大佬的快速排序算法,果然不一样
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大佬的快速排序算法,果然不一样相关的知识,希望对你有一定的参考价值。
前言
快速排序,正如它的名字所体现,是在实践中已知的最快的排序算法,平均运行时间为O(NlogN),最坏的运行时间为O(N^2)。算法的基本思想很简单,然而想要写出一个高效的快速排序算法并不是那么简单。基准的选择,元素的分割等都至关重要,如果你不清楚如何优化快速排序算法,本文你不该错过。
阅读字数:7297 | 大约15~19分钟阅读
算法思想
快速排序利用了分治的策略。而分治的基本基本思想是:将原问题划分为若干与原问题类似子问题,解决这些子问题,将子问题的解组成原问题的解。
那么如何利用分治的思想对数据进行排序呢?假如有一个元素集合A:
选择A中的任意一个元素pivot,该元素作为基准
将小于基准的元素移到左边,大于基准的元素移到右边(分区操作)
A被pivot分为两部分,继续对剩下的两部分做同样的处理
直到所有子集元素不再需要进行上述步骤
可以看到算法思想比较简单,然而上述步骤实际又该如何处理呢?
如何选择基准
实际上无论怎么选择基准,都不会影响排序结果,但是不同的选择却可能影响整体排序时间,因为基准选择不同,会导致分割的两个集合大小不同,如果分割之后,两个集合大小是几乎相等的,那么我们整体分割的次数显然也会减少,这样整体耗费的时间也相应降低。我们来看一下有哪些可选择策略。
如果待排序数是随机的,那么选择第一个或者最后一个作基准是没有什么问题的,这也是我们最常见到的选择方案。但如果待排序数据已经排好序的,就会产生一个很糟糕的分割。几乎所有的数据都被分割到一个集合中,而另一个集合没有数据。这样的情况下,时间花费了,却没有做太多实事。而它的时间复杂度就是最差的情况O(N^2)。因此这种策略是绝对不推荐的。
随机选择基准是一种比较安全的做法。因为它不会总是产生劣质的分割。
C语言实现参考:
ElementType randomPivot(ElementType A[],int start,int end)
{
srand(time(NULL))
int randIndex = rand()%(end -start)+start;
return A[randIndex];
}从前面的描述我们知道,如果能够选择到数据的中值,那是最好的,因为它能够将集合近乎等分为二。但是很多时候很难算出中值,并且会耗费计算时间。因此我们随机选取三个元素,并用它们的中值作为整个数据中值的估计值。在这里,我们选择最左端,最右端和中间位置的三个元素的中值作为基准。
假如有以下数组:
1 9 10 3 8 7 6 2 4左端元素为1,位置为0,右端元素为4,位置为8,则中间位置为[0+8]/2=4,中间元素为8。那么三数中值就为4(1,4,8的中值)。
如何将元素移动到基准两侧
选好基准之后,如何将元素移动到基准两侧呢?通常的做法如下:
将基准元素与最后的元素交换,使得基准元素不在被分割的数据范围
i和j分别从第一个元素和倒数第二个元素开始。i在j的左边时,将i右移,直到发现大于等于基准的元素,然后将j左移,直到发现小于等于基准的元素。i和j停止时,元素互换。这样就把大于等于基准的移到了右边,小于等于基准的移到了左边
重复上面的步骤,直到i和j交错
将基准元素与i所指向的元素交换,使得基准元素将整个元素集合分割为小于基准和大于基准的元素集合
在们采用三数中值得方法选择基准的情况下,既然基准是中值,实际上只要保证左端,右端,中间值是从小到大即可。还是以前面提到的数组为例,我们找到三者后,对三者进行排序如下:
排序前

排序后

如果是这样的情况,那么实际上不需要把基准元素和最后一个元素交换,而只需要和倒数第二个元素交换即可,因为最后一个元素肯定大于基准,这样可以减少交换次数。
如果前面的描述还不清楚,我们看一看实际中一趟完整的流程是什么样的。
第一步,将左端,右端和中间值排序,中值作为基准:
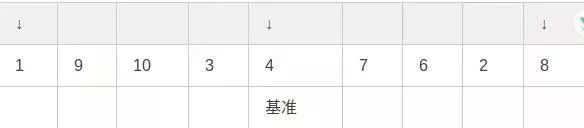
第二步,将中值与倒数第二个数交换位置:
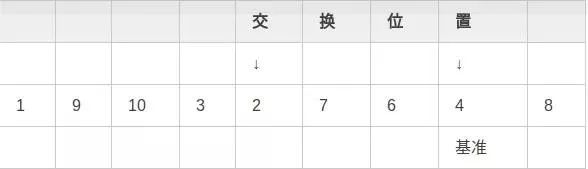
第三步,i向右移动,直到发现大于等于基准的元素9:
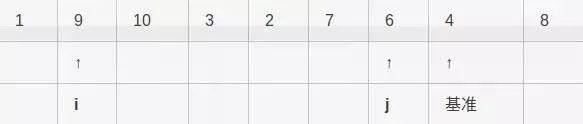
第四步,j向左移动,直到发现小于等于基准的元素2:
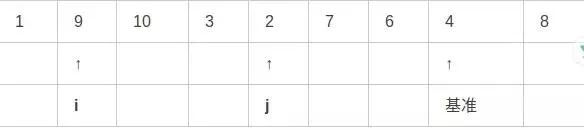
第五步,交换i和j:
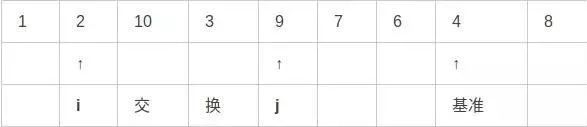
第六步,重复上述步骤,i右移,j左移:
