函数运算结果,然后通过参数传递给下层递归函数。
如果我们可以确切的知道下层函数需要从上层函数得到什么信息,就可以像上面的方法一样,把所有用到的内部变量改写成函数的参数。但是我们知道很多递归函数是不满足这种情况的。比如快排,比如二叉树的深度优先遍历。在回溯的过程我们需要知道所有上层函数的信息,而这些信息,也就是递归深度,是不确定的,不能通过固定的参数传递。
但是如果我们把一个栈结构(List)作为参数呢?这样不就可以把所有函数调用信息传递下去了。就像How to implement tail-recursive quick sort in Scalastack overflow
(https://stackoverflow.com/questions/9247504/how-to-implement-tail-recursive-quick-sort-in-scala)里的这个问题里的做的一样。如果我写的不清楚,你可以看一下这个回答,里面有实现代码,不过是scala的,看着有点费劲。
我觉得主要是函数式语言的程序员会使用这样的方式把普通递归改写成尾递归,毕竟函数式语言没有循环结构。对于java程序员来说都是直接用循环写了。但是这两种方式本质上是一样的。都是用人工模拟系统栈的思路实现的。把系统栈转化成建在堆上的人工栈。就像上面stack overflow里回答的一样。
Any recursive function can be be converted to use the heap, rather than the stack, to track the context. The process is calledtrampolining.
Tail recursion requires you to pass work, both completed and work-to-do, forward on each step. So you just have to encapsulate your work-to-do on the heap instead of the stack. You can use a list as a stack, so that's easy enough.
关于那个trampolining,是函数式编程里的一个概念,也是为了优化递归(因为递归对于函数式编程非常关键)。跟我想表达的东西没什么联系,如果对它好奇,可以跳转到下面的链接What is a trampoline function?
(https://stackoverflow.com/questions/189725/what-is-a-trampoline-function)。
写到这里我的体会就是:
1、函数式编程有必要了解一点,尤其是现在scala这么火。
2、多上上国外的程序员论坛还是有好处的,有些东西英文资料更多一些。
3、要多思考,多学习。
递归与非递归
写到这里,关于快排能不能尾递归优化的问题已经解决了,我的回答就是快排可以写成尾递归,但这是函数式语言程序员喜欢做的事,和java程序员用循环改写递归是一样的。那么接下来的问题就是这么做有意义吗?或者说,有没有必要把所有递归改写成循环?快排改成非递归版速度能更快吗?
关于递归和非递归的问题,也分两个阵营,循环党和递归党。由于以前受到过爆菊爆栈的伤害,而且一直听到的观点就是递归调用有栈溢出问题,并且效率低,只是写着简单点,思路好理解。所以我之前一直是坚定的循环党,奉行循环至上,属于遇到递归算法就一定会想办法写个非递归版本出来那种,平时也喜欢动不动就拿个非递归版的算法来炫耀。
但如果递归真的一无是处,函数式语言为什么要用递归表示循环?Java里的Arrays.sort方法为什么不写成非递归的?于是信仰不坚定的我很快就改阵营了。。。
我的想法是,栈空间比较小,递归深度太深时容易栈溢出,用自己维护一个栈来模拟递归的方式,虽然空间复杂度一样,但可以把这部分内存转移到堆上,防止栈溢出。在时间效率上,递归在函数调用上也有一个时间开销。
但问题是,其实我们在写递归时候,如果遇到栈溢出情况,往往是我们自己的算法有问题,而不是递归本身的问题。比如快排没有随机化选取枢轴时递归深度可能为n,但如果合理设计算法,去掉冗余,logn的递归深度一般是不会导致栈溢出的。即使是TB级别的数据,递归深度也不过是40个栈帧(当然这么算是不准确的,只是为表达我的意思)。而且栈是不是会爆掉这个很大程度上是取决于程序员对程序的把控的。比如说如果程序写的不好,在栈帧内存放大的数据,比如递归函数里申请 1KB 的栈上空间(例如写一个 char s[1024]; ),这个递归函数的最大调用深度达到 100 以上,就会导致 stack overflow(假设栈空间100KB)。如果输入数据稍微大一点就爆栈,首先应该反思自己的算法设计和代码,而不是归罪于递归。有大量冗余过程的算法,即使通过在堆上维护人工栈避免了栈溢出,也会因为太久的运行时间令人难以忍受。
而关于时间效率问题,虽然函数调用有时间开销。但是函数调用的开销主要是参数信息的压栈出栈,跳转(jmp or call),其中压栈出栈在非递归算法里也要执行,而且由于自己维护的栈在堆上,涉及到开辟空间和垃圾回收,List容量不够扩容时也需要额外的时间开销,速度反而比系统栈更慢。另外现在编译器对递归也会进行优化,所以说递归时间效率上更慢我觉得也是不妥的。即使有差距,应该也小到可以说是效率几乎一样了。
所以我觉得,既然递归有这么大的表现力,而且效率也并不更低,为什么要牺牲掉简洁优雅的代码,去费劲改成循环呢?当然我这里指的是那种需要人工模拟系统栈去模拟递归过程的递归。而像上面提到的求阶乘的那种递归,我认为都是属于不必要的递归,因为可以很轻松的用循环实现。或者也可以称为是可以优化的递归。总之,优化算法,最重要的应该是结合具体情况对算法本身优化,而不是粗暴的把递归改成非递归。
Java我最强
关心Java人成长的技术内容社区
快速关注
以上是关于精选好文一个程序员:快速排序的优化和递归的问题的主要内容,如果未能解决你的问题,请参考以下文章