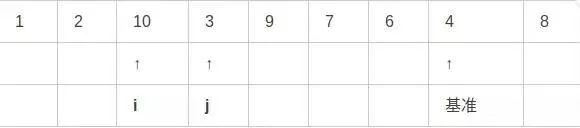
第七步,交换i和j指向的值:
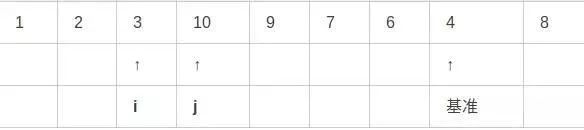
第八步,重复上述步骤,i右移,j左移,此时i和j已经交错:
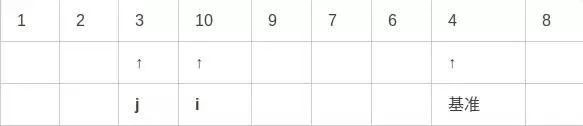
第九步,i和j已经交错,因此最后将基准元素与i所指元素交换:
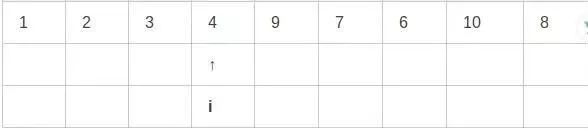
如何对子集进行排序到这一步的时候,我们发现i的左边都是小于i指向的元素,而右边都是大于i的元素。最后在对子集进行同样的操作即可。
最常见的便是递归法了。递归的好处是代码简洁易懂,但是不可忽略的是,当递归嵌套过深时,它的效率问题以及栈溢出的风险可能会迫使你选择非递归法。在前面对整个集合一分为二之后,对剩下的两个集合递归调用,直到完成排序。简单描述如下(非可运行代码):
void Qsort(int A[],int left,int right)
{
/*分区操作*/
int i = partition(A,left,right);
/*对子集递归调用*/
Qsort(A,left,i-1);
Qsort(A,i+1,right);
}
递归最需要注意的便是递归结束调用,否则会产生无限递归,从而发生栈溢出。
后面我们会看到,递归法的代码非常简洁。(相关阅读《》)
在递归版本中,Qsort分别递归调用计算左右两个子集合,而第二个递归其实并非必须,完全可以用循环来替代,以下代码模拟实现了尾递归,(并非是真的尾递归):
void Qsort(ElementType A[],int left,int right)
{
int i = 0;
while(left < right)
{
/*分割操作*/
i = partition(A,left,right);
/*递归调用*/
Qsort(A,left,i-1);
/*右半部分通过循环实现*/
left = i + 1;
}
}那么有没有方法可以不用递归呢?既然递归每次都进行压栈操作,那么我们能不能分区后仅仅将区间信息存储到栈里,然后从栈中取出区间再继续分区呢?显然是可以的。实际上我们每次分区时,只需要知道区间即可,那么将这些区间信息存储起来,就可以不用递归了,按照分好的区间不断分区即可。
例如对于前面提到的数组,首先对区间[0,8]进行分区操作,之后得到两个新的分区,1,2,3和9,7,6,10,8,假设两个区间仍然可以使用快速排序,那么需要将区间[0,2]和[5,8]的其中一个压栈,另一个继续分区操作。
按照这种思路,代码简单描述如下(非可运行代码):
void Qsort(A,left,right)
{
while(STACK_IS_NOT_EMPTY)
{
/*分区操作*/
POP(lo,hi);
int mid = partition(A,lo,hi);
/*存储新的边界*/
PUSH(lo,mid-1);
PUSH(mid+1,hi);
}
}当然这里面没有体现分区终止条件。我们需要在数据量小于一定值的时候,就不再继续进行分区操作了,而是选择插入排序(为什么?)。
那么问题来了,如何选择栈的大小呢?查看qsort.c的源码发现,它选择了如下的值:
#define STACK_SIZE (8* sizeof(unsigned long int));为什么会是这个值呢?设想一下,假设待排序数组长度使用unsigned long int来表示,并且假设每次都将集合分为二等分。那么即便数组长度达到最大值,实际上最多只需要分割8 *(sizeof(unsigned long int))次,也就将它分割完了。然而由于以下几个原因,需要存储在栈中的区间信息很难超出栈空间,因为:
数组长度不会接近unsigned long int,否则内存也撑不住了
区间足够小时,不采用快速排序
每做一个分区,只会增加一个区间PUSH到栈中,增长速度慢
注意事项
至此,快速排序所有的主要步骤已经介绍完毕。但是有以下注意事项:
有大量重复元素时避免产生糟糕分区,因此在发现大于等于基准或者小于等于基准时,便停止扫描。
通常会将基准一开始移动到最后位置或倒数第二个位置,避免基准在待分区区间。
对于很小的数组(N<=20),插入排序要比快速排序更好。因为快速排序有递归开销,并且插入排序是稳定排序。
如果函数本身的局部变量很少,那么递归带来的开销也就越小;如果递归发生栈溢出了,首先需要排除代码设计问题。因此如果你设计的非递归版本效率低于递归版本,也不要惊讶。
注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。--来自百科
递归版代码实现
C语言代码实现如下:
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
/*使用快速排序的区间大小临界值,可根据实际情况选择*/
#define MAX_THRESH 4
typedef int ElementType;
/*元素交换*/
void swap(ElementType *a,ElementType *b)
{
ElementType temp = *a;
*a = *b;
*b = temp;
}
/*插入排序*/
void insertSort(ElementType A[],int N)
{
/*优化后的插入排序*/
int j = 0;
int p = 0;
int temp = 0;
for(p = 1;p<N;p++)
{
temp = A[p];
for(j = p;j>0 && A[j-1] > temp;j--)
{
A[j] = A[j-1];
}
A[j] = temp;
}
}
/*三数中值法选择基准*/
ElementType medianPivot(ElementType A[],int left,int right)
{
int center = (left + right)/2 ;
/*对三数进行排序*/
if(A[left] > A[center])
swap(&A[left],&A[center]);
if(A[left] > A[right])
swap(&A[left],&A[right]);
if(A[center] > A[right])
swap(&A[center],&A[right]);
/*交换中值和倒数第二个元素*/
swap(&A[center],&A[right-1]);
return A[right-1];
}
/*分区操作*/
int partition(ElementType A[],int left,int right)
{
int i = left;
int j = right-1;
/*获取基准值*/
ElementType pivot = medianPivot(A,left,right);
for(;;)
{
/*i j分别向右和向左移动,为什么不直接先i++?*/
while(A[++i] < pivot)
{}
while(A[--j] > pivot)
{}
if(i < j)
{
swap(&A[i],&A[j]);
}
/*交错时停止*/
else
{
break;
}
}
/*交换基准元素和i指向的元素*/
swap(&A[i],&A[right-1]);
return i;
}
void Qsort(ElementType A[],int left,int right)
{
int i = 0;
register ElementType *arr = A;
if(right-left >= MAX_THRESH)
{
/*分割操作*/
i = partition(arr,left,right);
/*递归*/
Qsort(arr,left,i-1);
Qsort(arr,i+1,right);
}
else
{
/*数据量较小时,使用插入排序*/
insertSort(arr+left,right-left+1);
}
}
/*打印数组内容*/
void printArray(ElementType A[],int n)
{
if(n > 100)
{
printf("too much,will not print\n");
return;
}
int i = 0;
while(i < n)
{
printf("%d ",A[i]);
i++;
}
printf("\n");
}
int main(int argc,char *argv[])
{
if(argc < 2)
{
printf("usage:qsort num\n");
return -1;
}
int len = atoi(argv[1]);
printf("sort for %d numbers\n",len);
/*随机产生输入数量的数据*/
int *A = malloc(sizeof(int)*len);
int i = 0;
srand(time(NULL));
while(i < len)
{
A[i] = rand();
i++;
}
printf("before sort:");
printArray(A,len);
/*对数据进行排序*/
Qsort(A,0,len-1);
printf("after sort:");
printArray(A,len);
return 0;
}尾递归版代码实现
略
非递归版代码实现
非递归版与递归版大部分代码相同,Qsort函数有所不同,并且增加栈相关内容定义:
/*存储区间信息*/
typedef struct stack_node_t
{
int lo;
int hi;
}struct_node;
/*最大栈长度*/
#define STACK_SIZE 8 * sizeof(unsigned int)
/*入栈,出栈*/
#define STACK_PUSH( low, hig ) ( (top->lo = low), (top->hi = hig), top++)
#define STACK_POP( low, hig ) (top--, (low = top->lo), (hig = top->hi) )
/*快速排序*/
void Qsort( ElementType A[], int left, int right )
{
if(NULL == A)
return;
/*使用寄存器指针*/
register ElementType *arr = A;
if ( right - left >= MAX_THRESH )
{
struct_node stack[STACK_SIZE] = { { 0 } };
register struct_node *top = stack;
/*最大区间压栈*/
int lo = left;
int hi = right;
STACK_PUSH( 0, 0);
int mid = 0;
while ( stack < top )
{
/*出栈,取出一个区间进行分区操作*/
mid = partition( arr, lo, hi );
/*分情况处理,左边小于阈值*/
if ( (mid - 1 - lo) <= MAX_THRESH)
{
/* 左右两个数据段的元素都小于阈值,取出栈中数据段进行划分*/
if ( (hi - (mid+1)) <= MAX_THRESH)
/* 都小于阈值,从栈中取出数据段 */
STACK_POP (lo, hi);
else
/* 只有右边大于阈值,右边继续分区*/
lo = mid -1 ;
}
/*右边小于阈值,继续计算左边*/
else if ((hi - (mid+1)) <= MAX_THRESH)
hi = mid - 1;
/*左右两边都大于阈值,且左边大于右边,左边入栈,右边继续分区*/
else if ((mid -1 - lo) > (hi - (mid + 1)))
{
STACK_PUSH (lo, mid - 1);
lo = mid + 1;
}
/*左右两边都大于阈值,且右边大于左边,右边入栈,左边继续分区*/
else
{
STACK_PUSH (mid + 1, hi);
hi = mid -1;
}
}
}
/*最后再使用插入排序,对于接近有序状态的数据,插入排序速度很快*/
insertSort(arr,right-left+1);
}
运行结果
我们随机产生1亿个整数,并对其进行排序:
$ gcc -o qsort qsort.c
$ time ./qsort 100000000
递归版运行结果:
sort for 100000000 numbers
before sort:too much,will not print
after sort:too much,will not print
real 0m16.753s
user 0m16.623s
sys 0m0.132s非递归版结果:
sort for 100000000 numbers
before sort:too much,will not print
after sort:too much,will not print
real 0m16.556s
user 0m16.421s
sys 0m0.137s可以看到,实际上两种方法的效率差距并不是很大。至于原因,前面我们已经说过了。
总结
本文所写的示例实现与glibc的实现相比,还有很多可优化的地方,例如,本文实现仅对int类型实现了排序或交换值,如果待排序内容是其他类型,就显得力不从心,读者可参考《高级指针话题函数指针》思考如何实现对任意数据类型进行排序,。但快速排序的优化主要从以下几个方面考虑:
优化基准选择
优化小数组排序效率
优化交换次数
优化递归
优化最差情况,避免糟糕分区
元素聚合
有兴趣地也可以进一步阅读qsort源码,了解更多优化细节。
问题思考
为什么要在遇到相同元素时就进行扫描?
插入排序最好的情况时间复杂度是多少,在什么情况下出现?
文中实现的代码还有哪些可以优化的地方?
欢迎你在评论区留下你的答案!
IT大咖说 | 关于版权
感谢您对IT大咖说的热心支持!
文章推荐
推荐文章
最近活动
点击【阅读原文】更多IT技术圈干货等你挖掘
以上是关于大佬的快速排序算法,果然不一样的主要内容,如果未能解决你的问题,请参考以下文章